Author: Vivo Internet Operations Team – Hu Tao
This article introduces the practical ideas of vivo short video user access experience optimization, and briefly explains some principles behind the practice.
When we usually watch Douyin Kuaishou videos, if we swipe to a certain video screen and don’t move for a few seconds, there is a high probability that it will be swiped away. Therefore, in short video projects, the freeze of the screen will greatly affect the user experience. , the faster the launch speed, the more users can be retained.
In simple terms, the start-up speed is the time from the start of the call to the first frame on the screen, which can be roughly divided into two parts:
Time-consuming video file download
Time-consuming video decoding
This article mainly starts from the perspective of operation and maintenance troubleshooting, starts with each link of the network, and combines the specific case of vivo short video to share the optimization process with you.
Let’s sort out the next complete network request process first, taking the client perspective as an example, as shown in the following figure:

In the case of access to CDN, it can be divided into several stages:
DNS domain name resolution: Get the IP address of the server.
TCP connection established: Establish a connection with the server IP, that is, tcp three-way handshake.
TLS handshake: The client asks and verifies the server’s public key from the server, and the two parties negotiate to produce a “session key” and conduct encrypted communication.
CDN response: Distribute content resources to servers located in multiple geographic locations and return them to clients.
For the above stages, let’s talk about how the vivo short video is optimized.
When we surf the Internet, we usually use domain names instead of IP addresses, because domain names are convenient for human memory. Then what realizes this technology is DNS domain name resolution, DNS can automatically convert the domain name URL into a specific IP address.
3.1 Hierarchical relationship of domain names
Domain names in DNS areDotTo separate, such as www.server.com, where the period represents the different levelslimit. in the domain name,further to the rightThe position of the indicates its levelhigher. The root domain is at the top level, and its next level is the com top-level domain, and below that is server.com.
Therefore, the hierarchical relationship of the domain name is similar to a tree structure:
root DNS server
Top-level domain DNS server (com)
Authoritative DNS server (server.com)
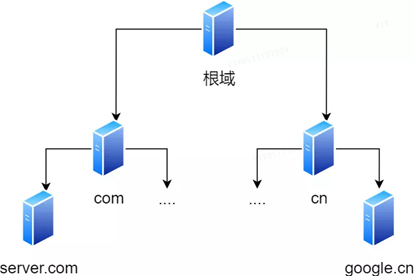
The DNS server information of the root domain is stored in all DNS servers in the Internet. This way, any DNS server can find and access the root domain DNS server.
Therefore, as long as the client can find any DNS server, it can find the root domain DNS server through it, and then find a target DNS server located in the lower layer all the way.
3.2 Workflow of domain name resolution
The browser first checks whether there is any in its own cache. If not, it asks the cache of the operating system. If not, it checks the local domain name resolution file hosts. If it still does not exist, it queries the DNS server. The query process is as follows:
The client will first send a DNS request, asking what is the IP of www.server.com, and send it to the local DNS server (that is, the DNS server address filled in the client’s TCP/IP settings).
After the local domain name server receives the request from the client, if the table in the cache can find www.server.com, it returns the IP address directly. If not, the local DNS will ask its root domain name server: “Boss, can you tell me the IP address of www.server.com?” The root domain name server is the highest level, it is not directly used for domain name resolution, but it can specify a road.
After the root DNS receives the request from the local DNS, it finds that the suffix is .com, and says: “The domain name www.server.com is managed by the .com area”, I will give you the address of the top-level domain name server of .com, and you can ask ask it. “
After the local DNS receives the address of the top-level domain name server, it initiates a request and asks “Second brother, can you tell me the IP address of www.server.com?”
The top-level domain name server said: “I will give you the address of the authoritative DNS server responsible for the www.server.com zone, and you should be able to ask it if you ask.”
The local DNS then turns to ask the authoritative DNS server: “Sir, what is the IP corresponding to www.server.com?” The authoritative DNS server of server.com is the original source of the domain name resolution results. Why is it called authority? It is my domain name and I call the shots.
The authoritative DNS server will inform the local DNS of the corresponding IP address XXXX after querying.
The local DNS then returns the IP address to the client, and the client establishes a connection with the target. At the same time, the local DNS caches the IP address, so that the next resolution of the same domain name does not need to do DNS iterative query.
So far, we have completed the DNS resolution process. Now to sum up, the whole process is drawn into a picture.
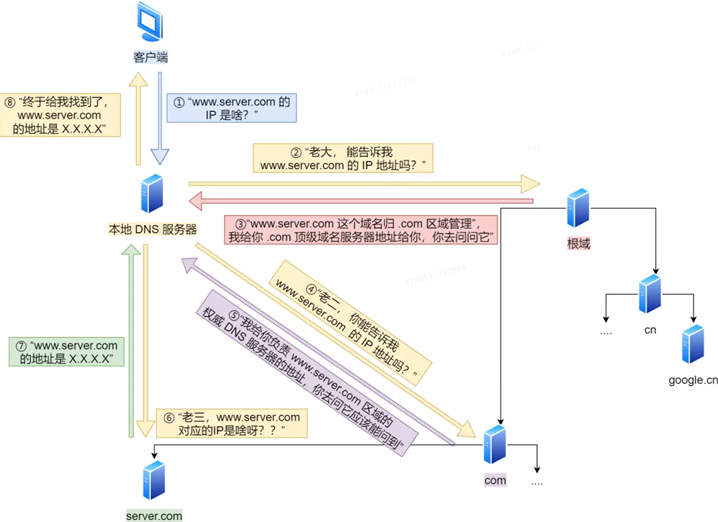
The process of DNS domain name resolution is quite interesting. The whole process is similar to the process of finding someone to ask for directions in our daily life.only pointing the way but not leading the way.
3.3 Optimization of vivo short video
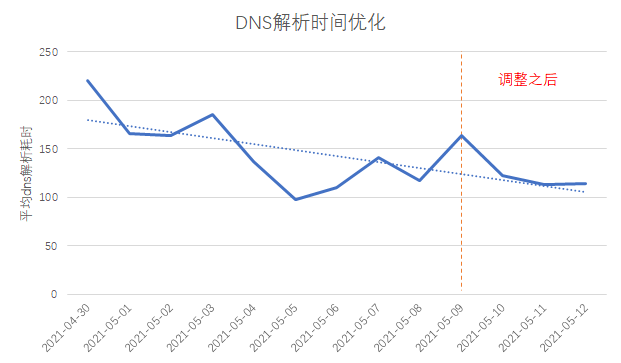
Clarified the workflow of domain name resolution, compared and analyzed the vivo domain name and the domain name of the top manufacturer, and found that the time-consuming and unstable domain name resolution of vivo short video has a large fluctuation range. It is suspected that the number of users in some areas is low, and the local DNS server It is caused by low cache hit rate, so our optimization idea is Improve local DNS cache hit rate.

As shown in the figure above, a simple way to improve the DNS cache hit rate is to add a nationwide dial-up test task to conductDNS heating.
By comparing the DNS resolution time before and after the adjustment, it can be seen that the time consumption has been reduced by about 30ms.
Here is a brief comparison of the performance of HTTP/1, HTTP/2, and HTTP/3.
The HTTP protocol is based onTCP/IPand using the “request-response“Communication mode, so the key to performance is heretwo o’clockinside.
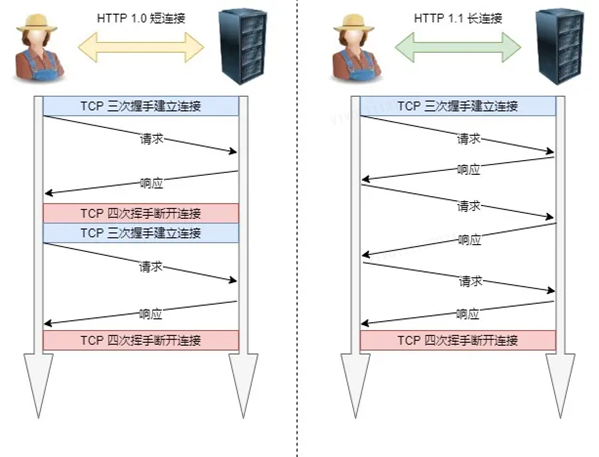
1. Long connection
A big problem in the performance of early HTTP/1.0 is that every time a request is initiated, a new TCP connection (three-way handshake) must be created, and it is a serial request, which makes unnecessary TCP connection establishment and disconnection, which increases the communication overhead.
In order to solve the above TCP connection problem, HTTP/1.1 proposedLong connectionThe communication method is also called persistent connection. The advantage of this method is that it reduces the additional overhead caused by the repeated establishment and disconnection of TCP connections, and reduces the load on the server side.
The characteristic of a persistent connection is that as long as either end does not explicitly request to disconnect, it will maintain the TCP connection state.
2. Pipeline network transmission
HTTP/1.1 adopts the long connection method, which makes pipeline network transmission possible.
That is, in the same TCP connection, the client can initiate multiple requests. As long as the first request is sent out, the second request can be sent out without waiting for it to come back.Reduce overall response time.
For example, a client needs to request two resources. The previous practice was to send A request first in the same TCP connection, then wait for the server to respond, and then send B request after receiving it. The pipeline mechanism is to allow the browser to issue A request and B request at the same time.
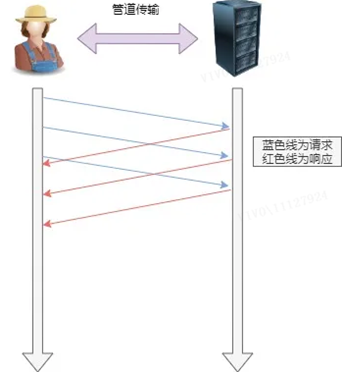
However, the server still responds to the A request in order, and then responds to the B request after completion. If the previous response is particularly slow, there will be many requests waiting in line later. This is called “head of line blocking”.
3. Head-of-line blocking
The “request-response” model exacerbates HTTP performance problems.
Because when a request in the sequentially sent request sequence is blocked for some reason, all requests queued later will also be blocked together, which will cause the client to never request data, which is “head of line blocking“.It’s like a traffic jam on the way to work.
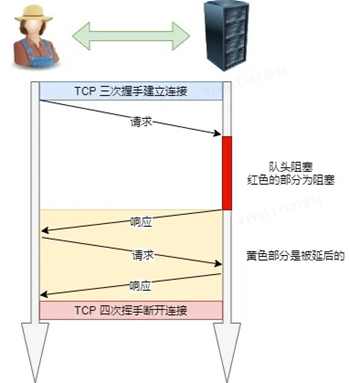
4.1 HTTP/1.1 performance improvement compared to HTTP/1.0:
The way of using TCP long connection improves the performance overhead caused by HTTP/1.0 short connection.
It supports pipeline network transmission. As long as the first request is sent out, the second request can be sent out without waiting for it to come back, which can reduce the overall response time.
But HTTP/1.1 still has performance bottlenecks:
The request/response header (Header) is sent without compression, and the more header information, the greater the delay. Only the Body part can be compressed;
Send lengthy headers. Sending the same header each time causes more waste;
The server responds in the order of requests. If the server responds slowly, the client will not be able to request data, that is, the head of the queue is blocked;
No request priority control;
Requests can only start from the client, and the server can only respond passively.
For the performance bottleneck of HTTP/1.1 above, HTTP/2 has made some optimizations. And because the HTTP/2 protocol is based on HTTPS, the security of HTTP/2 is also guaranteed.
4.2 HTTP/2 performance improvement compared to HTTP/1.1:
1. Head Compression
HTTP/2 will compress the header (Header). If you send multiple requests at the same time, and their headers are the same or similar, then the protocol will help youremove duplicates.
This is the so-called HPACK algorithm: maintain a table of header information at the same time on the client and server, all fields will be stored in this table, an index number will be generated, and the same field will not be sent in the future, only the index number will be sent, so thataccelerateup.
2. Binary format
HTTP/2 is no longer a plain text message like HTTP/1.1, but fully adoptsbinary format.
Both the header information and the data body are binary, and are collectively referred to as a frame:header frame and data frame.
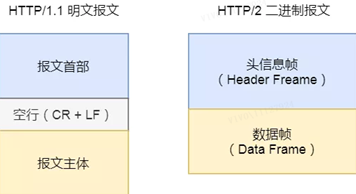
Although this is not friendly to people, it is very friendly to computers, because computers only understand binary, so after receiving the message, there is no need to convert the plaintext message into binary, but to directly parse the binary message.Increased efficiency of data transfer.
3. Data flow
HTTP/2 data packets are not sent in order, and consecutive data packets in the same connection may belong to different responses. Therefore, the packet must be marked to indicate which response it belongs to.
All data packets of each request or response are called a data stream (Stream).
Each data stream is marked with a unique number, which stipulates that the number of data streams sent by the client is odd, and the number of data streams sent by the server is even.
client is okSpecify the priority of the data stream. For requests with high priority, the server will respond to the request first.
4. Multiplexing
HTTP/2 is available onConcurrent multiple requests or responses in one connection, instead of one-to-one correspondence in sequence.
The serial request in HTTP/1.1 is removed, so there is no need to wait in line, and the problem of “head of line blocking” will no longer occur.Reduced latency and greatly improved connection utilization.
For example, in a TCP connection, the server receives two requests from clients A and B. If it finds that the processing process of A is very time-consuming, it responds to the processed part of A’s request, and then responds to B’s request. After completion , and then respond to the rest of A’s request.
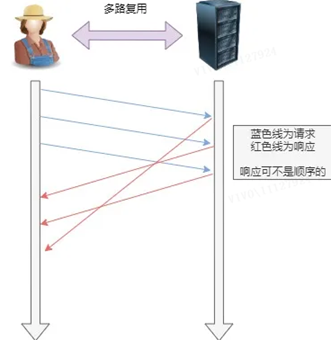
5. Server push
HTTP/2 also improves the traditional “request-response” working mode to a certain extent. The service is no longer passively responding, but can alsoinitiativeSend a message to the client.
For example, when the browser just requests HTML, it actively sends static resources such as JS and CSS files that may be used to the client in advance.Reduce latency waitingthat is, server push (Server Push, also called Cache Push).
4.3 So what are the flaws of HTTP/2? What optimizations have HTTP/3 made?
HTTP/2 greatly improves the performance of HTTP/1.1 through new features such as header compression, binary encoding, multiplexing, and server push, but the fly in the ointment is that the HTTP/2 protocol is implemented based on TCP, so there are three defects: indivual.
1. Delay in handshake between TCP and TLS
For the HTTP/1 and HTTP/2 protocols, TCP and TLS are layered, which belong to the transport layer implemented by the kernel and the presentation layer implemented by the openssl library respectively, so they are difficult to merge together and need to be handshaked in batches, first TCP handshake , and then the TLS handshake.
When initiating an HTTP request, it needs to go through the process of TCP three-way handshake and TLS four-way handshake (TLS 1.2), so it takes a total of 3 RTT delays to send the request data.
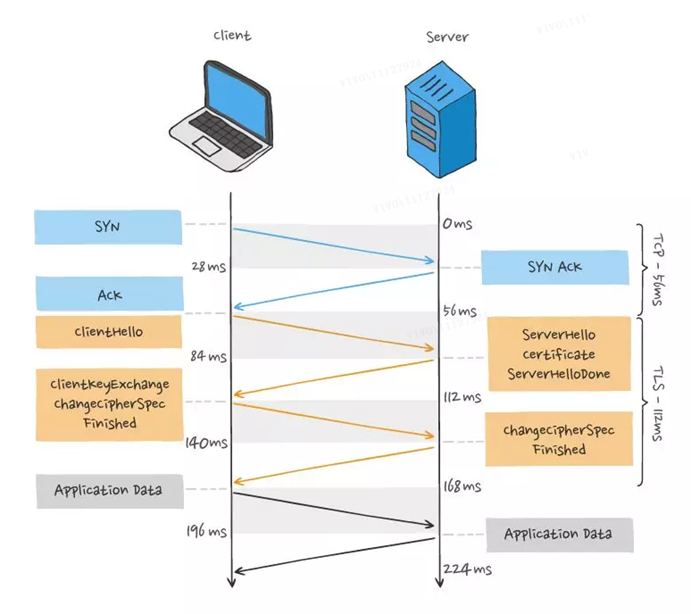
In addition, because TCP has the characteristics of “congestion control”, the TCP that has just established a connection will have a “slow start” process, which will have a “slow down” effect on the TCP connection.
2. Head-of-line blocking
HTTP/2 realizes Stream concurrency, multiple Streams only need to multiplex one TCP connection, saves TCP and TLS handshake time, and reduces the impact of TCP slow start phase on traffic. Only different Stream IDs can be concurrent, even if frames are sent out of order, there is no problem, but the frames in the same Stream must be in strict order. In addition, the priority of Stream can be set according to the rendering order of resources, thereby improving user experience.
HTTP/2 solves the problem of head-of-line blocking in HTTP/1 through the concurrency capability of Stream, which seems to be perfect, but HTTP/2 still has the problem of “head-of-line blocking”, but the problem is not at the level of HTTP. But at the TCP layer.
Multiple HTTP/2 requests run in one TCP connection, so when TCP packets are lost, the entire TCP has to wait for retransmission, and all requests in the TCP connection will be blocked.
Because TCP is a byte stream protocol, the TCP layer must ensure that the received byte data is complete and in order. If the TCP segment with a lower sequence number is lost during network transmission, even if the TCP segment with a higher sequence number has been After receiving it, the application layer cannot read this part of the data from the kernel. From the perspective of HTTP, the request is blocked.
For example, as shown below:
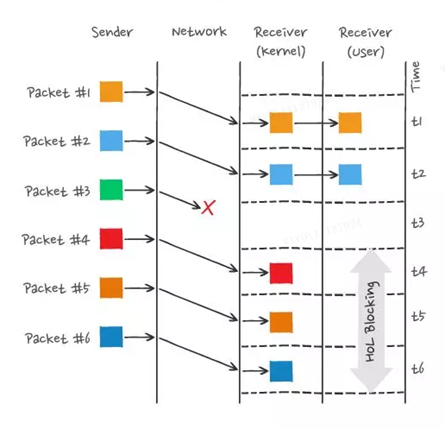
In the figure, the sender sent many packets, and each packet has its own sequence number, which can be regarded as the sequence number of TCP. Among them, packet 3 was lost in the network, even after packets 4-6 were received by the receiver, due to the kernel The TCP data in is not continuous, so the receiver’s application layer cannot read it from the kernel. Only after packet 3 is retransmitted, the receiver’s application layer can read the data from the kernel. This is HTTP/ 2, the head-of-line blocking problem occurs at the TCP level.
3. Network migration requires reconnection
A TCP connection is determined by a four-tuple (source IP address, source port, destination IP address, destination port), which means that if the IP address or port changes, it will result in a re-handshake between TCP and TLS, which is not conducive to Scenarios where mobile devices switch networks, such as switching from a 4G network environment to WIFI.
These problems are inherent in the TCP protocol, and no matter how HTTP/2 is designed at the application layer, they cannot escape.
To solve this problem, HTTP/3 replaced the transport layer protocol from TCP to UDP, and developed the QUIC protocol on the UDP protocol to ensure reliable data transmission.
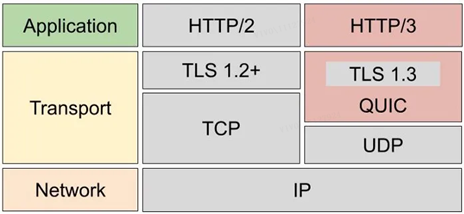
4.4 Features of QUIC protocol
no head-of-line blockingThere is no dependency between multiple Streams on the QUIC connection, they are all independent, and there will be no underlying protocol restrictions. If a packet loss occurs in a certain stream, only this stream will be affected, and other streams will not be affected;
Fast connection establishmentbecause QUIC contains TLS1.3 inside, so it only takes 1 RTT to complete the connection establishment and TLS key negotiation “simultaneously”. Even in the second connection, the application data packet can handshake information with QUIC (connection information + TLS information) to achieve the effect of 0-RTT.
connection migrationthe QUIC protocol does not use a quadruple to “bind” the connection, but to mark the two endpoints of the communication through the connection ID. The client and the server can each choose a set of IDs to mark themselves, so even if the network of the mobile device After the change, the IP address has changed. As long as the context information (such as connection ID, TLS key, etc.) is still retained, the original connection can be reused “seamlessly” to eliminate the cost of reconnection.
In addition, QPACK of HTTP/3 synchronizes the dynamic tables of both parties through two special unidirectional streams, which solves the head-of-queue blocking problem of HPACK of HTTP/2.
However, since QUIC uses the UDP transmission protocol, UDP is a “second-class citizen”. Most routers will drop UDP packets when the network is busy and give “space” to TCP packets. Therefore, the promotion of QUIC should not be difficult. So simple.Looking forward to the day when HTTP/3 is officially launched!
4.5 Optimization of vivo short video
With the development of vivo short video in different periods, we have made different optimizations:
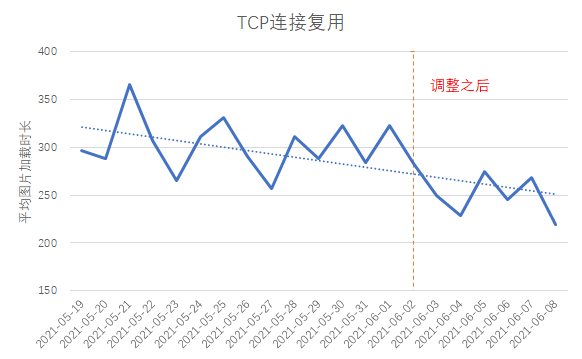
1. Use HTTP/1.1: The client merges the first frame image domain name and comment avatar domain name, the TCP link reuse rate increases by 4%, and the average image loading time decreases by about 40ms;
2. Use HTTP/2: The client uses H2 in grayscale on some domain names, and the freeze rate drops by 0.5%
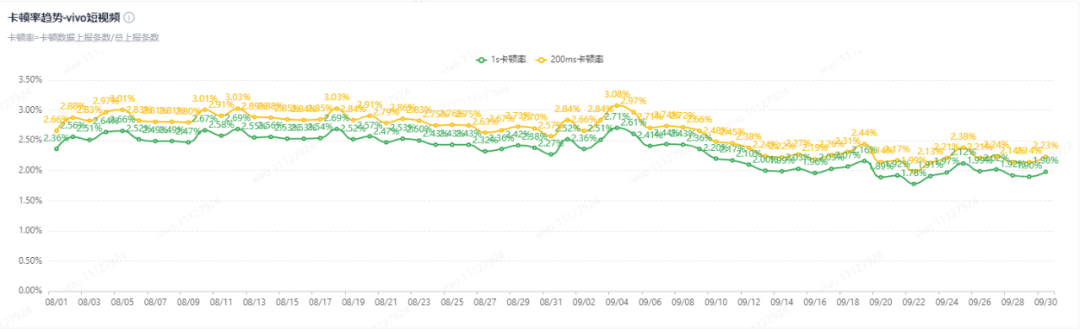
3. Using QUIC: For weak network scenarios, the client gives priority to using the QUIC protocol; at the same time, it specifically optimizes the performance of QUIC for the characteristics of short video services.
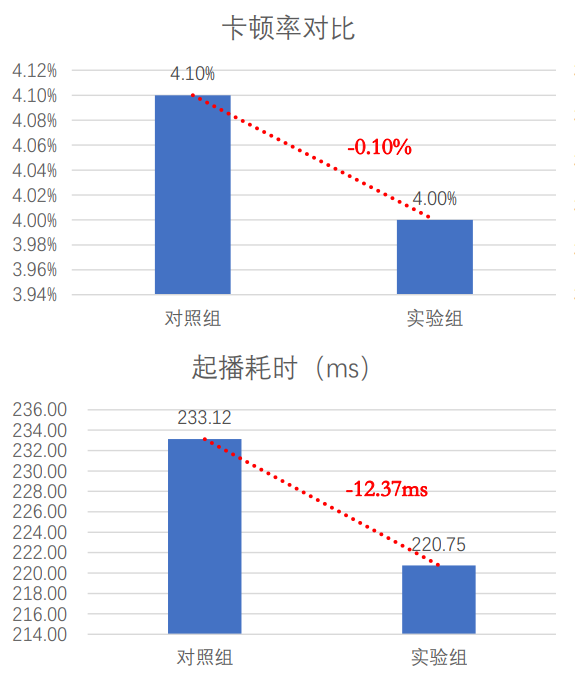
The full name of CDN is Content Delivery Network, and the Chinese name is “Content Distribution Network”. It solves the problem of slow network access due to long distances.
Simply put, CDN distributes content resources to servers located in computer rooms in multiple geographical locations, so that we do not need to visit the source server when accessing content resources. Instead, we directly access the CDN node closest to us, which saves the time cost of traveling long distances and thus achieves network acceleration.
What CDN accelerates is that content resources are static resources.
The so-called “static resource” means that the data content is static and unchanged, and the access is the same at any time, such as pictures and audio. On the contrary, “dynamic resources” means that the data content changes dynamically, and each visit is different, such as user information. However, if dynamic resources also want to be cached and accelerated, dynamic CDN must be used. One of the ways is to put the logic calculation of data on the CDN node, which is called edge computing.
There are two methods of CDN acceleration strategy, which are “push mode“and”pull mode“.
Most CDN acceleration strategies adopt the “pull mode”. When the requested data is not cached in the nearest CDN node accessed by the user, the CDN will actively download the data from the source server and update it to the cache of the CDN node. It can be seen that the pull mode is a passive caching method, and the opposite “push mode” is an active caching method. If you want to cache resources to CDN nodes before users access them, you can use “push mode”, which is also called CDN preheating. Through the API interface provided by the CDN service, submit information such as the address of the resource that needs to be preheated and the area that needs to be preheated. After the CDN receives it, it will trigger the CDN nodes in these areas to go back to the source to achieve resource preheating.
5.1 How to find the CDN node closest to the user?
Find the CDN node closest to the user by the CDN’sGlobal Load Balancer(Global Sever Load Balance, GSLB) responsible. When does GSLB work? Before answering this question, let’s take a look at what happens when accessing a domain name without a CDN. In the absence of a CDN, when we visit a domain name, the DNS server will eventually return the address of the origin server. For example, when we enter the www.server.com domain name in the browser and cannot find the domain name in the local host file, the client will access the local DNS server.
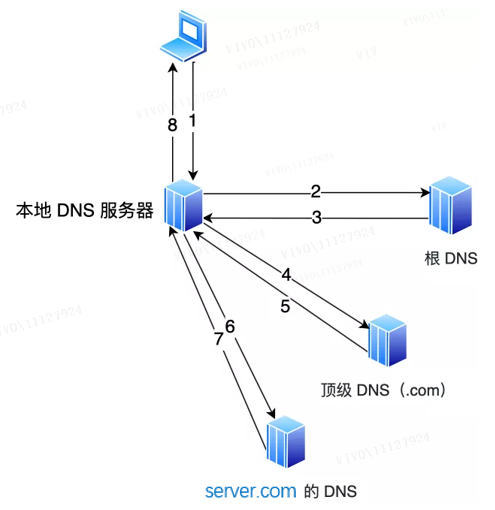
At this moment:
If the local DNS server has cached the address of the website, it will directly return the address of the website;
If not, use the recursive query method to first request the root DNS, and the root DNS returns the address of the top-level DNS (.com); then request the top-level DNS of .com to get the address of the domain name server of server.com, and then obtain the address of the domain name server of server.com Query the IP address corresponding to www.server.com, and then return this IP address. At the same time, the local DNS caches the IP address, so that the next resolution of the same domain name does not need to do DNS iterative query.
But it is different after joining CDN.
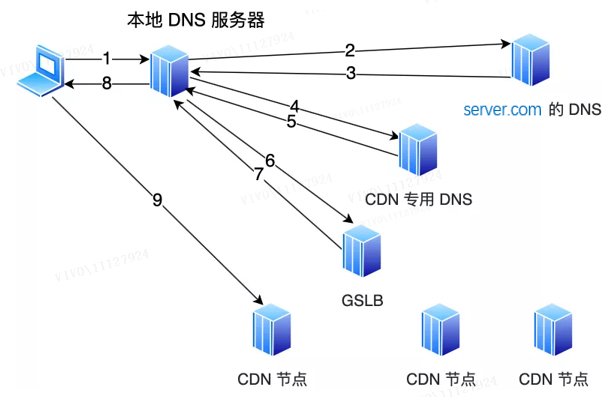
A CNAME alias will be set on the DNS server server.com, pointing to another domain name www.server.cdn.com, and returned to the local DNS server. Then continue to resolve the domain name. At this time, the server.cdn.com is the DNS server dedicated to the CDN. On this server, a CNAME will be set to point to another domain name. This time it will point to the GSLB of the CDN. Next, the local DNS server requests the domain name of the GSLB of the CDN, and GSLB will select a suitable CDN node to provide services for the user. The selection basis mainly includes the following points:
Look at the user’s IP address, look up the table to know the geographical location, and find the relatively nearest CDN node;
Look at the operator network where the user is located, and find the CDN node of the same network;
Look at the URL requested by the user to determine which server has the resource requested by the user;
Query the load status of CDN nodes and find nodes with lighter loads.
GSLB will conduct a comprehensive analysis based on the above conditions, find out the most suitable CDN node, and return the IP address of the CDN node to the local DNS server, and then the local DNS server will cache the IP address and return the IP to the client , the client accesses this CDN node and downloads resources.
5.2 Optimization of vivo short video
After our analysis, we found that some domain names connected to the CDN are not accessed nearby in some provinces across the country, and the problem of cross-regional coverage of CDN edge nodes is relatively serious. So we asked the CDN manufacturer to make targeted adjustments. After the adjustment, the average request time consumption was reduced to about 300ms, and the first packet time consumption was also reduced to more than 100ms.
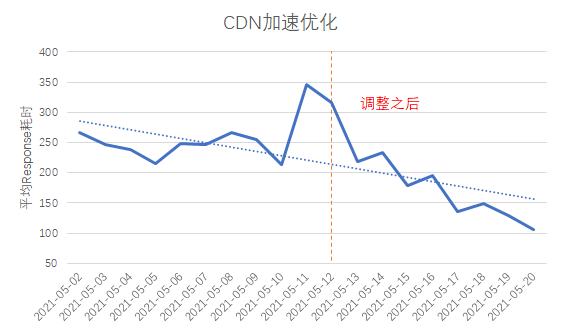
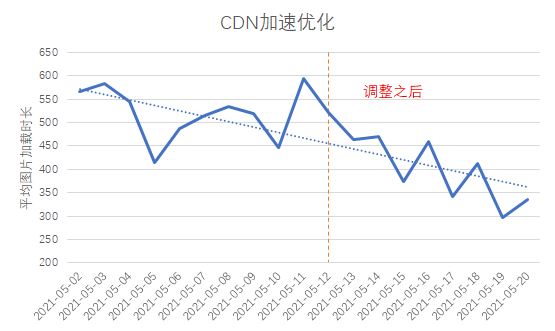
With the development of business, improving user experience will become more and more important. User access experience optimization will be an endless process. In addition to the methods mentioned above, there are also some optimizations we have tried. for example:
connection optimization: Sliding up and down during video playback will frequently disconnect the connection, and the connection cannot be reused.
pre-cache file: Reduce startup time.
content optimization: Reduce file transfer size.
I hope this article can help you optimize user access experience in your daily work.
#Vivo #short #video #user #access #experience #optimization #practice #vivo #Internet #Technology #News Fast Delivery