Rate limiter is a very basic network packet processing function, which is widely used in various network element devices and plays an important role in traffic scheduling, network security and other fields. Common rate limiters are implemented based on token buckets. Although the principle of token buckets is well known, we have also found some challenges and common problems in practice. This article summarizes some explorations of the Bytedance System and Technology Engineering Team (referred to as the STE team) in the optimization of speed limiters in the past two years, and summarizes some experiences and lessons for readers.
Basic Principles of Token Bucket Rate Limiter
I believe that every engineer who writes network packet processing has written a basic token bucket speed limiter. The token bucket is a vivid description. It can be imagined that there is a bucket that can hold a certain amount of tokens. Every time a data packet is released, a certain amount of tokens will be consumed. Whether the data packet is released or not depends on the token bucket. The number of tokens in .

Figure 1 Diagram of token bucket
For example, if the token bucket limit is PPS (Packet Per Second), assume that a token represents a data packet. Then a speed limiter that limits PPS to 300K/s will generate 300K tokens per second. Any data packet passing through this rate limiter will consume a token, and if the token is consumed to 0, the packet will be discarded.
suppose \(P_t \) Indicates that the arrival time is \(t\) data packets, the time of an elapsed data packet on the token bucket is \(t’ \) then during this period, the number of tokens generated by the token bucket is:
\((t – t’) * rate\)
The number of remaining token buckets in the token bucket is\(T\) then when \(P_t \) Upon arrival, the tokens in the token bucket are:
\((t – t’) * rate + T\)
The token bucket has a capacity, the value of the above formula may exceed the capacity of the token bucket, assuming the capacity of the token bucket is \(Burst \) if the value calculated above exceeds this limit, the number of tokens is equal to\(Burst \) .
At this time because the packet \(P_t\) To pass, one token should be consumed, so the timestamp of updating the token bucket is \(t’ \) And update the number of tokens in the token bucket according to the above calculation. If it is found through calculation that the number of tokens generated exceeds the consumption, then the data packet is released; if not, the data packet needs to be discarded.
Some people may wonder why the capacity of the token bucket is limited, and why the largest capacity is named \(Burst\) , this is actually because the token bucket actually allows the rate to exceed the limit value within a specific time window.Take the 300Kpps speed limiter as an example, assuming \(Burst\) It is equal to 300K, and the current token bucket is full. At this time, even if 300K packets come within 100ms, the token bucket will release all data packets (because the number of tokens in the token bucket is sufficient), and In this 100ms, the actual rate is not 300Kpps, but 3Mpps. As the name implies, the capacity of the token bucket actually limits its allowed burst rate.
In practice, the token bucket has the characteristics of simple implementation and high efficiency. In many scenarios, the speed limiter is basically synonymous with the token bucket.
existing problems
During the specific project time, we encountered the following three problems:
1. Accuracy problem
In actual engineering practice, the time measurement unit is actually limited by the system. For example, the time stamp may be in microseconds (us), and the time difference between each calculation may only be 1~2us. Then a speed limiter with PPS=300K may be calculated at one time, and the tokens generated are 0.3, which is easily ignored by integer operations. The final result is that the actual limit is 300K/s, and the final effect is that only 250Kpps traffic is allowed. The accuracy is too low and the effect is not ideal.
This solution is also relatively simple, and the amount of tokens consumed by a data packet can be not 1, but 1000. In this way, even if it is 1us, the number of tokens generated by the token bucket is 300 instead of 0.3, which ensures the accuracy. But at this time, a new problem is introduced, because the number of tokens has increased by 1000 times, and it is necessary to consider whether the depth of the token bucket will overflow 32bit. Once overflowed, other weird problems will appear.
2. Cascade compensation problem

Figure 2 Speed limiter cascade compensation
We have found in practice that when multiple speed limiters are cascaded, compensation tokens are required. For example, for speed limiter A, this packet is released and consumes A’s token. For rate limiter B, this packet is discarded because B has no token. At this point the packet is lost. Then A’s token is consumed in vain at this time, that is, the token is consumed, and the packet is still lost. To achieve an accurate speed limit effect, the token of speed limiter A should be compensated. As shown in Figure 2.
Cascading compensation makes multiple speed limiters coupled with each other, and it is more troublesome in code writing. We found in practice that if the speed limit values of speed limiter A and speed limiter B are close, and both have packet loss, the lack of cascade compensation will have a serious impact on the accuracy. But if the speed limit value is far away, the impact on accuracy is not that great.
3. TCP is sensitive to packet loss
There is no cache in the token bucket. Once the rate exceeds the limit value, packet loss will occur. The TCP protocol is very sensitive to packet loss. Once packet loss occurs, TCP adjusts the rate more aggressively. The feature of the token bucket makes it often limit 100Mbps when it is applied to TCP traffic. In fact, it can only run to 80Mbps at most, because the constant packet loss causes TCP to continuously reduce the sending window.
When vSwitch is used, the BPS (Bits Per Second) rate limit has a particularly large loss on TCP. This is because the general virtual network card has enabled TSO (TCP Segmentation Offload) optimization. When TSO is enabled, the TCP sent by the host The packets are very large, and a packet may be 64K bytes. In such a large case, if you lose a few packets at will, the impact on the TCP rate will be very obvious.
First Improvement: Port Lending Backpressure Speed Limiter
We have found in practice that although the cascade compensation feedback problem exists, it is not very prominent. The reason is that the speed limit value of the general cascade speed limiter is very different. For example, the speed of a single network card and the speed of the whole machine generally have a large gap. It is not easy to have precision problems. The most serious problem is that the rate-limited bandwidth cannot be reached due to sensitivity to TCP packet loss, which affects user experience. As shown in Figure 3, with the increase of TCP RTT, the actual achievable bandwidth will decrease obviously.
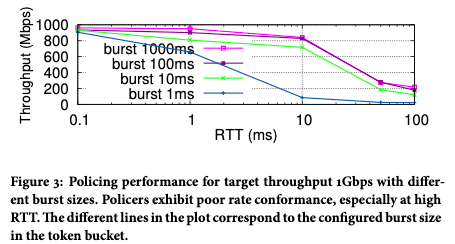
Figure 3 After the traffic passes through the 1Gbps rate limiter, the actual rate obtained
Backpressure is an improvement on the problem that TCP is sensitive to packet loss. When we first designed, we actually aimed at a specific scene. The speed of the virtual network card of the virtual machine is limited. And our rate limiter happens to be that each network card has a specific rate limiter.
Each virtual network card has several queues, and vSwitch will continuously poll these queues to get data packets to send. These queues are essentially buffers for packets. Back pressure, in fact, is to stop or delay the polling of these queues, let the data packets accumulate on the queues, and achieve the purpose of feeding back the pressure to the Guest Kernel, so that the TCP stack of the Guest Kernel will sense congestion and adjust the sending Rhythm.
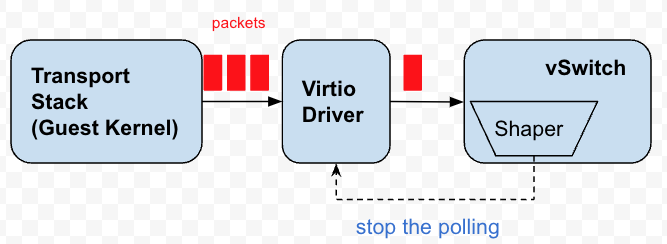
Figure 4 Back pressure speed limiter
When we designed the back pressure speed limiter, there was a limitation that affected the final implementation:
The virtual network card of the virtual machine does not provide the Peek function, that is, the vSwitch only Peeks the data packet, but does not actually take the data packet out of the queue. This limitation led us to use the idea of ”borrowing”. Both set a permission time point to start polling. If the current time exceeds the permission time point, all the data packets in the queue will be sent out at once, regardless of whether the token is enough. If the token is enough, there is no problem, but when the token If it is not enough, then consider borrowing a token from the future, and reversely calculate a future timestamp, then before this timestamp, the vSwitch stops polling the virtual network card.
The loan method was proposed at the beginning only for performance considerations, so as to avoid copying the data packets from the virtual machine queue, but found that the tokens were not enough and had to be discarded. Since I don’t want to discard it, I simply send out a token to the future.
Looking back at this design now, compared with Peek, there are actually advantages and disadvantages:
1) The amount of tokens borrowed each time is uncontrollable. This can lead to fairness issues. Elephant streams will continue to obtain loan qualifications, while small streams will tend to starve to death. In the speed limiter competition, if one party gains an advantage, the dominant party will easily continue to gain an advantage.
2) Simple timestamp comparison with lower overhead than peek. If you can peek data packets, there will be no loan mechanism, and there is no possibility to stop polling. Instead, you will go to the virtual queue to check every time, but the overhead is a bit high.
3) Conversely, if there is a peek function, you can also look at the backlog of data packets in the queue first, and wait for the queue to accumulate a certain amount of data packets, then calculate the timestamp for sending the next batch of data packets. Stop polling. This is good for increasing the batch to improve performance.
Because the backpressure rate limiter backpressures the network card queue of the virtual machine, it can only limit the outgoing data packets of the virtual machine, but cannot limit the traffic of the virtual machine in the receiving direction. This is because we cannot back-pressure the data packets of the physical network card. The data packets of the physical network card may be sent to different virtual network cards. The speed limit value of each network card is different. We cannot calculate an exact time point. There is no need to poll packets before the time point. Moreover, when the queue of the physical network card is full, only packets will be lost, and when the queue of the virtual machine network card is full, it can backpressure the TCP protocol stack. The effects of the two are different.
Therefore, in terms of inbound traffic restrictions, we just continue the idea of allowing timestamps. If the current time exceeds the allowed time, all packets are released, and if not, all packets are discarded.
The second improvement: Carousel speed limiter
Carousel speed limiter is a speed limiter algorithm proposed by Google in the paper on SIGCOMM 17′[2]in fact, the idea is also very simple, that is, to calculate a sent timestamp for each data packet, if the current timestamp is less than the sent timestamp, it will be cached in a time round, that is, instead of packet loss, the data packet will be delayed .
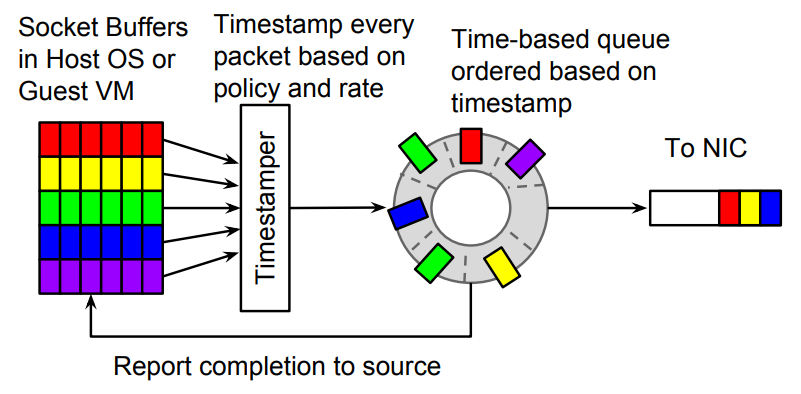
Figure 5 Carousel speed limiter
Based on the basic principle of this algorithm, we implemented a similar speed limiter in OVS-DPDK. There are many details in the process that determine the parameters of the algorithm. For example, is the time granularity of a poll 1us or 10us? What is the speed range of the actually used speed limiter? Is it 300Kpps or 3Mpps? These directly determine the parameter settings of the algorithm, and many details will not be explained.
One of the biggest benefits of Carousel is the introduction of caching. The essence of the time wheel is a cache, which has obvious benefits for TCP traffic. At the same time, the time wheel also solves the problem that the inbound traffic of the virtual machine cannot be backpressured, so that all traffic can be unified under one time wheel. The third benefit, which may be a bit unexpected, is that it eliminates the need for cascading compensation to a certain extent, because the data packets are not lost, but delayed. In the absence of packet loss, cascaded compensation is not required.
The figure below shows the comparison effect of using the old back pressure speed limiter and the new Carousel speed limiter under the speed limit of 10Gbps, using the iperf tool to test the in and out direction of the virtual machine for 100s.
The horizontal axis is time (s), and the vertical axis is throughput (Gbps), that is, the current throughput performance reported by iperf per second. It can be seen that the inbound traffic has increased by 500Mbps. Much closer to 10Gbps.
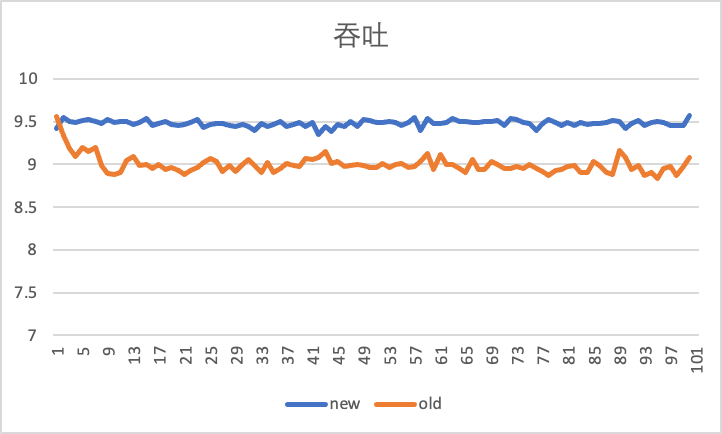
Outbound throughput performance, it can be seen that the Carousel rate limiter is more stable:

The source of these improvements comes from the smoothing effect of caching on TCP traffic.
Future Improvements and Summary
1. Further improvement
Based on the back-pressure speed limit of the loan mechanism, when the speed limit value is large, the impact of the oversent data packets due to the loan on the entire speed limit jitter is limited. For example, if the speed limit is 1G, if a few packets are oversent at a certain moment, the impact on the jitter of the speed limit is relatively small. However, if the speed limit value is small, such as 5Mbps, the impact of oversending several data packets will be relatively large. At this time, controlling the polling of the virtual machine port through the timestamp will bring about an ON-OFF effect. From the perspective of the virtual machine, there seems to be a gate on the path of outbound traffic, which will be opened for a while and closed for a while.
But this is only what you see from the perspective of the sending end of the virtual machine. Because of the adjustment of the time wheel at the receiving end, the rate will be relatively stable. In order to bring a relatively stable experience on the sending end, it is necessary to refine the effect of back pressure to reduce the chance of oversending.
In addition, the speed limit based on the port granularity can be realized by polling the control port, but for the speed limit whose granularity is smaller than the port, it is not easy to realize the back pressure. In order to achieve more fine-grained back pressure, Google in the paper PicNIC[3] Among them, on top of Carousel, virtio supports OOO completion (out-of-order completion) to achieve finer-grained backpressure, which provides ideas for further optimizing the speed limiter.
2. Active speed limit (based on ECN or modify TCP window option)
We can track and modify the TCP Window in the vSwitch, and negotiate a small window to obtain a more stable TCP throughput. At the same time, the ECN mark can also be sensed in the vSwitch, which is directly or indirectly fed back to the inside of the virtual machine, or affects the polling frequency of the vSwitch.
3. Improved lock mechanism
All of the above speed limiter improvements are aimed at the network. Due to the existence of multi-core in the system, the granularity of the speed limiter often spans threads. How to design a lock-free speed limiter is also a direction worth exploring.
4. Summary
It can be seen from the improvement history of the speed limiter that the current algorithm has become more and more relevant to the actual scene. Algorithms are no longer just an independent component, but are more and more tightly coupled with the actual operating system and product features.
references
[1] Traffic policing in eBPF: applying token bucket algorithm
[2] Carousel: Scalable Traffic Shaping at End Hosts, SIGCOMM 2017.
[3] PicNIC: Predictable Virtualized NIC, SIGCOMM 2019
#Exploration #optimization #practice #speed #limiter #ByteDance #SYS #Techs #personal #space #News Fast Delivery