MindRec is the high-performance acceleration library of Shengsi MindSpore in the recommendation field. It provides an efficient integrated training and recommendation solution and process guidance for AI models in the recommendation field.
MindRec is based on MindSporeautomatic parallelization,Graph Computing Fusionand other basic technical capabilities, adding a distributed multi-level feature cache to supportTB-level recommendation modelTraining reasoning, based on Hash structuredynamic featuresexpression to support dynamic entry and exit of runtime features,Online LearningTo support special scenarios in the recommended field such as real-time update of minute-level models, it also provides out-of-the-box data set download and conversion tools, model training samples, typical model benchmarks, etc., providing users with a one-stop solution plan.
Feature introduction
Three major problems facing the field of recommendation in engineering practice encompass the ever-increasingmodel size,charactermaticDynamic changesand the updated modelreal-timeMindRec provides corresponding solutions for each scenario.
I. Recommended Large Models
Released from 2016Wide&DeepFrom the model and its various subsequent improvements, it can be learned that the size of the recommendation model mainly depends on the size of the feature vector in the model. With the continuous development of the recommendation business scale in the industry, the size of the model has also rapidly exceeded hundreds of GB, and even reached Therefore, a high-performance distributed architecture is required to solve the problems of storage, training and reasoning of large-scale feature vectors.According to the difference in model size, MindRec provides three training programs, namelysingle card training,hybrid parallelas well asHierarchical feature cache.
1) Single card training
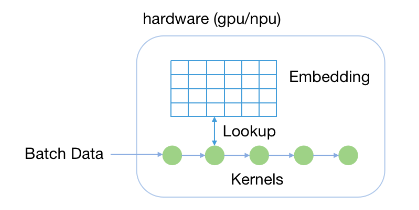
Single card training modeThe calculation method is the same as that of ordinary neural network models. A GPU or NPU accelerator card can be used to load a complete model and perform training or inference. This mode is suitable for network models (especially feature tables) that are smaller than the memory capacity of the accelerator card (such as Nvidia GPU V100 32GB video memory), the performance of training and inference is the best.
2) Multi-card mixed parallel
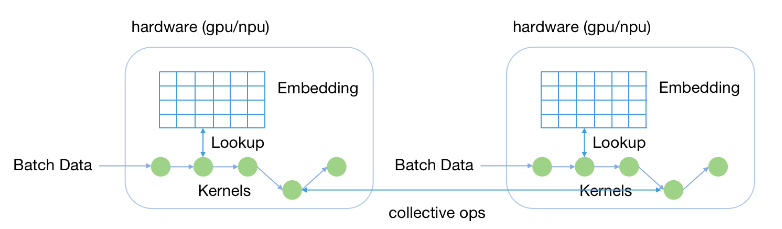
Hybrid Parallel ModeIt is a distributed version of single-card training that supports multi-machine and multi-card parallel training to further improve model size and training throughput. In this mode, the part of the feature table in the model is segmented and stored in the video memory of multiple accelerator cards through model parallelism, while the rest of the model is completed through data parallelism. The hybrid parallel mode is suitable for situations where the model size exceeds the memory capacity of a single accelerator card.
3) Distributed Feature Cache
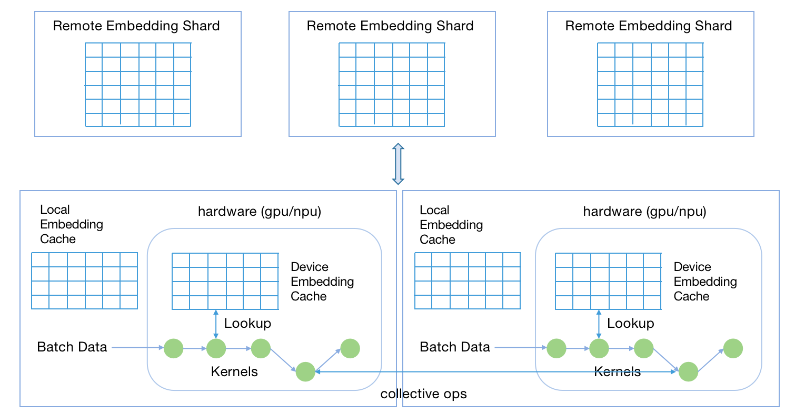
Distributed Feature CacheIt is suitable for scenarios of super-large-scale recommendation network models (such as terabyte-level feature vectors). This model is based on hybrid parallelism. The feature vector is extended to a larger range of distributed storage through layer-by-layer storage separation, so that the scale of the model can be easily expanded without changing the calculation scale, and the training of a single accelerator card for a TB-level model can be realized.
II. Hash dynamic characteristics
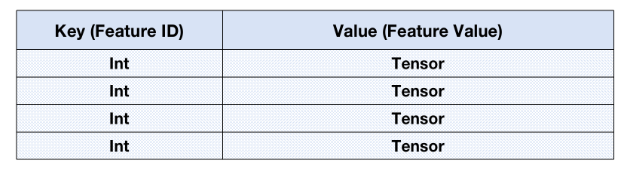
For scenarios where features change over time (added or eliminated) during training, feature vectors are more suitable for storage and calculation using the Hash structure in expression. In MindRec, you can use the nameMapParameterThe data type expresses a Hash type. The logical data structure and sample code are as follows:
import mindspore as ms import mindspore.nn as nn import mindspore.context as context from mindspore.common.initializer import One from mindspore.experimental import MapParameter from mindspore import context, Tensor, Parameter context.set_context(mode=context.GRAPH_MODE, device_target="GPU") # Define the network. class DemoNet(nn.Cell): def __init__(self): nn.Cell.__init__(self) self.map = MapParameter( name="HashEmbeddingTable", # The name of this hash. key_dtype=ms.int32, # The data type of the key. value_dtype=ms.float32, # The data type of the value. value_shape=(128), # The shape of the value. default_value="normal", # The default values. permit_filter_value=1, # The threshold(the number of training step) for new features. evict_filter_value=1000 # The threshold(the number of training step) for feature elimination. ) def construct(self, key, val): # Insert a key-val pair. self.map[key] = val # Lookup a value. val2 = self.map[key] # Delete a key-val pair. self.map.erase(key) return val2 # Execute the network. net = DemoNet() key = Tensor([1, 2], dtype=ms.int32) val = Tensor(shape=(2, 128), dtype=ms.float32, init=One()) out = net(key, val) print(out)
III. Online Learning
Another concern in the recommendation system is how to incrementally train and update the model online based on the user’s real-time behavior data. The online learning process supported by MindRec is shown in the figure below. The entire pipeline is divided into four stages:
1) Real-time data writing: Incremental behavioral data is written to the data pipeline (such as Kafka) in real time. 2) Real-time feature engineering: Through the real-time data processing capabilities provided by MindPandas, feature engineering is completed and training data is written into distributed storage. 3) Online incremental training: MindData inputs incremental training data from the distributed storage into MindSpore’s online training module to complete the training and export the incremental model. 4) Incremental model update: The incremental model is imported into the MindSpore reasoning module to complete the real-time update of the model.
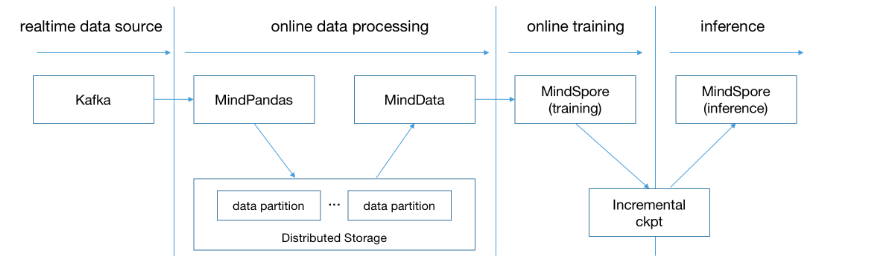
The development of the above four stages can be realized through MindSpore and MindRec ecological components and Python expression, without the need of a third-party system. The sample code is as follows (the Kafka service needs to be built and started in advance), and the detailed steps can be found inOnline LearningGuidance documents:
from mindpandas.channel import DataReceiver from mindspore_rec import RecModel as Model # Prepare the realtime dataset. receiver = DataReceiver(address=config.address, namespace=config.namespace, dataset_name=config.dataset_name, shard_id=0) stream_dataset = StreamingDataset(receiver) dataset = ds.GeneratorDataset(stream_dataset, column_names=["id", "weight", "label"]) dataset = dataset.batch(config.batch_size) # Create the RecModel. train_net, _ = GetWideDeepNet(config) train_net.set_train() model = Model(train_net) # Configure the policy for model export. ckpt_config = CheckpointConfig(save_checkpoint_steps=100, keep_checkpoint_max=5) ckpt_cb = ModelCheckpoint(prefix="train", directory="./ckpt", config=ckpt_config) # Start the online training process. model.online_train(dataset, callbacks=[TimeMonitor(1), callback, ckpt_cb], dataset_sink_mode=True)
#MindRec #Homepage #Documentation #Downloads #High #Performance #Acceleration #Library #Recommendation #Field #News Fast Delivery