Turbopilot is an open source large language model based code completion engine that runs natively on the CPU.
Specifically, TurboPilot is a self-hosted GitHub copilot clone that uses the library behind llama.cpp to run a 6 billion parameter Salesforce Codegen model in 4GiB of RAM. It is heavily based on and inspired by the fauxpilot project.
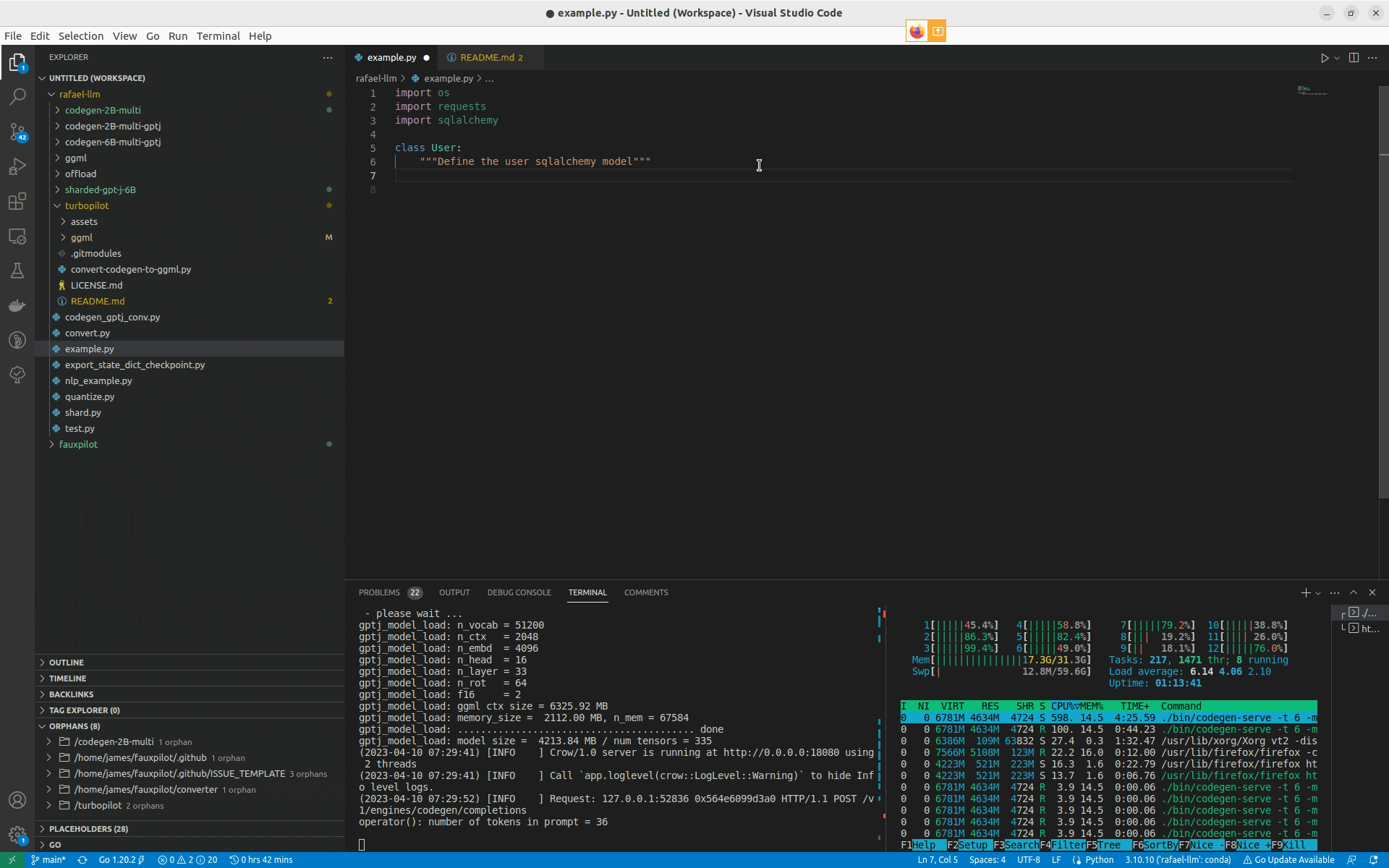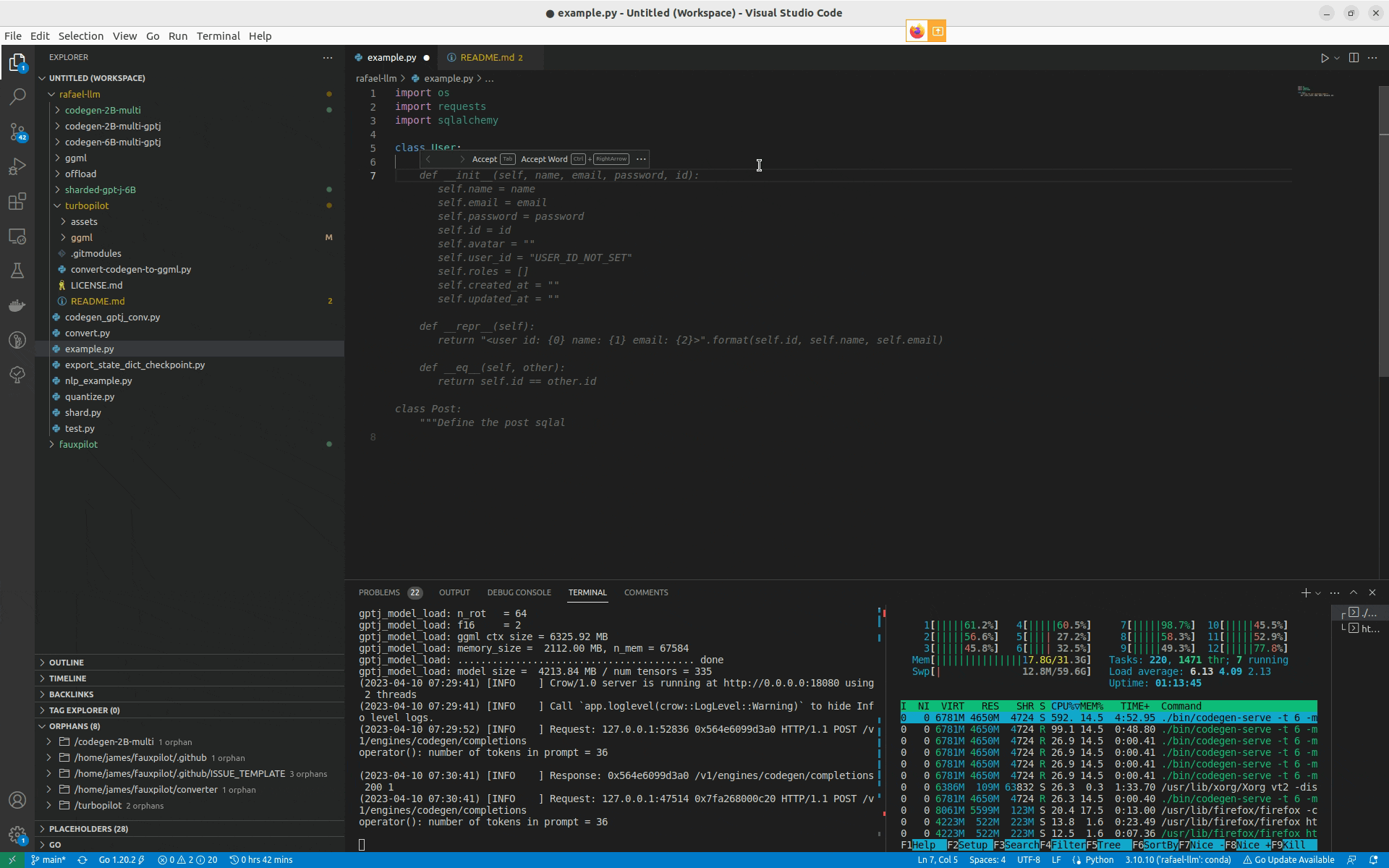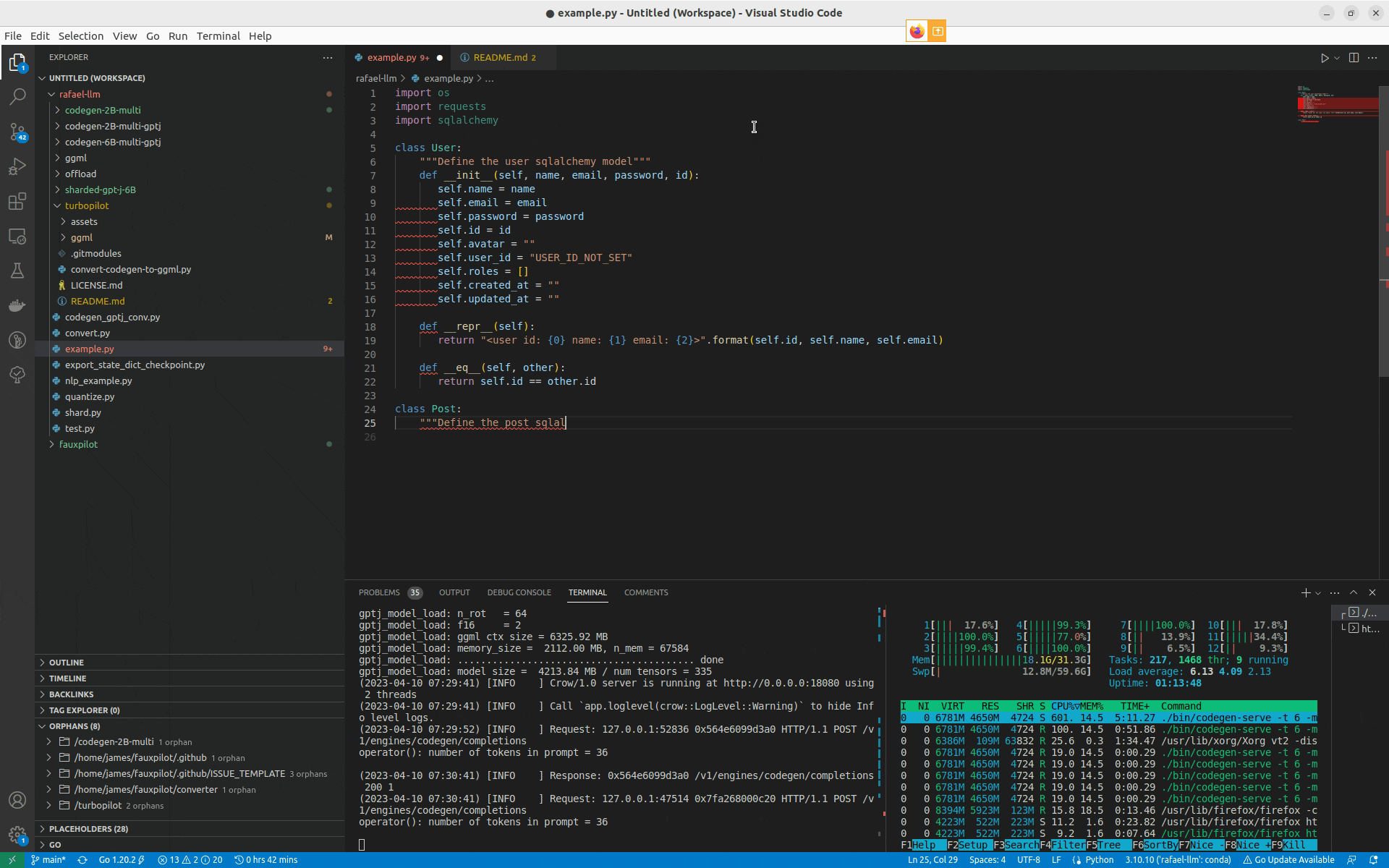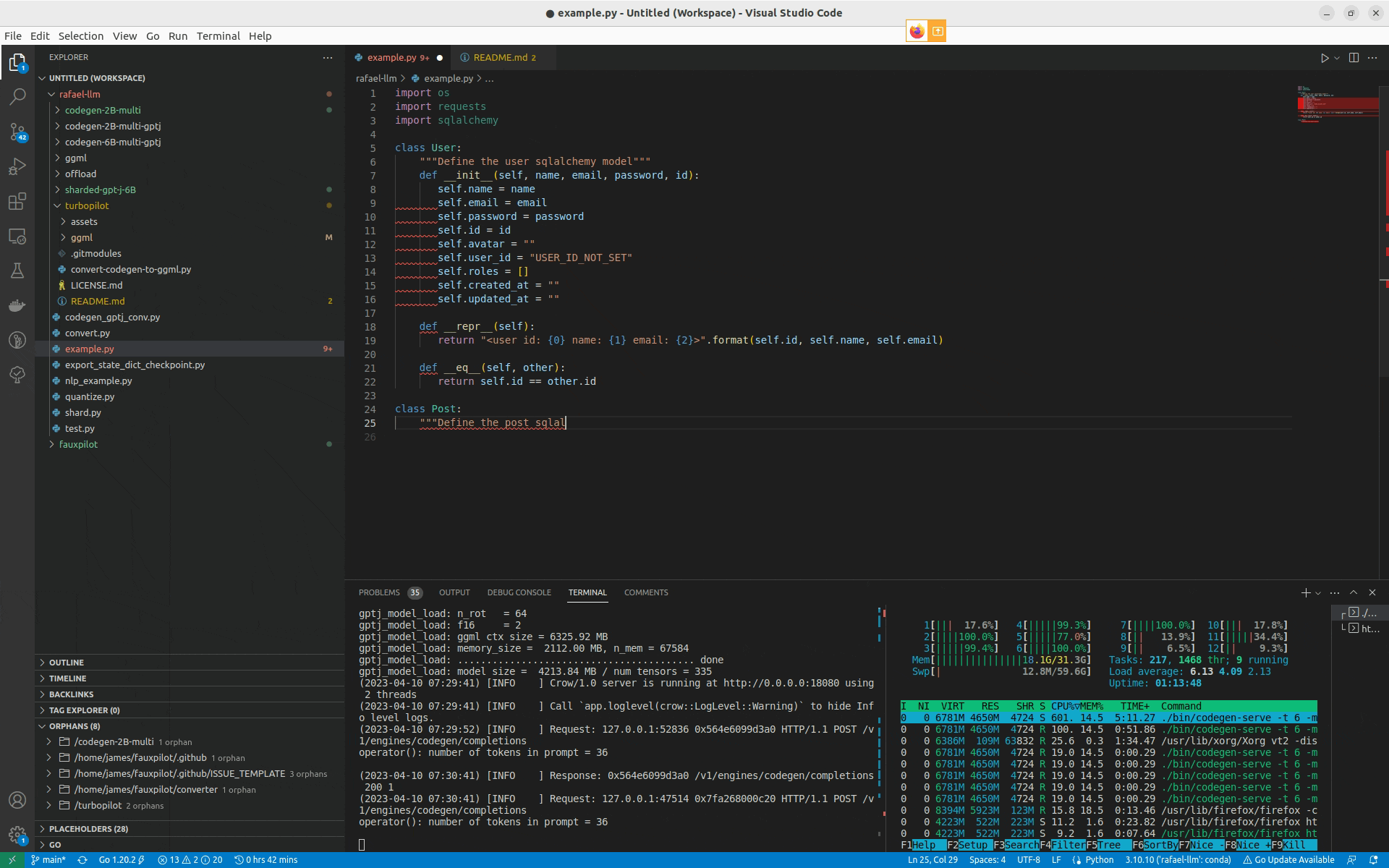
NOTE: The project is in a proof-of-concept stage, not a stable tool. In this version of the project, autocompletion is very slow.
start
The easiest way to try the project is to get the preprocessed model and run the server in docker.
get model
There are 2 options to get the model
Option A: Direct Download – Simple, Quick Start
Pre-transformed, pre-quantized models can be downloaded from Google Drive.The project team produced a 350M, 2B and 6B parameters multi Flavor Models – These models are in the C , C++ , Go , Java , JavaScript and Python pre-trained on
Option B: Convert the model yourself – difficult, more flexible
If you want to try quantizing the model yourself, followthis guide.
Running TurboPilot Server
Download the latest binaries and extract them to the root project folder.
run
./codegen-serve -m ./models/codegen-6B-multi-ggml-4bit-quant.binThe application should be on port 18080 start the server on
If you have a multi-core system, you can control how many CPUs are used with the -t option
./codegen-serve -t 6 -m ./models/codegen-6B-multi-ggml-4bit-quant.binRun from Docker
Canfrom hereThe provided pre-built docker image runs Turbopilot
The models still need to be downloaded separately, then you can run:
docker run --rm -it \
-v ./models:/models \
-e THREADS=6 \
-e MODEL="/models/codegen-2B-multi-ggml-4bit-quant.bin" \
-p 18080:18080 \
ghcr.io/ravenscroftj/turbopilot:latestYou still need to download the model separately, then run:
docker run --rm -it \
-v ./models:/models \
-e THREADS=6 \
-e MODEL="/models/codegen-2B-multi-ggml-4bit-quant.bin" \
-p 18080:18080 \
ghcr.io/ravenscroftj/turbopilot:latestuse the API
Using the API with the FauxPilot plugin
To use the API from VSCode, the vscode-fauxpilot plugin is recommended. After installation, you need to change some settings in the settings.json file.
- Open Settings (CTRL/CMD + SHIFT + P) and select Preferences: Open User Settings (JSON)
- Add the following values:
{
... // other settings
"fauxpilot.enabled": true,
"fauxpilot.server": "http://localhost:18080/v1/engines",
}The fauxpilot can be enabled using CTRL + SHIFT + P and selecting Enable Fauxpilot
When completing, the plugin sends API calls to the running codegen-serve process. It will then wait for each request to complete before sending further requests.
Call the API directly
can to http://localhost:18080/v1/engines/codegen/completions Make a request and it behaves just like the same Copilot endpoint.
For example:
curl --request POST \
--url http://localhost:18080/v1/engines/codegen/completions \
--header 'Content-Type: application/json' \
--data '{
"model": "codegen",
"prompt": "def main():",
"max_tokens": 100
}'known limitations
Since v0.0.2:
- These models can be very slow – especially the 6B model. Making recommendations across 4 CPU cores can take about 30-40 seconds.
- The system has only been tested on Ubuntu 22.04, but ARM docker images are now available, and ARM binary releases will be available soon.
- Sometimes completion suggestions are truncated where they don’t make sense – for example by variable names or parts of string names. This is due to a hard limit of 2048 on the context length (hints + suggestions).
#TurboPilot #Homepage #Documentation #Download #Code #Completion #Engine #News Fast Delivery