In the field of natural language processing, the pre-trained language model (Pre-trained Language Model, PLM) has become an important basic technology, and the use of pre-trained models is becoming more and more common in multilingual research. In order to promote the research and development of Chinese minority language information processing,Harbin Institute of Technology Xunfei Joint Laboratory (HFL)Release minority language pre-training modelCINO (Chinese mINOrity PLM).
Chinese LERT | Chinese and English PERT | Chinese MacBERT | ChineseELECTRA | Chinese XLNet | Chinese BERT | Knowledge distillation tool TextBrewer | Model cropping tool TextPruner
The main contributions of this work:
-
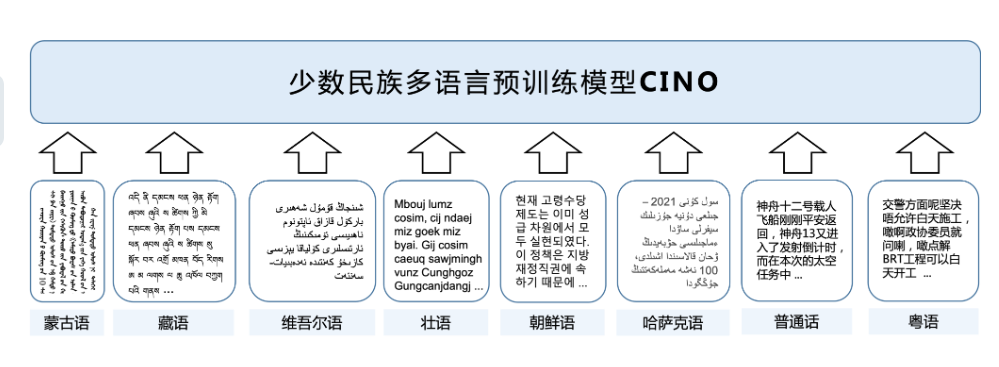
CINO (Chinese mINOrity PLM) based on multilingual pre-training modelXLM-R, and conducted secondary pre-training on a variety of domestic minority language corpora. The model provides the ability to understand minority languages and dialects such as Tibetan, Mongolian (Uyghur), Uyghur, Kazakh (Arabic), Korean, Zhuang, and Cantonese.
-
In order to facilitate the evaluation of the performance of various multilingual pre-training models including CINO, we constructed a dataset of minority language classification tasks based on WikipediaWiki-Chinese-Minority (WCM).see detailsMinority Language Classification Dataset.
-
Experiments have proved that CINO has achieved the best results on Wiki-Chinese-Minority (WCM) and other minority language datasets: Tibetan News Classification Corpus (TNCC) and Korean News Classification KLUE-TC (YNAT). Effect.For related results, seeExperimental results.
The model covers:
- Chinese, Chinese (zh)
- Tibetan, Tibetan (bo)
- Mongolian (Uighur form), Mongolian (mn)
- Uyghur, Uighur (ug)
- Kazakh (Arabic form), Kazakh (kk)
- Korean, Korean (ko)
- Zhuang, Zhuang
- Cantonese, Cantonese (yue)
#CINO #Homepage #Documentation #Downloads #Minority #Language #Pretraining #Model #News Fast Delivery