ImageBind is an AI model that supports binding information from six different modalities (image, text, audio, depth, temperature, and IMU data), which unifies this information into a single embedded representation space, enabling machines to more comprehensively , learning directly from multiple information without explicit supervision (i.e., the process of organizing and labeling raw data).
ImageBind forms a single embedding space by concatenating text, image/video and audio, vision, temperature, and motion data streams, enabling machines to understand the world from multiple dimensions and create immersive multi-sensory experiences.
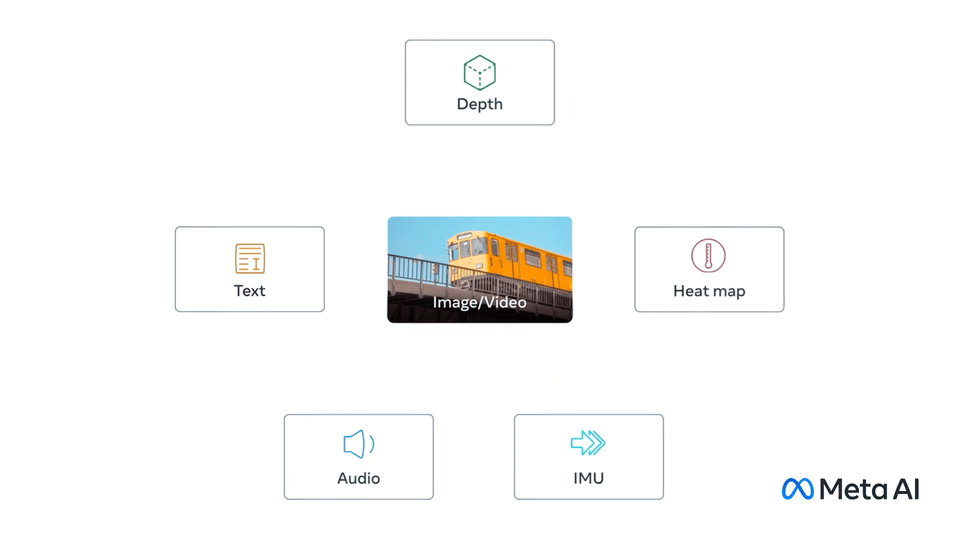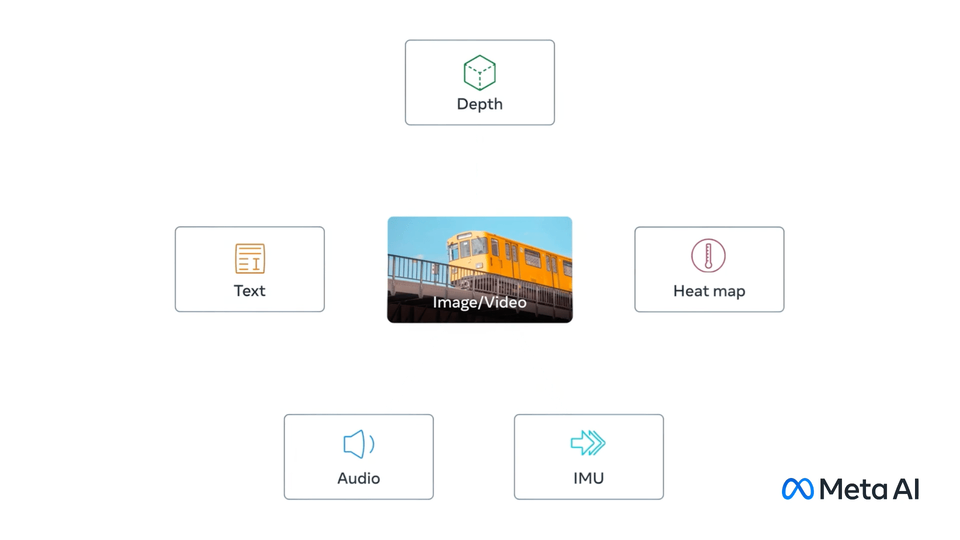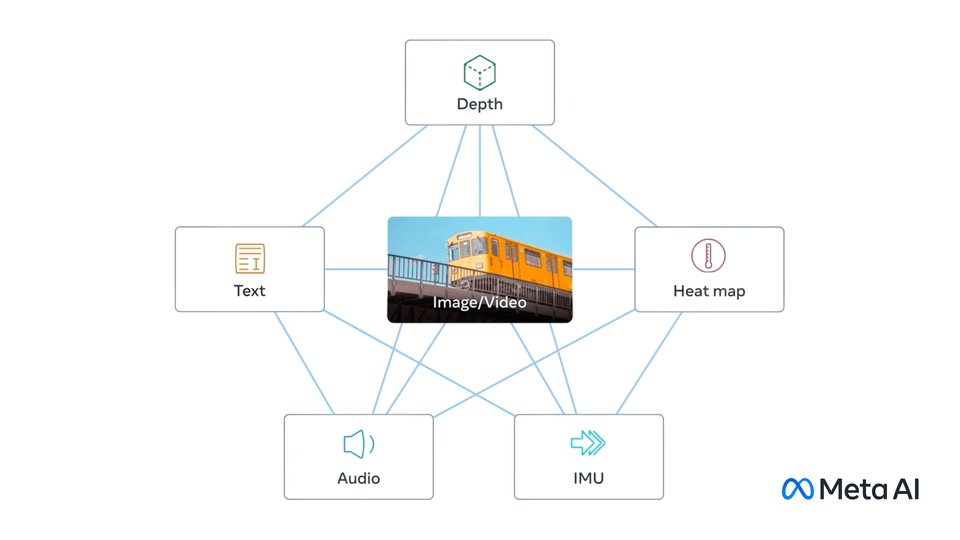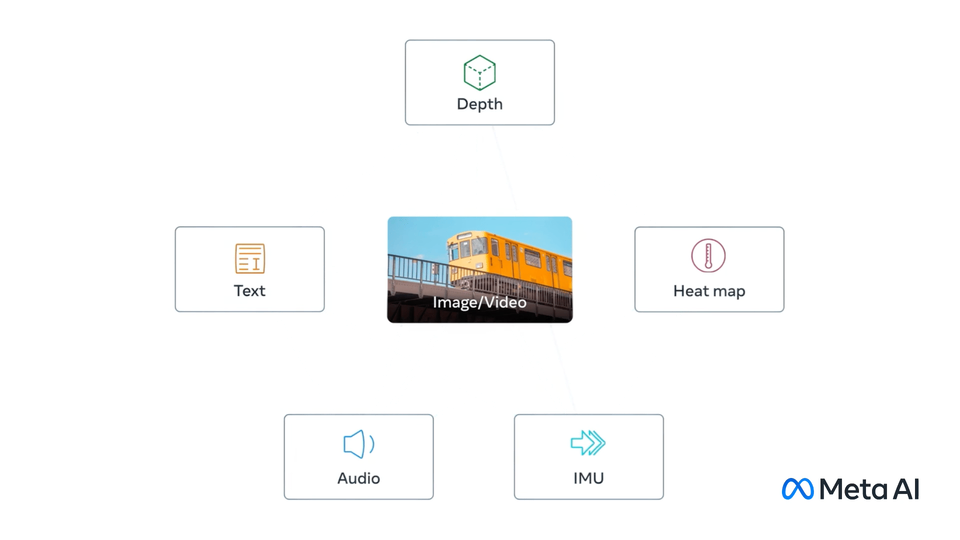
ImageBind enables cross-modal retrieval by aligning the embeddings of the six modalities into a shared space, which enables searching for different types of content that do not co-occur. By embedding different patterns into superpositions, their semantics can be constructed naturally. For example, ImageBind can be embedded with DALLE-2 decoder and CLIP text to generate audio-to-image mapping, just like the feeling of human beings hearing the sound and making up the picture.
sample code
Extract and compare features across modalities such as image, text, and audio.
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
# Expected output:
#
# Vision x Text:
# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
# [3.3836e-05, 9.9994e-01, 2.4118e-05],
# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
#
# Audio x Text:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
#
# Vision x Audio:
# tensor([[0.8070, 0.1088, 0.0842],
# [0.1036, 0.7884, 0.1079],
# [0.0018, 0.0022, 0.9960]])#ImageBind #Homepage #Documentation #Downloads #Multimodal #Model #News Fast Delivery