Author: vivo Internet front-end team – Su Ning
Using the machine learning model based on the self-attention mechanism to design the layout of the design draft can be combined with the context of the dom node to obtain a reasonable solution.
1. Background
The traditional craft of cutting diagrams as a front-end is a task that most front-end developers are unwilling to face.
In order to solve the various problems of cutting diagrams, people have racked their brains to develop a variety of design draft-to-code (D2C) tools, and these D2C tools continue to iterate as the software used by designers changes.
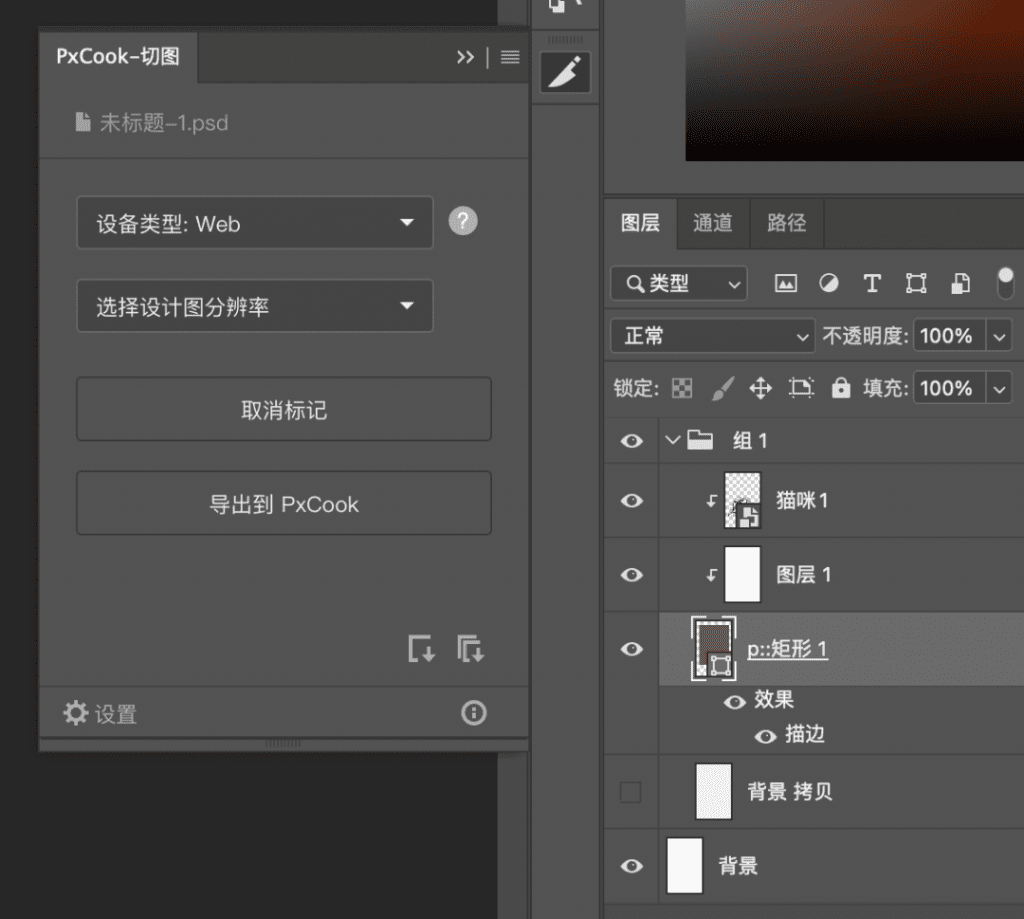
From the era of Photoshop, the front-end needs to manually mark nodes for separate style export (as shown in Figure 1), to sketch measure, which can be output as a whole page (as shown in Figure 2), and its efficiency and results have been qualitatively improved.
However, the problem of cutting pictures has not been completely solved, because the information contained in the design draft is only responsible for outputting the style, and there is no way to output the layout of the web page. We still have no way to directly copy the generated code and use it directly in our project.
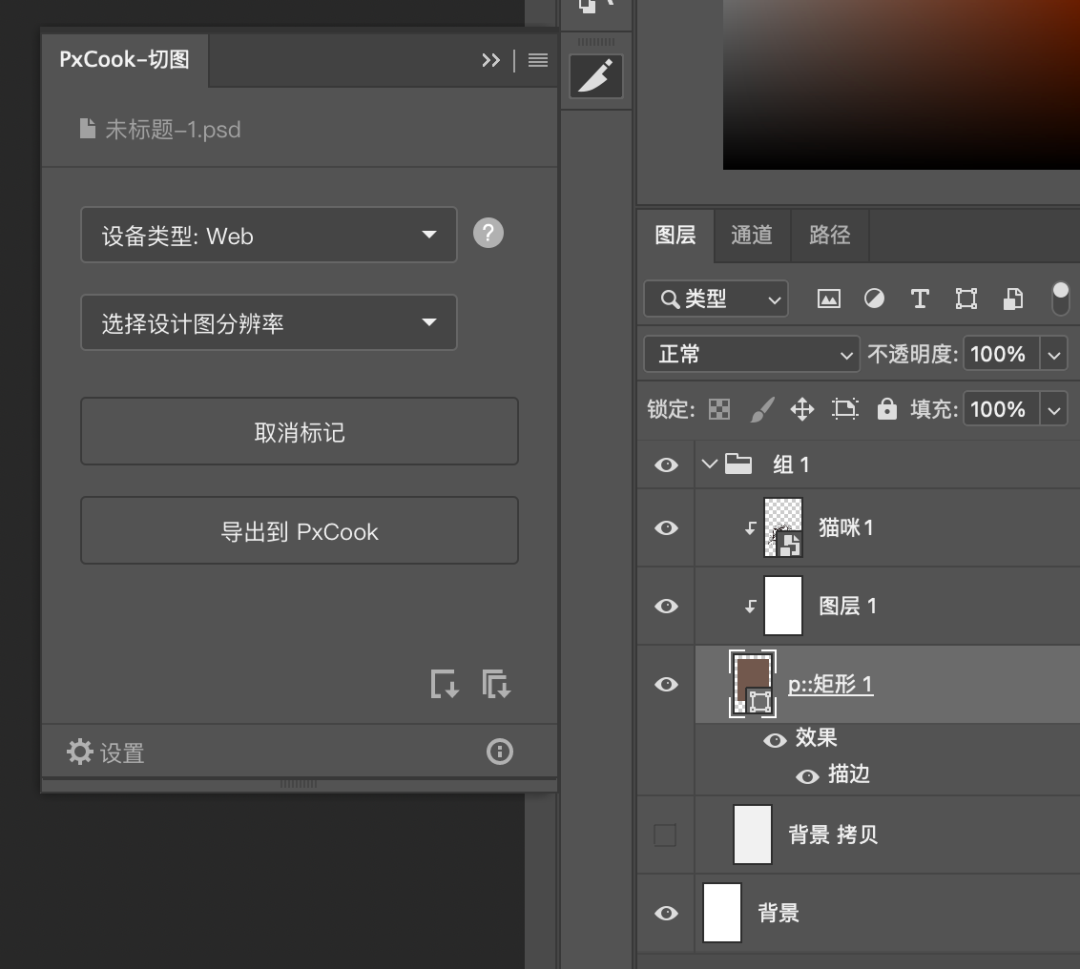
figure 1

figure 2
In the process of studying the existing D2C cases, we found that many mature solutions reference the generation of machine learning-assisted code, most of which are used for visual recognition and semantic recognition, so we wondered whether machine learning can Applied to the layout of the web page?
In order to verify our conjecture and solve the actual pain points in our work, we decided to develop a D2C tool ourselves, hoping to help us realize the process of web page layout through the machine. The overall workflow is roughly as shown in Figure 3. First, get the metadata of the design draft data, and then perform a series of processing on the data of the design draft to export the free dsl, and then generate the code of the corresponding end according to the dsl.
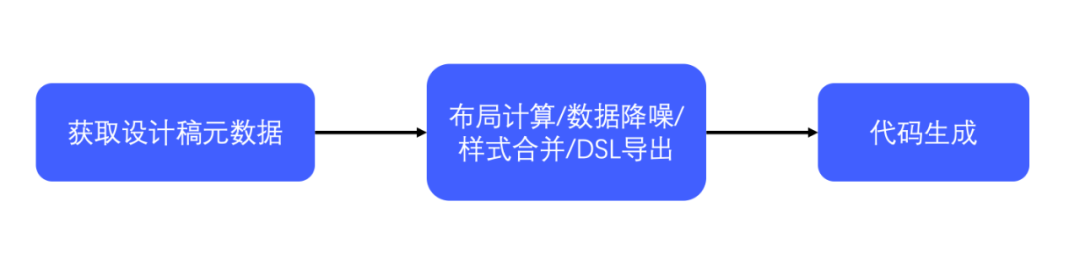 image 3
image 3
Second, the page layout
To deal with the layout of web pages, two problems need to be solved, the parent-child relationship of nodes and the positional relationship between nodes.
2.1 Parent-child relationship of nodes
The parent-child relationship of a node refers to which child nodes a node contains and which node it contains. The content of this part can be directly processed by rules, and whether a node is a child node of another node is judged by the vertex position of the node and the position information of the center point. We will not discuss it here.
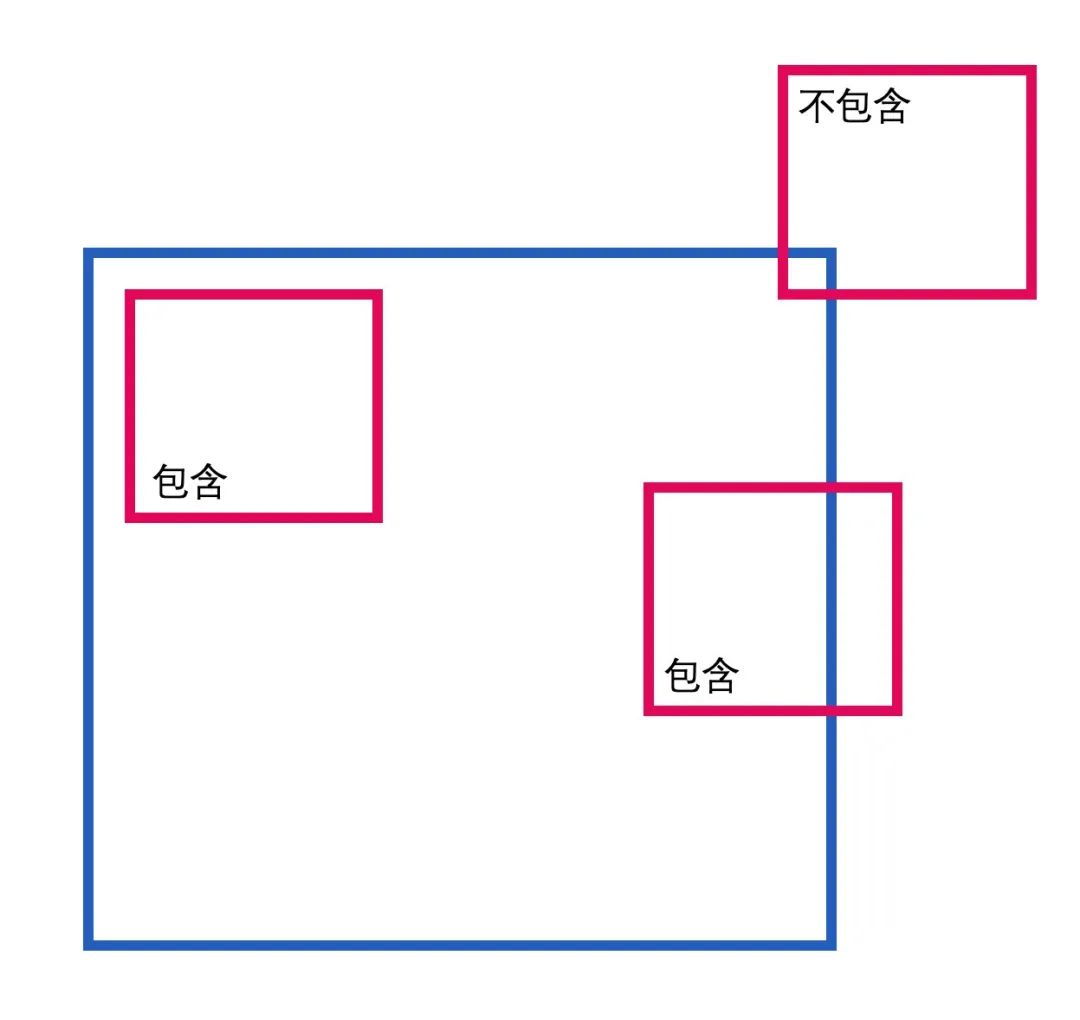
The positional relationship between nodes at the same level is the problem we focus on solving this time.
2.2 Location relationship between nodes
There are many layouts of web pages, linear layout, flow layout, grid layout, and absolute positioning with arbitrary positioning, etc. When we export the style, we need to confirm two things, the positioning method of nodes (relative, absolute, fixed) and the layout orientation of the node (portrait, landscape).

Linear layout

Flow layout

grid layout
According to the usual habit of cutting graphs, we will first identify whether there is an obvious up-down or left-right positional relationship between a group of level nodes, and then put them into the grid, and finally the nodes that are independent of these nodes are absolutely positioned. .
Letting the machine identify the positional relationship between nodes has become a key part of solving the problem.

Judging the positional relationship between nodes only needs the position and width and height information of the nodes, so our input data is designed as follows:
[{width:200,height:50,x:0,y:0},{width:200,height:100,x:0,y:60},{width:200,height:100,x:210,y:60}]
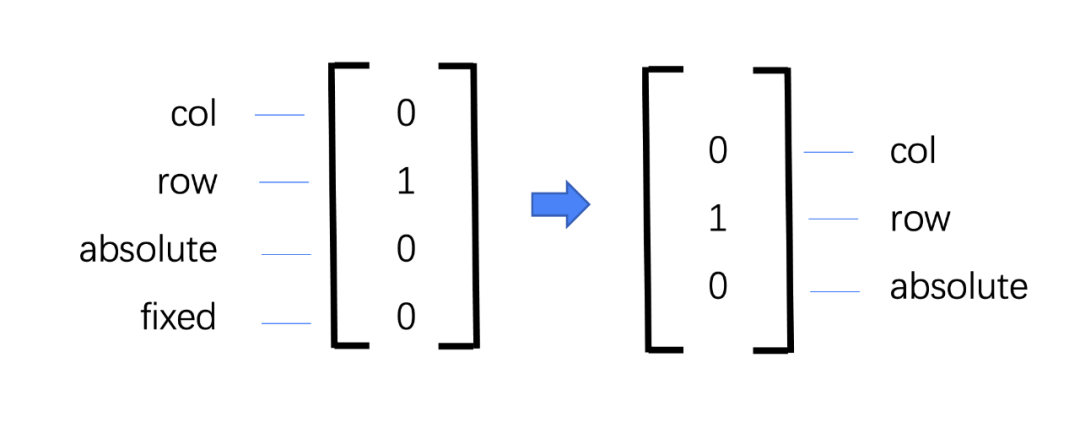
At the same time, the output result we hope to obtain is whether each node is arranged up and down, left and right, or absolutely positioned. The output data is designed as follows:
[{layout:'col'},{layout:'row'},{layout:'absolute'}]
At first, we hoped to judge the layout by writing certain rules, and make the layout by judging whether the positional relationship between the front and rear nodes is up and down or left and right. However, the rules that only focus on the positional relationship of the two nodes are difficult to judge the absolutely positioned nodes. , and fixed rules are always inflexible. So we thought of machine learning, which is good at dealing with classification problems.
Obviously, a machine learning model trained with a large amount of data can well imitate our usual habit of cutting pictures, and can be more flexible when dealing with various edge scenarios. As long as a reasonable model design is carried out, it can assist us in the layout processing.
3. Why is self-attention?
As we can see from the above, we need to train a model, input a list of nodes, and output the layout information of a node. Is it a bit like part-of-speech translation in text recognition?
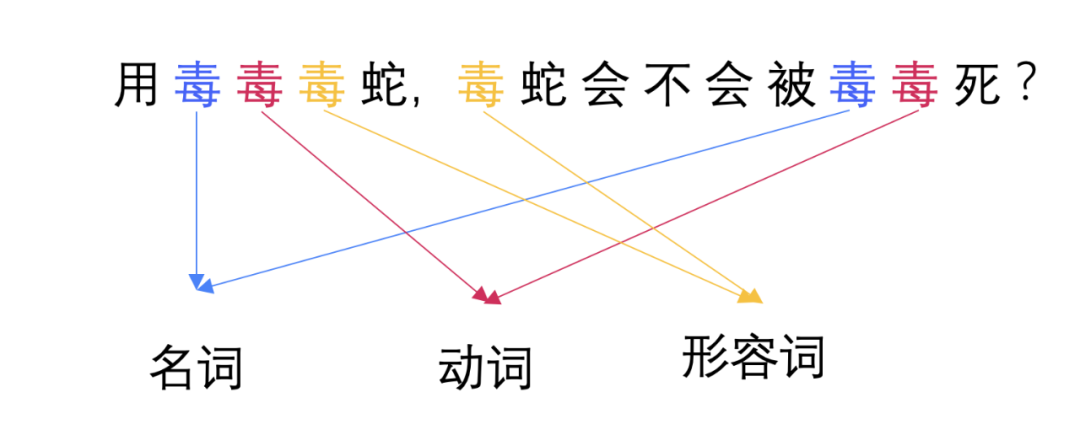
For a specific node, we have no way to judge its real layout. Only by putting it in the document flow and looking at the context can it reflect its actual meaning.
In dealing with part-of-speech tags, RNN (Recurrent Neural Network) and LSTM (Long Short-Term Memory Network) are more suitable for such scenarios. As a classic neural network model, RNN is established by bringing the weights of the previous training into the next training. Contextual association, LSTM as a variant of RNN solves the long-term dependency problem that RNN is difficult to solve, and it seems to be a good choice for training web page layout.
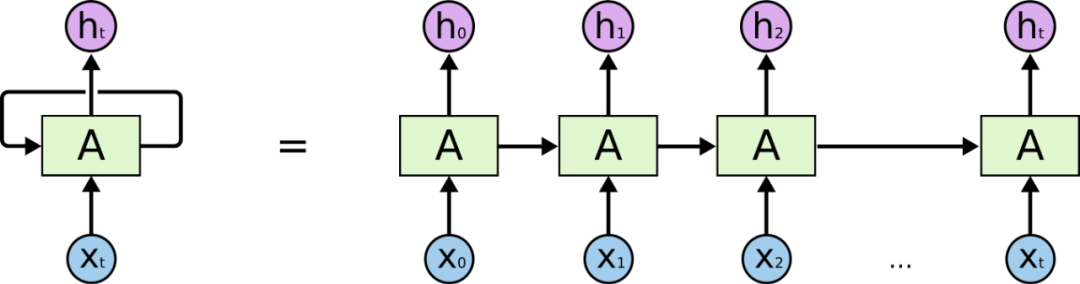
RNN (Recurrent Neural Network)
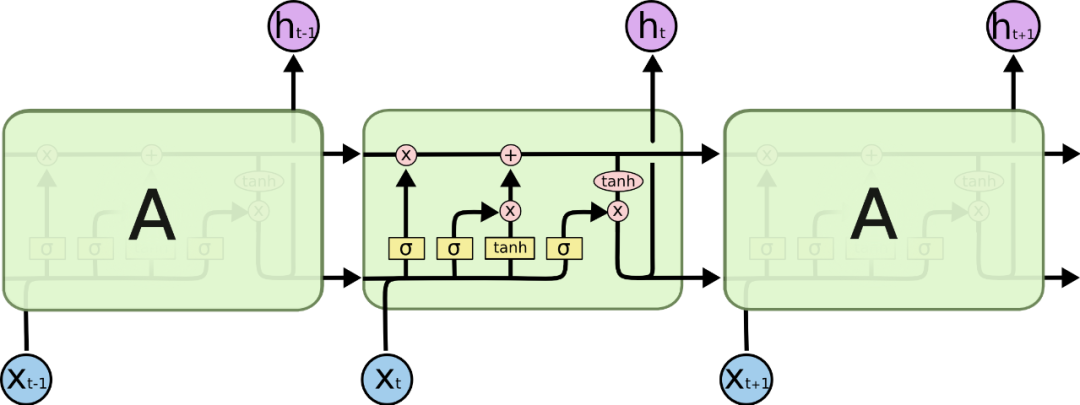
665px LSTM (Long Short Term Memory Network)
Using LSTM can indeed solve our problem, but due to the dependence of such neural networks on time series, there is no way to perform parallel operations on the context data, which makes our computer unable to train the model more efficiently, and the web page layout only needs to obtain different nodes There is no strong requirement for the loading order.
With the publication of an article “Attention is All you Need” in 2017, the whole field of machine learning has ushered in a new round of revolution. The most mainstream frameworks transformer, BERT, and GPT are all based on attention. developed.
Self-attention The self-attention mechanism is a variant of the attention mechanism. The weight information of a single vector in the global is obtained through the global association weight. Because each node adopts the same operation method, the nodes in the same sequence can be processed at the same time. Context computing greatly improves the efficiency of model training and makes it easier for us to optimize and regression models.
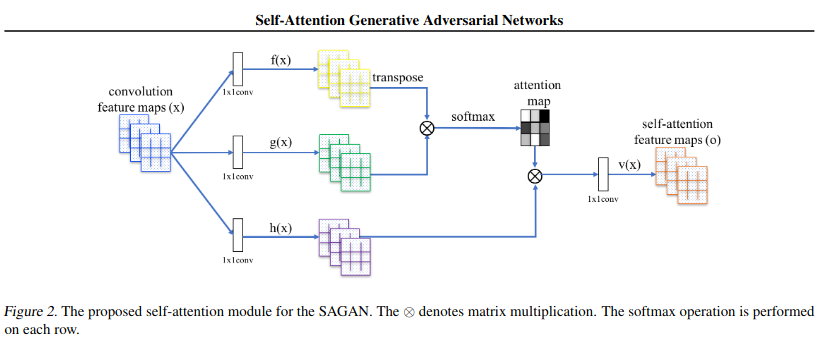
self-attention
In summary, considering the better contextual correlation and better parallel performance of attention, we decided to model based on this.
4. Model Design
We initially designed an output vector to identify the results of data processing,[1,0,0,0]The representative is a normal vertical arrangement,[0,1,0,0]Represents horizontal arrangement, and so on represents absolute and fixed positioning methods in turn, but later we found that fixed is a positioning method relative to the entire page, so it is difficult to mark at a single level, so we shortened the output value to There are three cases of vertical arrangement, horizontal arrangement and absolute positioning.
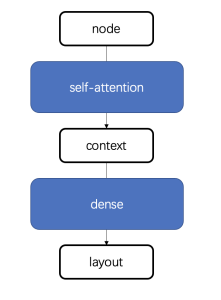
The overall design of the model is as follows. The nodes are converted into contextual information through self-attention, and then the contextual information is trained into a specific layout through a feedforward neural network.
(1) After obtaining a set of data, in order to remove the influence of the size of the value, we first normalize the data once, and divide each value of the input data by the maximum value in the set of data.
(2) Perform three linear transformations on each set of data to obtain the corresponding Q, K, and V of each set of data, and then we can perform the self-attention operation.
(3) Let’s take node1 as an example. If you need to calculate the correlation between node1 and other nodes, you need to use Q1 to perform a dot product operation with the key of each node, and multiply their sum with V1. After the multiplication is too large, the last softmax calculation is performed to obtain the context information of node1 and other nodes.
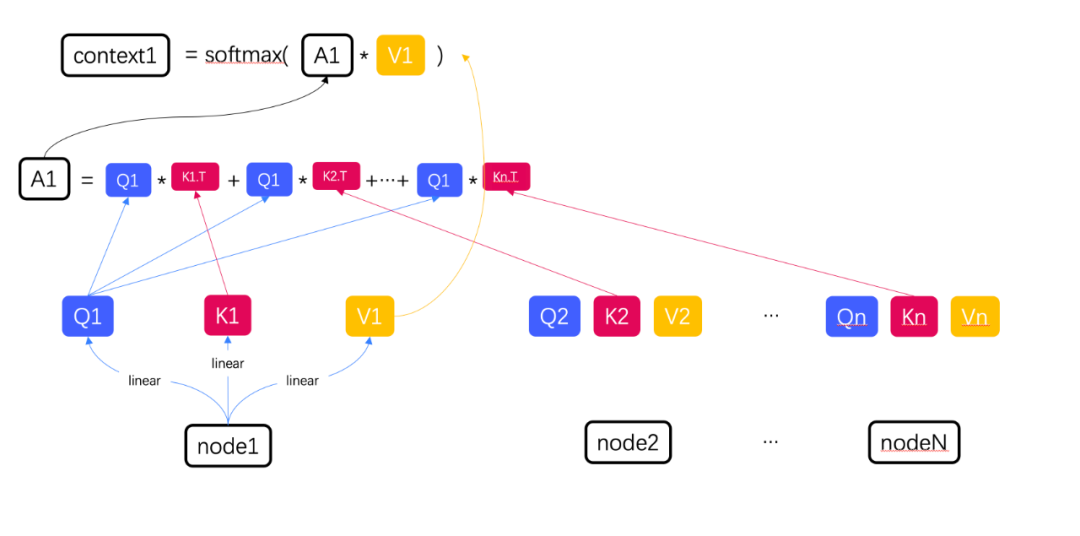
We regard all QKVs in a set of data as three matrices, and the set of obtained contexts can be regarded as a matrix calculation.
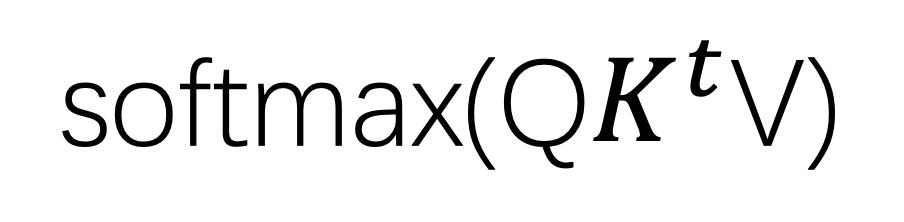
(4) In order to improve the training effect, the context information of each node is input into the feedforward neural network to train the final layout result, and the softmax calculation is performed on the obtained result to obtain the probability distribution of the layout of a single node in a set of data. Since the operations of the same group of nodes have no sequential order, the operations of a single node can be performed at the same time, which greatly improves the efficiency of training with GPU acceleration.
5. Data preparation
Since machine learning requires massive data, the quantity and quality of the data will greatly affect the final training effect of the model, so the quantity and quality of the data are very important. We use three data sources for data training. The design draft, the real web page data captured, and the automatically generated data.
5.1 Marking of design draft
After obtaining the design draft data, only the positioning and width and height data of each node are obtained, and the node data of each layer is obtained after processing the above parent-child relationship. In order to prevent overfitting, we remove a relatively small number of nodes. , and manually label the layout of each layer. Design draft markup data is the best quality, but also the most time-consuming and labor-intensive work, so other data sources need to be supplemented in quantity.
5.2 Crawling of real web pages
As a supplement to the markup design draft, the real data in the web page is also a reliable data source, but the biggest difficulty in the process of crawling the web page is to determine whether the nodes in the page are horizontal or vertical.
Due to the strange ways to achieve horizontal arrangement, we can use float, inline-block, flex and other methods. If we only get the positioning and width and height information of the nodes in the web page, we still need to manually mark his layout, so we still need to start from the css of the nodes. Start with manual filtering after batch acquisition to remove low-quality data. It is an effective complement to the marked design draft.
5.3 Web page generator
In order to generate a large amount of data faster, we wrote a webpage generation algorithm, which determines the positioning method of the nodes at the beginning, then renders the nodes into webpages, and finally grabs the positioning information of the nodes, but the randomly generated data exists. Some unstable boundary scenarios, such as the generated absolutely positioned nodes, will be positioned just to the right of the horizontal layout. In this case, manual screening is required.
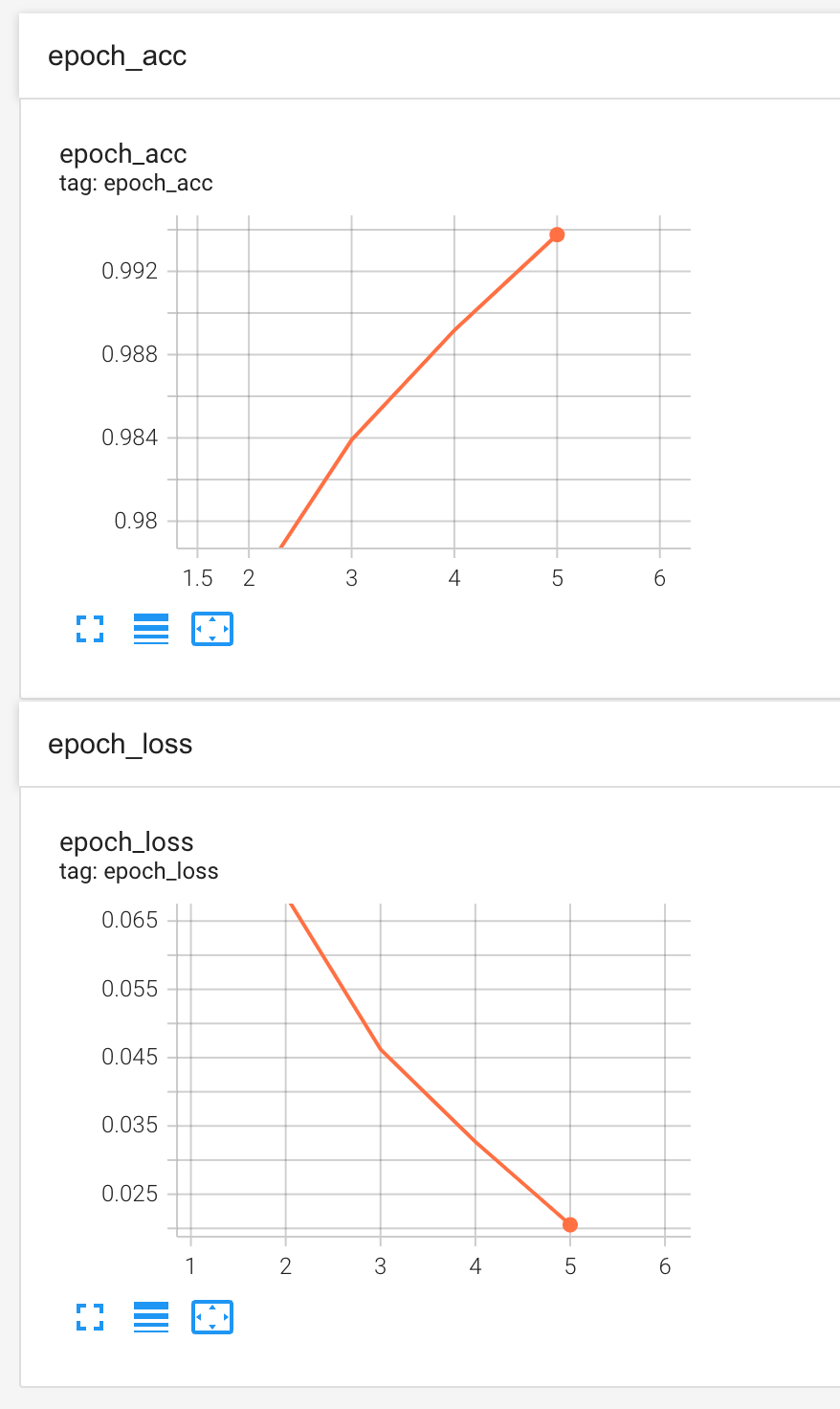
We finally collected about 20,000 pieces of data, and after repeated training and debugging, the final accuracy rate stabilized at about 99.4%, reaching a relatively usable level.
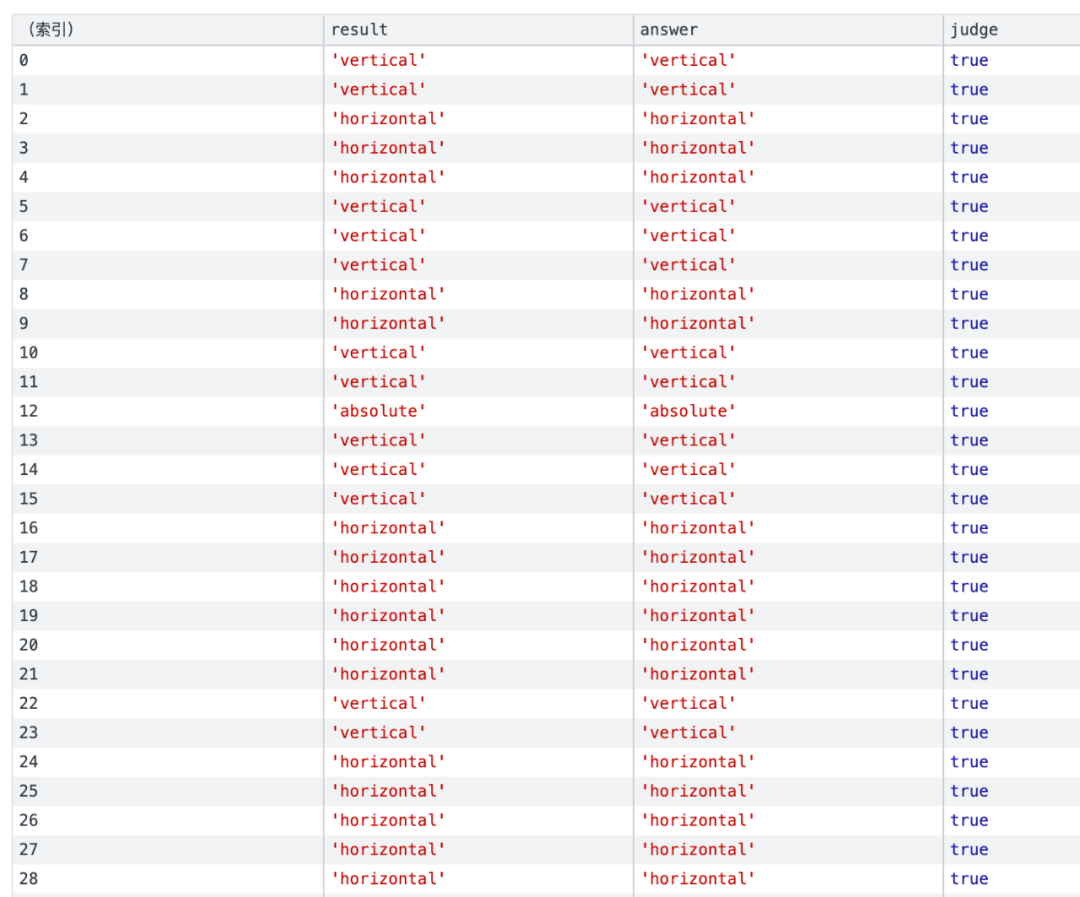
Using the real DOM for regression verification, it can be seen that the horizontal and vertical layout of the web page and the absolutely positioned nodes are accurately identified.
Six, optimization direction
6.1 Element wrapping
In the design draft, there will be a situation where the list cannot be placed in one line and then wraps. These nodes should belong to the horizontal positional relationship, but the machine will recognize the first element of each line as a vertical arrangement when facing two lines, which requires repeated nodes. Perform similarity detection and use the same layout strategy for similar nodes.
6.2 Grouping problems
Rule-based grouping will result in that two disjoint nodes will not be assigned to a group, such as icons and text in a grid, resulting in two separate groups during layout, which can be combined with content recognition by training common layouts for more precise grouping.
6.3 General layout
Through the self-attention mechanism, we can not only judge the layout information of a single node at its level, but we can also diverge, and by training the node data of the entire level, we can get that the current node belongs to the card stream, label, personal information page and other functional markers, Further deriving the function of each node, combined with the specific layout information of the node, not only can better realize the layout of web pages, but also can push the function of the node to realize the semantics of the label.
6.4 Data Generation
In order to solve more web page layout problems and reduce our manual labeling workload, we can use the reinforcement learning model to develop a set of web page generation tools to make our data closer to the real web page layout, so that the results of the layout model training are closer production scene.
7. Summary
Machine learning is very good at dealing with classification problems. Compared with the traditional handwritten rule layout, machine learning is trained based on our existing development habits, and the final generated code is also closer to our usual habit of cutting pictures. The readability of the code and Maintainability is even better.
Compared with static pages handwritten by different people, machine-generated static pages follow consistent code specifications, and the code style is more uniform.
In the process of model building, specific usage scenarios can be compared to the content in the field of text or images, which is convenient for finding existing models for transfer learning.
The core of using machine learning to solve the problem of web page layout is to establish the contextual association of nodes. By understanding the operating principles of various classic neural network models, we have selected the recurrent neural network and self-attention mechanism, which can establish contextual association models. Through further understanding of its operating principle, we have chosen a self-attention model that is closer to the web page layout scenario and has higher operating efficiency. It can also be seen that understanding the operating mechanism of the model can better help us solve practical application scenarios. .
END
you may also like
This article is shared from the WeChat public account – vivo Internet Technology (vivoVMIC).
If there is any infringement, please contact support@oschina.cn to delete it.
This article participates in the “OSC Yuanchuang Program”, and you are welcome to join and share with us.
#vivo #frontend #intelligent #practice #application #machine #learning #automatic #web #page #layout #vivo #Internet #Technology #News Fast Delivery