Author: Yan Qiu
After 6 years, with the efforts of various teams, Alibaba Group’s large-scale sparse model training/prediction engine DeepRec has been officially open-sourced to help developers improve the performance and effects of sparse model training.
What is DeepRec
DeepRec (PAI-TF) is a unified large-scale sparse model training/prediction engine of Alibaba Group. It is widely used in Taobao, Tmall, Alimama, AutoNavi, Taote, AliExpress, Lazada, etc. It supports Taobao search, recommendation, Advertising and other core businesses support ultra-large-scale sparse training with hundreds of billions of features and trillions of samples.
DeepRec optimizes the performance of sparse models in depth in terms of distribution, graph optimization, operators, runtime, etc., and provides unique Embedding-related functions in sparse scenarios.
The DeepRec project has been developed since 2016. It has been jointly built by the AOP team, XDL team, PAI team, RTP team and Ant Group AIInfra team within Alibaba Group, and has been supported by Taobao recommendation algorithm and other business algorithm teams. The development of DeepRec is also supported by Intel CESG software team, Optane team and PSU team, NVIDIA GPU computing expert team and Merlin HughCTR team.
DeepRec Architecture Design Principles
Large-scale sparse features are supported on the TensorFlow engine. There are many ways to implement them in the industry. The most common way is to draw on the architecture implementation of ParameterServer, and independently implement a set of ParameterServer and related optimizers outside TensorFlow. At the same time, inside TensorFlow The two modules are bridged by bridge. This approach has certain advantages. For example, the implementation of PS will be more flexible, but there are also some limitations.
DeepRec adopts another architectural design method, following the architectural design principle of “viewing the entire training engine as a system as a whole”. TensorFlow is a static graph training engine based on Graph. It has corresponding layers in its architecture, such as the top API layer, the middle graph optimization layer, and the bottom operator layer. TensorFlow supports the business requirements and performance optimization requirements of different workloads in the upper layer through the design of these three layers.
DeepRec also adheres to this design principle. Based on the design principle of storage/computing decoupling, the EmbeddingVariable function is introduced at the Graph level; based on the characteristics of Graph, the operator fusion of communication is realized. Through this design principle, DeepRec can support users to use the implementation of the same optimizer and the implementation of the same set of EmbeddingVariable in stand-alone and distributed scenarios; at the same time, it introduces a variety of optimization capabilities at the Graph level, so as to achieve independent module design. The resulting joint optimization design.
Advantages of DeepRec
DeepRec is a sparse model training/prediction engine based on TensorFlow1.15, Intel-TF, and NV-TF. It has been customized and deeply optimized for sparse model scenarios. It mainly includes the following three types of functional optimizations:
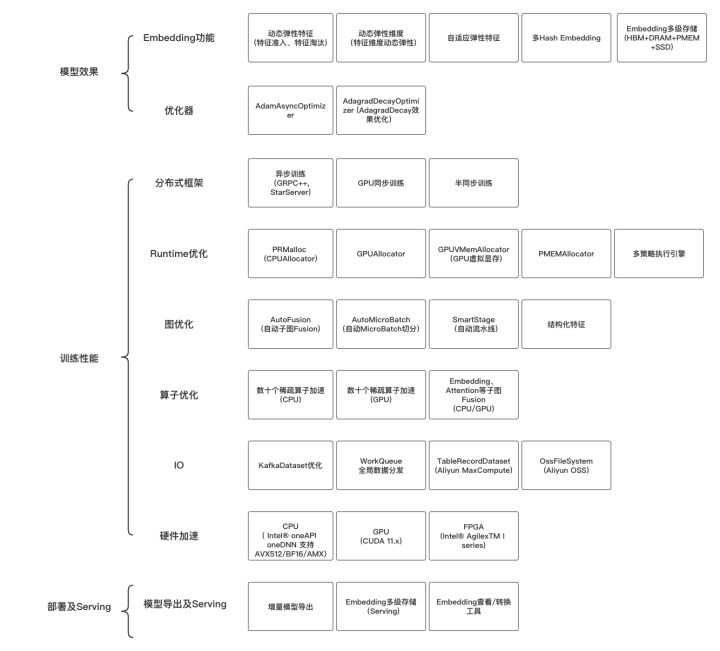
model effect
DeepRec provides rich sparse function support, which improves the model effect while reducing the size of the sparse model, and optimizes the effect of the Optimizer under ultra-large scale. The following is a brief introduction to several distinctive jobs of Embedding and Optimizer:
- EmbeddingVariable (dynamic elastic feature):
1) Solved the problems of unpredictable vocabulary_size of static Shape Variable, feature conflict, memory and IO redundancy, etc., and provided rich advanced functions of EmbeddingVariable in DeepRec, including different feature access methods and support for different features Elimination strategies, etc., can significantly improve the effect of the sparse model.
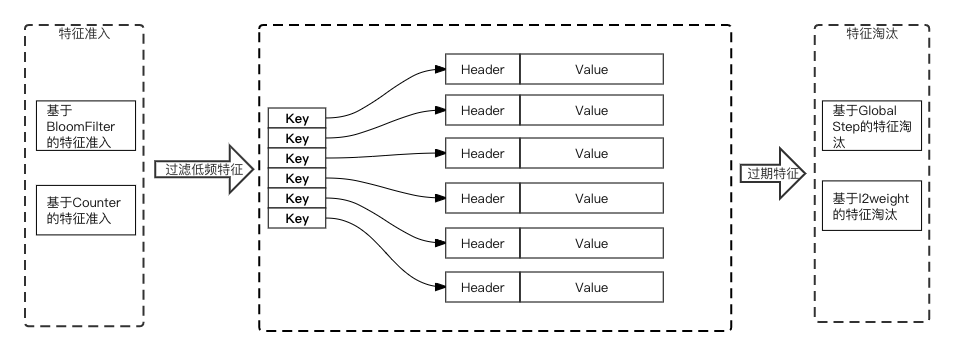
2) In terms of access efficiency, in order to achieve more optimized performance and lower memory usage, the underlying HashTable of EmbeddingVariable implements a lock-free design, and performs fine memory layout optimization to optimize the access frequency of HashTable. The process only needs to access the HashTable once in the forward and backward directions.
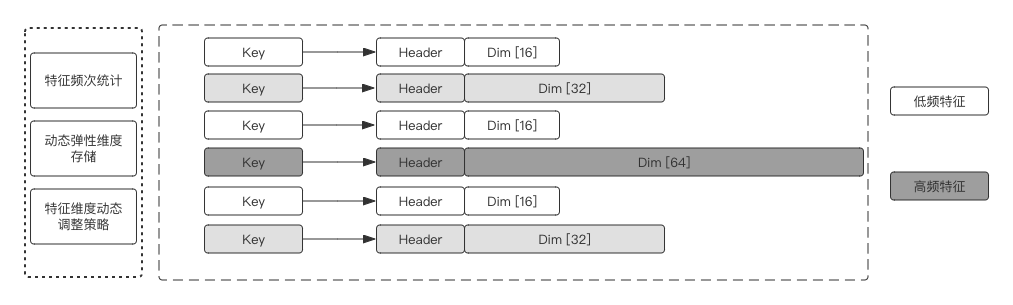
- DynamicDimensionEmbeddingVariable:
In typical sparse scenarios, the frequency of similar features tends to be extremely uneven. Usually, the features of the same feature column are set to a uniform dimension. If the Embedding dimension is too high, the low-frequency features are prone to overfitting, and it will consume a lot of memory; if the dimension is set too low, the high-frequency features may be The effect is affected by insufficient expression.
Dynamic Dimension Embedding Variable provides different eigenvalues of the same feature column, and automatically configures different feature dimensions according to the hot and cold features of the feature. High-frequency features can be configured with higher dimensions to enhance the expression ability, while low-frequency features are given low-dimensional embedding. Fitting problem, and can save memory to a great extent (the number of low-frequency long-tail features has an absolute advantage).
- Adaptive Embedding:
When using the dynamic elastic feature function, there is an overfitting problem for low frequency features. All features in EmbeddingVariable are learned from the initial value set by the initializer (usually set to 0). For some features whose frequency is from low to high, it is also necessary to gradually learn a better state and cannot share other features. learning results. The AdaptiveEmbedding function uses static Shape Variable and dynamic EmbeddingVariable to jointly store sparse features. For newly added features, there are conflicting Variables, and for features with higher frequency, there are non-conflicting EmbeddingVariables. Features migrated to EmbeddingVaraible can be reused in conflicting variables. The learning result of the static Shape Variable.

- Adagrad Decay Optimizer:
An improved version of the Adagrad optimizer proposed to support very large-scale training. When the sample size of the model training is large and the incremental training is continued for a long time, the gradient of the Adagrad optimizer will approach 0, so that the newly trained data cannot affect the model. Although the existing cumulative discount scheme can solve the problem of the gradient approaching 0, it will also bring about the problem of poor model effect (the discount strategy through iteration cannot reflect the characteristics of the actual business scenario). Adagrad Decay Optimizer is based on the cycle discount strategy, the samples in the same cycle have the same discount strength, taking into account the infinite accumulation of data and the impact of sample order on the model.
In addition, DeepRec also provides functions such as Multi-HashEmbedding and AdamAsyncOptimizer, which bring practical help to the business in terms of memory usage, performance, and model effects.
training performance
DeepRec has carried out deep performance optimization in terms of distribution, graph optimization, operator, Runtime, etc. for sparse model scenarios. Among them, DeepRec deeply optimizes different distributed strategies, including asynchronous training, synchronous training, semi-synchronous training, etc. Among them, GPU synchronous training supports HybridBackend and NVIDIA HugeCTR-SOK. DeepRec provides rich graph optimization functions for sparse model training, including automatic pipeline SmartStage, structured features, automatic graph fusion, and more. Dozens of common operators in sparse models are optimized in DeepRec, and Fusion operators including general subgraphs such as Embedding and Attention are provided. The CPUAllocator and GPUAllocator in DeepRec can greatly reduce the memory/video memory usage and significantly accelerate the training performance of E2E. In terms of thread scheduling and execution engine, different scheduling engine strategies are provided for different scenarios. The following is a brief introduction to several distinctive work in distribution, graph optimization, and runtime optimization:
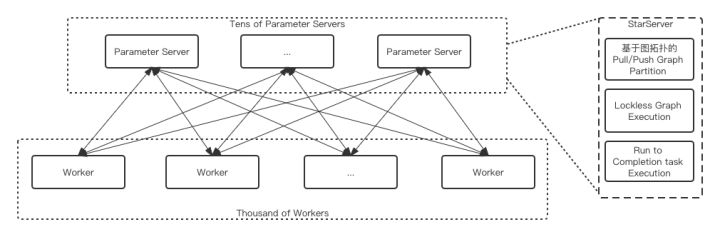
- StarServer (asynchronous training framework):
In ultra-large-scale task scenarios (hundreds, thousands of workers), some problems in native open source frameworks are exposed, such as inefficient thread pool scheduling, lock overhead on critical paths, inefficient execution engines, frequent small packets The overhead brought by rpc causes ParameterServer to become an obvious performance bottleneck when distributed scaling. StarServer has carried out optimizations including graph, thread scheduling, execution engine and memory, modified the send/recv semantics in the original framework to pull/push semantics, and supported the semantics in subgraph division, and implemented the ParameterServer side graph at the same time Lockfree in the execution process realizes lock-free execution and greatly improves the efficiency of concurrent execution of subgraphs. Compared with the native framework, it can improve the training performance several times, and supports linear distributed expansion of 3000worker scale.
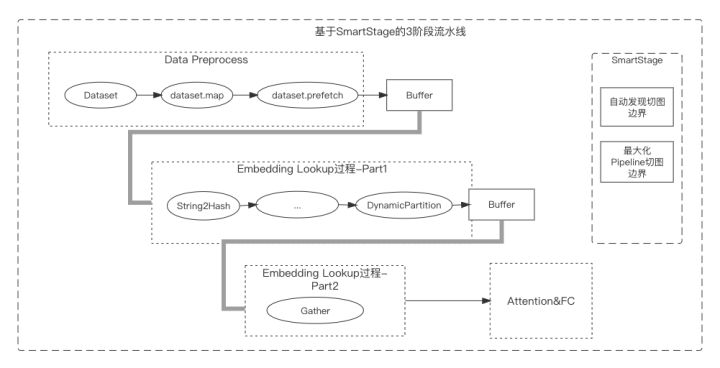
- SmartStage (automatic pipeline):
Sparse model training usually includes sample data reading, Embedding search, Attention/MLP calculation, etc. Sample reading and Embedding search are non-computation-intensive operations, and at the same time, computing resources (CPU, GPU) cannot be used efficiently. The dataset.prefetch interface provided in the native framework can asynchronously read sample operations, but the embedding search process involves complex processes such as feature completion and IDization, which cannot be pipelined through prefetch. The SmartStage function can automatically analyze the boundaries of asynchronous pipelines in the graph and automatically insert them, which can maximize the performance of concurrent pipelines.
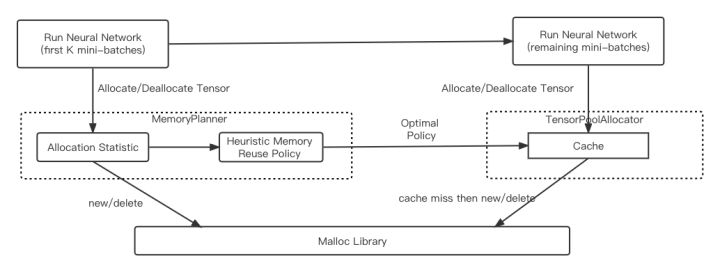
- PRMalloc (memory allocator):
How to use memory efficiently and effectively is very important for the training of sparse models. The allocation of large blocks of memory in sparse scene model training results in a large number of minor pagefaults. In addition, the efficiency of multi-thread allocation has a serious problem of concurrent allocation efficiency. Aiming at the characteristics of sparse model training forward and backward, Graph calculation mode is relatively fixed and multiple rounds of repeated iterations, DeepRec has designed a set of memory management solutions for deep learning tasks to improve memory usage efficiency and system performance. Using the PRMalloc provided in DeepRec can greatly reduce the minor pagefault during the training process and improve the efficiency of multi-threaded concurrent memory allocation and release.
- PMEM allocator:
The PMEM allocator implemented by the underlying libpmem library of PMDK divides a space mapped from PMEM into segments, and each segment is divided into blocks. Block is the smallest allocation unit of the allocator. To avoid thread competition, the thread that allocates the block caches some free space, including a set of segments and free lists. A free list and segment are maintained for each record size (several blocks) in the available space. The segment corresponding to each record size only allocates the PMEM space of that size, and all pointers in the free list corresponding to each record size point to the free space corresponding to the record size. In addition, in order to balance the resources of each thread cache, a background thread periodically moves the free list in the thread cache to the background pool, and the resources in the pool are shared by all foreground threads. Experiments show that the memory allocator based on persistent memory has little difference between the training performance of large models and the training performance based on DRAM, but TCO will have great advantages.
Deployment and Serving
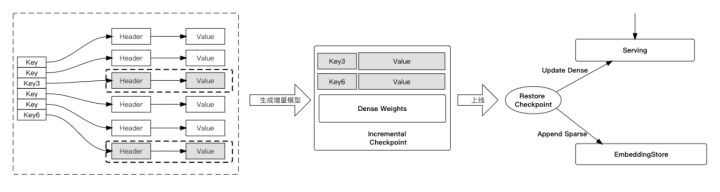
- Incremental model export and loading:
Businesses that require high timeliness require frequent online model updates, often at the minute or even second level. For super large models of TB-10TB level, it is difficult to complete the generation of models at the minute level and go online. In addition, the training and prediction of very large models have problems such as waste of resources and increased delay of multi-node Serving. DeepRec provides incremental model output and loading capabilities, which greatly accelerates the generation and loading of very large models.
- Embedding multi-level mixed storage:
The features in the sparse model have the characteristics of hot and cold skew, which leads to the memory/video memory waste problem caused by the infrequent access and update of some unpopular features, as well as the problem that the memory/video memory of the large model cannot be stored. DeepRec provides the capability of multi-level hybrid storage (supporting up to four levels of hybrid storage HBM+DRAM+PMEM+SSD), automatically storing unpopular features in cheap storage media, and storing popular features in faster and more expensive access On the storage medium, through multi-level hybrid storage, a single node can perform Training and Serving of the TB-10TB model.
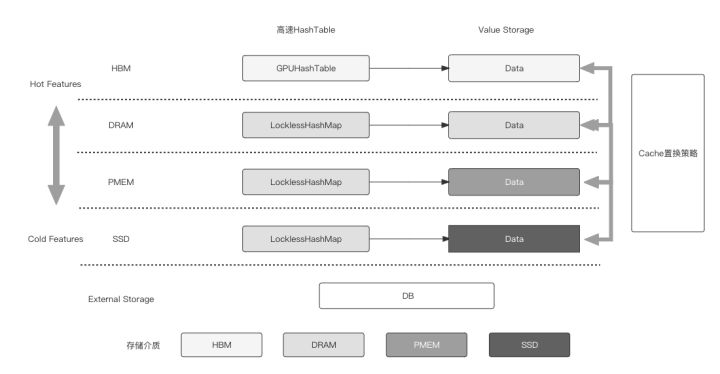
Through multi-level hybrid storage, the ability of GPU to train sparse models can be maximized, and the waste of computing resources due to storage resource limitations can be reduced. Fewer machines can be used for model training of similar scale, or the same number of machines can be used for more training. massive training. Multi-level hybrid storage can also avoid the problem of increased latency caused by distributed Serving when a single machine predicts a very large model, and improves the prediction performance of the large model while reducing costs. The multi-level hybrid storage function also has the access feature of automatically discovering features. Based on an efficient heat statistics strategy, the high-heat features are placed in the fast storage medium, and the low-frequency features are offloaded to the low-speed storage medium, and then driven in an asynchronous manner. Features move between multiple media.
Why open source DeepRec
None of the open source deep learning frameworks can well support the requirements for sparse Embedding functions in sparse scenarios, model training performance requirements, deployment iterations, and online service requirements. DeepRec has been polished by Alibaba Group’s core business scenarios such as search, recommendation, and advertising, as well as various business scenarios on the public cloud, and can support training effects and performance requirements of different types of sparse scenarios.
Alibaba hopes to further promote the development of the sparse model training/prediction framework by establishing an open source community and extensive cooperation with external developers, bringing business effects and performance improvements to the training and prediction of search promotion models in different business scenarios.
Today’s open-sourcing of DeepRec is just a small step for us. We really look forward to your feedback. Finally, if you have a corresponding interest in DeepRec, you can also come around and contribute your code and opinions to our framework, which will be our great honor.
open source address: https://github.com/alibaba/DeepRecc
More open source project collections: https://www.aliyun.com/activity/bigdata/opensource_bigdata__ai
#Alibaba #open #source #largescale #sparse #model #trainingprediction #engine #DeepRec #News Fast Delivery #Chinese #open #source #technology #exchange #community