Author: Zhu Kai – Machine Learning PAI Team
With the continuous development of deep learning, the structure of AI models is evolving rapidly, and the underlying computing hardware technologies are emerging in an endless stream. For the majority of developers, it is not only necessary to consider how to effectively utilize computing power in complex and changeable scenarios, but also Cope with continuous iteration of computing frameworks. In-depth compilers have become a widely concerned technical direction to deal with the above problems, allowing users to focus only on upper-level model development, reducing the labor development cost of manual optimization performance, and further squeezing the hardware performance space. Alibaba Cloud Machine Learning PAI has open sourced BladeDISC, a dynamic shape deep learning compiler that has been put into practical business applications earlier in the industry. This article will explain the design principles and applications of BladeDISC in detail.
What is BladeDISC
BladeDISC is Alibaba’s latest open source MLIR-based dynamic shape deep learning compiler.
Main features
- Multiple front-end frameworks support: TensorFlow, PyTorch
- Multiple backend hardware support: CUDA, ROCM, x86
- Full support for dynamic shape semantic compilation
- Support inference and training
- Lightweight API, universal and transparent to users
- Support plug-in mode embedded in the host framework to run, and independent deployment mode
open source address
https://github.com/alibaba/BladeDISC
Background on Deep Learning Compilers
In recent years, deep learning compilers have been extremely active as a relatively new technical direction, including some old-fashioned TensorFlow XLA, TVM, Tensor Comprehension, Glow, and later the highly popular MLIR and its extension projects in different fields IREE, mlir -hlo and so on. It can be seen that different companies and communities are doing a lot of exploration and advancement in this field.
The wave of AI and the wave of chips were born together – from the beginning to the vigorous development
The reason why deep learning compilers have received continuous attention in recent years mainly comes from several reasons:
Framework performance optimization requirements in terms of model generalization.Deep learning is still developing rapidly, and innovative application fields are emerging. How to effectively utilize the computing power of hardware in complex and changeable scenarios has become a very important part of the entire AI application chain. In the early days, the focus of neural network deployment was on the framework and operator library, and this part of the responsibility was largely undertaken by the deep learning framework, the operator library provided by the hardware manufacturer, and the manual optimization work of the business team.
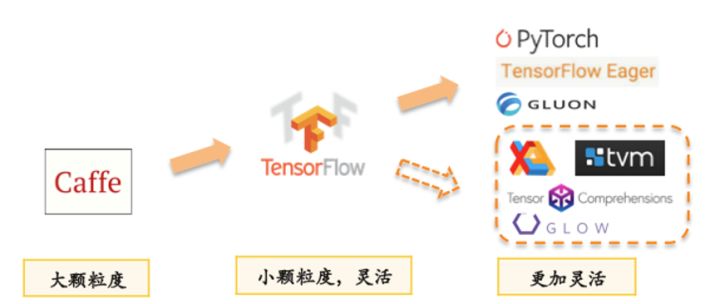
The above figure roughly divides the deep learning frameworks in recent years into three generations. A trend is at the upper user API level. These frameworks are becoming more and more flexible, and while the flexibility is becoming stronger, they also pose greater challenges to the underlying performance issues. The first-generation deep learning framework is similar to Caffe, which uses sequence of layers to describe the neural network structure. The second generation is similar to TensorFlow, which uses more fine-grained graph of operators to describe the computational graph. The third generation is similar to PyTorch and TensorFlow Eager Mode. Dynamic graph. We can see that the framework is becoming more and more flexible and the description ability is getting stronger and stronger. The problem is that it becomes more and more difficult to optimize the underlying performance. Business teams also often need to supplement the manual optimizations required to complete the work, which are labor-intensive and difficult to generalize, depending on the specific business and understanding of the underlying hardware. The deep learning compiler combines the optimization of compile-time layers and automatic or semi-automatic code generation to generalize the principle of manual optimization to replace various problems caused by pure manual optimization to solve deep learning. The tension between flexibility and performance of the framework.
The requirements of AI frameworks in terms of hardware generalizability.On the surface, the development of AI in recent years is obvious and in the ascendant, and the development of hardware computing power in the background for decades is the core driving force for catalyzing the prosperity of AI. With the increasing physical challenges faced by transistor scaling, increasing chip computing power is becoming more and more difficult, Moore’s Law is facing failure, and various DSA chips with innovative architectures have ushered in a wave of upsurges. Traditional x86, ARM And so on in different fields to strengthen their competitiveness. The blooming of hardware also brings new challenges to the development of AI frameworks.
The innovation of hardware is one problem, and how to use the computing power of hardware in real business scenarios is another problem. New AI hardware manufacturers have to face the problem of not only innovating in hardware, but also investing heavily in software stacks. How to be backward compatible with hardware has become one of the core difficulties of today’s deep learning framework, and the issue of hardware compatibility needs to be solved by the compiler.
The generalization requirements of the AI system platform for the front-end AI framework.Today’s mainstream deep learning frameworks include Tensoflow, Pytorch, Keras, JAX, etc. Several frameworks have their own advantages and disadvantages. The upper-layer interface to users is different, but they also face hardware adaptation and give full play to hardware computing power. The problem. Different teams often choose different frameworks according to their own modeling scenarios and usage habits, while the performance optimization tools and hardware adaptation solutions of cloud vendors or platforms need to consider different front-end frameworks and even the needs of future framework evolution. Google uses XLA to support TensorFlow and JAX at the same time. At the same time, other open source communities have also evolved access solutions such as Torch_XLA and Torch-MLIR. Although these access solutions still have some problems in terms of ease of use and maturity, they respond The generalization of front-end AI framework needs and technical trends for work at the AI system layer.
What is a deep learning compiler
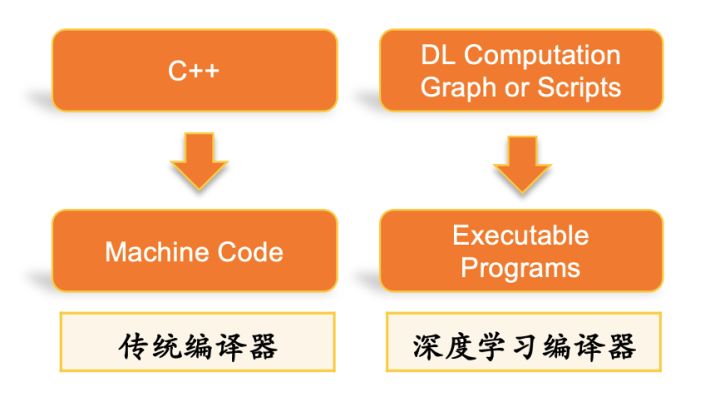
Traditional compilers use high-level languages as input, avoiding users to directly write machine code, and work with relatively flexible and efficient languages, and introduce optimizations in the compilation process to solve performance problems introduced by high-level languages, balancing development efficiency and performance. contradiction between. The role of the deep learning compiler is similar. Its input is more flexible and has a high abstraction calculation graph description, and the output includes the underlying machine code and execution engine on CPU, GPU and other heterogeneous hardware platforms.
One of the missions of traditional compilers is to relieve programmer stress. The high-level language used as the input of the compiler is often more about describing a logic. In order to facilitate programmers, the description of the high-level language will be more abstract and flexible. As for whether this logic can be executed efficiently on the machine, it is often a test of the compiler. an important indicator. As an application field that has developed extremely fast in recent years, deep learning is very important for its performance optimization, and there is also a contradiction between the flexibility and abstraction of high-level descriptions and the underlying computing performance. Therefore, compilers specially designed for deep learning Appeared. Another important mission of traditional compilers is to ensure that the high-level language input by programmers can be executed on hardware computing units of different architectures and instruction sets, which is also reflected in deep learning compilers. In the face of a new hardware device, it is impossible to manually implement all the operators required for rewriting a framework for so many target hardware. The deep learning compiler provides the IR of the middle layer and converts the model flow graph of the top-level framework. The IR is represented in the middle layer, the general layer optimization is performed on the middle layer IR, and the machine code of each target platform is generally generated by the optimized IR in the back end.
The goal of the deep learning compiler is to perform performance optimization and hardware adaptation in the form of a general-purpose compiler for AI computing tasks. It allows users to focus on the development of upper-layer models, reduces the human development cost for users to manually optimize performance, and further squeezes the hardware performance space.
The bottleneck problem faced by large-scale applications
Although the deep learning compiler has developed to this day, although it has many similarities with the traditional compiler in terms of goals and technical architecture, and has shown good potential in the technical direction, the current practical application scope is still far from the traditional compiler. There are certain gaps, and the main difficulties include:
Ease of use:The original intention of the deep learning compiler is to simplify the manual optimization of performance and the labor cost of adapting hardware. However, at this stage, the challenges of large-scale deployment and application of deep learning compilers are still relatively high, and the threshold for using the compilers well is high. The main reasons for this phenomenon include:
- The problem of docking with the front-end framework. Different frameworks have different abstract descriptions and API interfaces for deep learning tasks, and have their own characteristics in terms of semantics and mechanisms, and the number of operator types of front-end frameworks that are input to the compiler is open. How to transparently support the user’s computational graph description without guaranteeing that all operators are fully supported is one of the important factors for the deep learning compiler to be widely used by users.
- Dynamic shape problems and dynamic computational graph problems. At this stage, the mainstream deep learning compilers mainly complete the compilation for specific static shape input. In addition, they can only provide limited support or no support for dynamic computing graphs containing control flow semantics. However, there are a large number of such task requirements in the application scenarios of AI. At this time, the calculation graph can only be manually rewritten into a static or semi-static calculation graph, or some subgraphs suitable for the compiler can be extracted and given to the compiler. This undoubtedly increases the engineering burden when applying deep learning compilers. A more serious problem is that many task types cannot be statically rewritten by hand, which makes the compiler completely unpractical in these cases.
- Compilation overhead problem. A deep learning compiler as a performance optimization tool is only really useful if its compilation overhead has sufficient advantages over the performance gains brought by it. In some application scenarios, the requirements for compilation overhead are relatively high. For example, a general-scale training task that takes several days to complete may not be able to accept several hours of compilation overhead. For application engineers, model debugging cannot be completed quickly when using a compiler, which also increases the difficulty and burden of development and deployment.
- Transparency to users. Some AI compilers are not fully automatic compilation tools, and their performance depends on the high-level abstract implementation template provided by the user. It is mainly to provide efficiency tools for operator development engineers and reduce the labor cost for users to manually tune various operator implementations. But this also puts forward higher requirements for the user’s operator development experience and familiarity with the hardware architecture. In addition, for software developers of new hardware, existing abstractions are often insufficient to describe the operator implementations required on innovative hardware architectures. It is necessary to carry out secondary development or even structural reconstruction of the compiler when you are sufficiently familiar with the compiler architecture, and the threshold and development burden are still very high.
Robustness:At present, most of the mainstream AI compiler projects are still experimental products, but the maturity of the products is far from industrial-grade applications. The robustness here includes whether the compilation of the input calculation graph can be successfully completed, the correctness of the calculation results, and the avoidance of extreme bad cases under the coner case in terms of performance.
Performance issues:The optimization of the compiler is essentially to replace the labor cost of manual optimization with the limited compilation overhead through the precipitation and abstraction of the generalization of the manual optimization method, or the optimization method that is not easy to be explored by manpower. However, how to precipitate and abstract the methodology is the most essential and difficult problem in the entire chain. A deep learning compiler can only truly play its value when its performance can really replace or exceed manual optimization, or can really play a role in greatly reducing labor costs.
However, it is not easy to achieve this goal. Most of the deep learning tasks are tensor-level calculations, and there are high requirements for the splitting method of parallel tasks. However, how to deposit manual optimization and generalization in the compiler technology, To avoid the explosion of compilation overhead and the linkage of optimization between different layers after layering, there are still more unknowns to be explored and mined. This has also become a problem that the next generation of deep learning compilers represented by the MLIR framework needs to think about and solve.
Main technical features of BladeDISC
The original intention of the project was to solve the static shape limitation of the current version of XLA and TVM. It was internally named DISC (DynamIc Shape Compiler), hoping to create a deep learning compiler that fully supports dynamic shape semantics that can be used in actual business.
Since the team started work on the deep learning compiler four years ago, the dynamic shape problem has always been one of the serious problems that hinder the implementation of practical business. At that time, mainstream deep learning frameworks including XLA were all compiler frameworks based on static shape semantics. The typical solution is to require the user to specify the input shape, or the compiler to capture the actual input shape combination of the subgraph to be compiled at runtime, and generate a compilation result for each input shape combination.
The advantages of the static shape compiler are obvious. When the static shape information is fully known at compile time, the Compiler can make better optimization decisions and get better CodeGen performance, as well as better memory/memory optimization plan and scheduling. Execute the plan. However, its shortcomings are also very obvious, including:
- Significantly increases compilation overhead. The offline compilation warm-up process is introduced, which greatly increases the complexity of the inference task deployment process; the training iteration speed is unstable or even the overall training time is negatively optimized.
- In some business scenarios, the shape change range tends to be infinite, resulting in the compilation cache never being able to converge and the solution unavailable.
- Increased memory usage. The extra memory and video memory occupied by the compilation cache often leads to memory/video memory OOM in the actual deployment environment, which directly hinders the actual implementation of the business.
- Mitigation solutions such as artificial padding for static shapes are not user-friendly, greatly reduce the versatility and transparency of applications, and affect iteration efficiency.

In the summer of 2020, DISC completed the first version that only supports TensorFlow front-end and Nvidia GPU back-end, and was officially put into practical application inside Alibaba. It was first put into use in several business scenarios that have been plagued by dynamic shape problems for a long time, and the expected results have been obtained. That is, it fully supports dynamic shape semantics, and its performance is almost the same as that of static shape compilers without requiring users to do special processing on computational graphs in one compilation. Compared with TensorRT and other optimization frameworks based on manual operator libraries, DISC’s technical architecture based on compiler automatic codegen has achieved obvious performance and ease-of-use advantages in practical services that are often non-standard open source models.
From the second quarter of 2020 to the present, DISC has continued to invest in research and development. In response to several bottlenecks in the distance between large-scale deployment and application of deep learning compilers from the perspective of the cloud platform mentioned above, performance, operator coverage Speed and robustness, CPU and new hardware support, front-end framework support, etc. are gradually improved. At present, in terms of scene coverage capability and performance, the team’s past work based on static shape frameworks such as XLA and TVM has been gradually replaced, and PAI-Blade has become the main optimization method for PAI-Blade to support Alibaba’s internal and external business. After 2021, the performance of DISC on the back-end hardware of the CPU and GPGPU architecture has been significantly improved, and more technical force has been invested in the support of new hardware. At the end of 2021, in order to attract more technical exchanges and cooperation and co-construction needs, as well as a wider range of user feedback, the name was officially changed to BladeDISC and the initial open source version was completed.
BladeDISC key technology
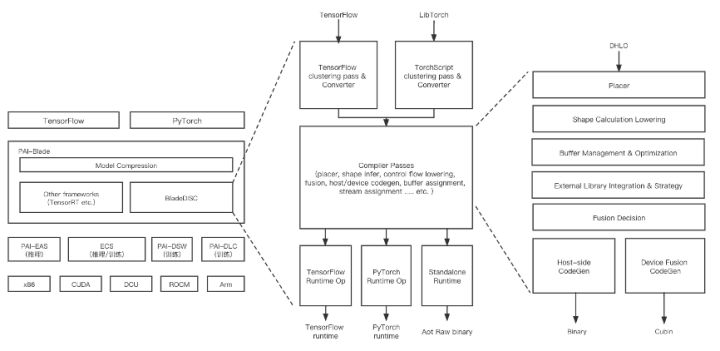
The overall architecture of BladeDISC and its context in Alibaba Cloud related products are shown in the following figure:
MLIR infrastructure
MLIR is a project initiated by Google in 2019. At its core, MLIR is a flexible multi-layer IR infrastructure and a library of compiler utilities, heavily influenced by LLVM and reusing many of its great ideas. The main reasons why we choose to be based on MLIR include its rich infrastructure support, easy-to-expand modular design architecture, and MLIR’s strong glue capability.
Dynamic shape compilation
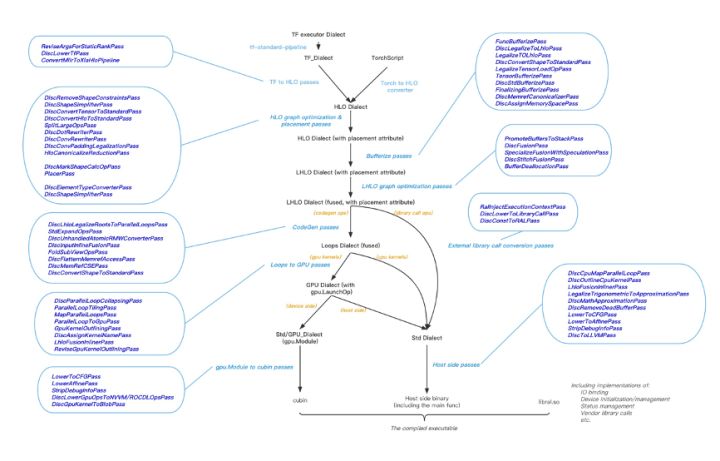
The picture above shows the main Pass Pipeline design of the BladeDISC. Compared with the current mainstream deep learning compiler projects, the main technical features are as follows:
Layer IR Design
BladeDISC chooses to access different front-end frameworks based on HLO as the core layer IR, but HLO is an IR with purely static shape semantics originally designed for XLA. In static scenarios, the shape expression in HLO IR will be static, and all shape calculations will be solidified as compile-time constants and retained in the compilation result; while in dynamic shape scenarios, IR itself needs to have enough ability to express shape calculations and Transmission of dynamic shape information. BladeDISC has maintained close cooperation with the MHLO community since the establishment of the project. Based on the HLO IR of XLA, a set of IR with complete dynamic shape expression capability has been extended, and the corresponding infrastructure and operator conversion logic of the front-end framework have been added. . This part of the implementation has been fully upstreamed to the MHLO community to ensure the consistency of IR in other MHLO-related projects in the future.
Runtime Shape Computing, Storage Management, and Kernel Scheduling
The main challenge of dynamic shape compilation comes from the need to be able to handle dynamic computational graph semantics during the static compilation process. In order to fully support dynamic shapes, the compilation results need to be able to perform real-time shape derivation calculations at runtime, not only for data calculations, but also for code generation for shape calculations. The calculated shape information is used for memory/video memory management, parameter selection during kernel scheduling, and so on. The design of BladeDISC’s pass pipeline fully considers the above-mentioned dynamic shape semantic support requirements, and adopts the scheme of host-device combined with codegen. Taking GPU Backend as an example, including shape calculation, memory/video memory application release, hardware management, and kernel launch runtime processes are all automatic code generation, in order to obtain a complete dynamic shape end-to-end support solution and more extreme overall performance.
Performance issues under dynamic shape
When the shape is unknown or partially unknown, the performance challenges faced by deep learning compilers are further magnified. On most mainstream hardware backends, BladeDISC adopts a strategy of distinguishing between compute-intensive parts and memory-intensive parts, in order to achieve a better balance between performance and complexity and compilation overhead.
For the computationally intensive part, different shapes require a more refined schedule implementation to obtain better performance. The main consideration in the design of the pass pipeline is to support the selection of appropriate operator library implementations according to different specific shapes at runtime, and Handle layout problems under dynamic shape semantics.
The automatic operator fusion of memory-intensive parts, as one of the main sources of performance benefits for deep learning compilers, also faces performance challenges when the shape is unknown. Many deterministic problems in static shape semantics, such as instruction layer vectorization, codegen template selection, whether implicit broadcast is required, etc., will face greater complexity in dynamic shape scenarios. In response to these aspects, BladeDISC chooses to sink part of the optimization decision from compile time to runtime. That is, multiple versions of the kernel implementation are generated according to certain rules at compile time, and the optimal implementation is automatically selected according to the actual shape at runtime. This mechanism, called specification, is implemented within BladeDISC based on joint host-device code generation. In addition, when there is no specific shape value at compile time, it is easy to lose a lot of optimization opportunities at various levels, from linear algebra simplification of layers, fusion decision-making to instruction-level CSE, constant folding, etc. In the design process of IR and pass pipeline, BladeDISC focuses on the abstraction of shape constraint in IR and the use of shape constraint in pass pipeline, such as the constraint relationship between different dimension sizes unknown at compile time. It plays an obvious role in optimizing the overall performance, ensuring that it can be close enough to or even exceed the performance results of the static shape compiler.
Large granularity operator fusion
Before starting the BladeDISC project, the team had made some explorations in large-granularity operator fusion and automatic code generation based on the static shape compiler.[3][4], the basic idea can be summarized as the use of shared memory with low memory access cost in GPU hardware or Memory Cache with low memory access cost in CPU to stitch calculation subgraphs of different schedules into the same kernel to realize multiple parallel loop composites , this codegen method is called fusion-stitching. This automatic code generation of memory-intensive subgraphs breaks the limitations of conventional loop fusion and input/output fusion on fusion granularity. While ensuring the quality of code generation, the fusion granularity is greatly increased, while avoiding the explosion of complexity and compilation overhead. And the whole process is completely transparent to the user, and there is no need to manually specify the schedule description.
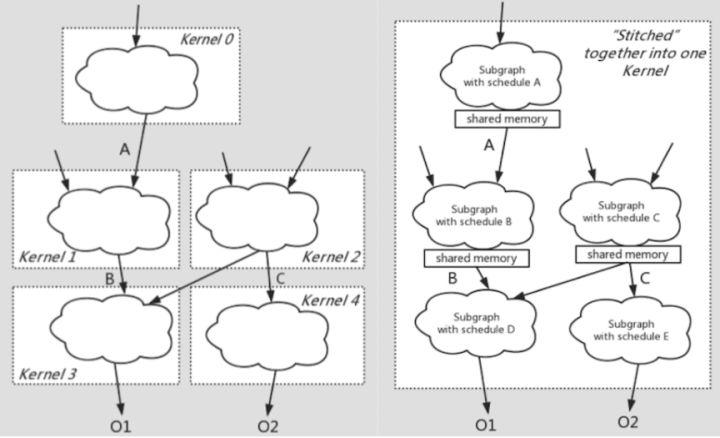
The realization of fusion-stitching under dynamic shape semantics also needs to deal with greater complexity compared with static shape semantics. The shape constraint abstraction under dynamic shape semantics simplifies this complexity to a certain extent, making the overall performance closer to or even better than manual calculation. sub-implementation.
Multiple front-end framework support
The AICompiler framework is also designed with the consideration of extending support for different front-end frameworks. The PyTorch side implements the coverage of PyTorch inference jobs by implementing a lightweight Converter to convert TorchScript to DHLO IR. The relatively complete IR infrastructure of MLIR also facilitates the implementation of Converter. BladeDISC includes the Compiler and the Bridge side for adapting to different front-end frameworks. The Bridge is further divided into two parts, the layer pass in the host framework and the runtime Op, which are connected to the host framework in the form of plug-ins. This way of working enables BladeDISC to transparently support front-end computing graphs and adapt to various versions of the user’s host framework.
Runtime environment adaptation
In order to enable the compiled results to be executed in their respective runtime environments with TensorFlow/PyTorch and other hosts, and to manage the state information that is not easily expressed by the IR layer at runtime, we have implemented a unified Compiler architecture for different runtime environments. , and introduced a runtime abstraction layer, namely the RAL (Runtime Abstraction Layer) layer.
RAL implements adaptation support for a variety of operating environments, and users can choose according to their needs, including:
- Compile the whole image and run it independently. When the entire computational graph supports compilation, RAL provides a set of simple runtime and the implementation of RAL Driver on top of this, so that the compiled results of the compiler can be run directly without the framework, reducing the framework overhead.
- TF Neutron Graph compiles and runs.
- Pytorch neutron graph compile and run.
There are differences in the above environments such as resource management, API semantics, etc. RAL abstracts a minimal set of APIs, and clearly defines their semantics to isolate the compiler from the runtime. The environment can execute the purpose of the compiled result. In addition, the RAL layer implements stateless compilation, which solves the problem of state information processing when the compiled result may be executed multiple times after the compilation of the computational graph. On the one hand, it simplifies the complexity of code generation, and on the other hand, it is easier to support multi-threaded concurrent execution (such as inference) scenarios, and it is also easier to support error handling and rollback.
Application scenarios
The typical application scenarios of BladeDISC can be divided into two categories: one is to be used as a general and transparent performance optimization tool on mainstream hardware platforms (including Nvidia GPU, x86 CPU, etc.), reducing the manpower of users to deploy AI jobs burden, and improve the efficiency of model iteration; another important application scenario is to help new hardware in the adaptation and access support of AI scenarios.
At present, BladeDISC has been widely used in many different application scenarios of Alibaba internal and external users on Alibaba Cloud, covering model types involving NLP, machine translation, voice ASR, voice TTS, image detection, recognition, AI for science, etc. Typical AI applications; covered industries include Internet, e-commerce, autonomous driving, security industry, online entertainment, medical and biological, etc.
In inference scenarios, BladeDISC and inference optimization tools provided by manufacturers such as TensorRT form a good technical complementarity. The main differentiating advantages include:
- Complete dynamic shape semantic support for dynamic shape business
- The performance advantage of model generalization based on compiler based technology path over non-standard models
- More flexible deployment mode selection, supporting the transparency advantages of front-end frameworks in the form of plug-ins
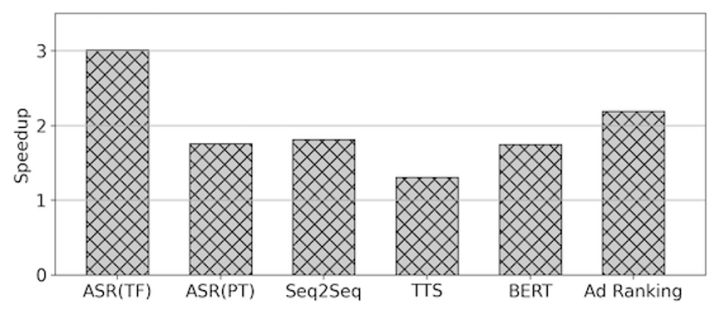
Below are the performance gain numbers for several real business examples on Nvidia T4 hardware:
In terms of new hardware support, the current general situation is that in addition to the relatively deep accumulation of Nvidia and other leading manufacturers, including ROCM and other GPGPU hardware, the general situation is that the hardware indicators are already quite competitive, but the manufacturers are subject to AI. The accumulation on the software stack is relatively small, and there is a general problem that the hardware computing power cannot be exerted, which makes it difficult to implement the hardware application. As mentioned above, the compiler-based technology path naturally has a certain generalization capability for the back-end of the hardware, and forms a relatively strong complementarity with the technical reserves of the hardware manufacturers. BladeDISC currently has relatively mature reserves on GPGPU and general-purpose CPU architectures. Taking GPGPU as an example, most of the technology stack on Nvidia GPU can be migrated to hardware with similar architecture such as Haiguang DCU and AMD GPU. BladeDISC’s strong hardware generalization capability, combined with the strong versatility of the hardware itself, solves the performance and usability problems of new hardware adaptation.
The following figure shows the performance figures of several real business examples on Haiguang DCU:
| A recognition class model | reasoning | 2.21X ~ 2.31X under different batch sizes |
| A detection class model A | reasoning | 1.73X ~ 2.1X under different batch sizes |
| A detection class model B | reasoning | 1.04X ~ 1.59X under different batch sizes |
| a molecular dynamics model | train | 2.0X |
Open Source Ecology: Concept and Future
We decided to build an open source ecosystem mainly for the following considerations:
BladeDISC originated from the business needs of the Alibaba cloud computing platform team. During the development process, discussions and exchanges with community peers such as MLIR/MHLO/IREE gave us good input and reference. While we are gradually improving with the iteration of business needs, we also hope to open source to the community. At present, there are many experimental projects in the entire AI compiler field, and there are few products with strong practicality, and the work between different technology stacks In a relatively fragmented situation, I hope to be able to give back my own experience and understanding to the community as well, and I hope to have more and better communication and co-construction with developers of deep learning compilers and practitioners of AI System. This industry contributes our technical strength.
We hope that with the help of open source work, we can receive more user feedback in real business scenarios to help us continue to improve and iterate, and provide input for the direction of subsequent work investment.
In the future, we plan to regularly release the Release version in two-month units. BladeDISC’s recent Roadmaps are as follows:
- Ongoing robustness and performance improvements
- The x86 backend complements the support of computationally intensive operators, and the end-to-end complete open source x86 backend support
- Large granularity automatic code generation based on Stitching on GPGPU
- AMD rocm GPU backend support
- Support for PyTorch training scenarios
In addition, in the medium and long term, we will continue to invest energy in the following exploratory directions, and welcome feedback and improvement suggestions from various dimensions as well as technical discussions. At the same time, we welcome and look forward to colleagues who are interested in open source community construction. Participate in co-construction.
- More support and adaptation of new hardware architectures, as well as the precipitation of software-hardware collaboration methodology under new hardware architectures
- Automatic code generation of computationally intensive operators and exploration of global layout optimization under dynamic shape semantics
- Optimization exploration of sparse subgraphs
- Exploration of runtime scheduling strategy and memory/video memory optimization under dynamic shape semantics
- Technology Exploration of Model Compression and Compilation Optimization
- Support and optimization of more AI job types, such as graph neural networks, etc.
BaldeDISC project address: https://github.com/alibaba/BladeDISC
More open source project collections:https://www.aliyun.com/activity/bigdata/opensource_bigdata__ai
references
1. “DISC: A Dynamic Shape Compiler for Machine Learning Workloads”, Kai Zhu, Wenyi Zhao, Zhen Zheng, Tianyou Guo, Pengzhan Zhao, Feiwen Zhu, Junjie Bai, Jun Yang, Xiaoyong Liu, Lansong Diao, Wei Lin
2. Presentations on MLIR Developers’ Weekly Conference: 1, 2
3. “AStitch: Enabling A New Multi-Dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures”, Zhen Zheng, Xuanda Yang, Pengzhan Zhao, Guoping Long, Kai Zhu, Feiwen Zhu, Wenyi Zhao, Xiaoyong Liu , Jun Yang, Jidong Zhai, Shuaiwen Leon Song, and Wei Lin. The 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2022. [to appear]
4. “FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads”, Zhen Zheng, Pengzhan Zhao, Guoping Long, Feiwen Zhu, Kai Zhu, Wenyi Zhao, Lansong Diao, Jun Yang, and Wei Lin. arXiv preprint
#Alibabas #BladeDISC #Deep #Learning #Compiler #Officially #Open #Source