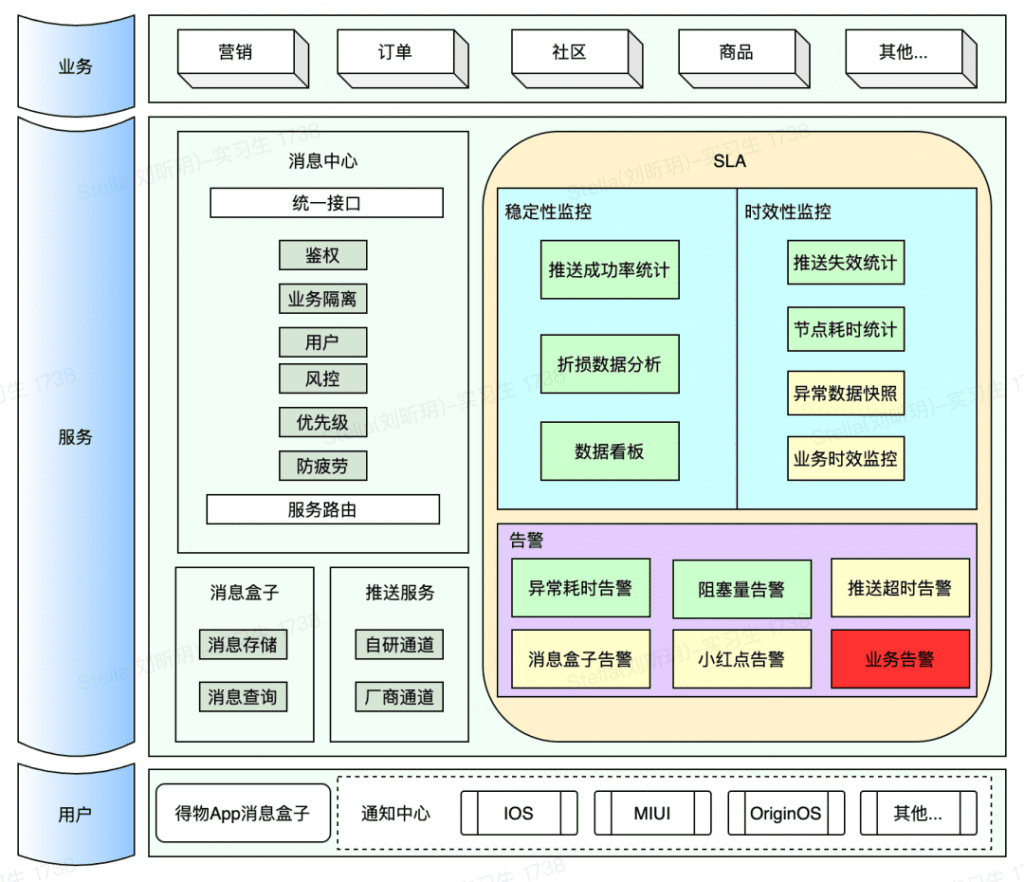
Dewu Message Center pushes hundreds of millions of messages to Dewu users every day, and guides millions of effective users to click every day, providing a powerful, efficient and low-cost user access channel for Dewu App. In such a huge system, how to monitor the stability of the system, ensure that faults are detected as early as possible, and respond in a timely manner is crucial. To this end, we have built the SLA system of the Dewu Message Center. The related architecture is shown in the figure:

This article mainly introduces how we implement the SLA monitoring system, and reconstruct and optimize it step by step, and share it with you as a summary of past work experience.
Dewu News Center mainly undertakes news push requests of upstream businesses, such as marketing push, product promotion, order information, etc. After the message center accepts the business request, it will execute[message content inspection, anti-fatigue, anti-duplication, user information query, manufacturer push]and other nodes according to the business needs, and finally touch the online push channel developed by each mobile phone manufacturer and Dewu. reach users. The overall push process is simplified as follows:

We hope to provide accurate SLA monitoring indicators and alarm capabilities for each node, so as to ensure the stability of the overall system. Here are some of the metrics we designed:
Monitoring indicators
Node push amount
Node push time
Node time-consuming compliance rate
Overall time-consuming compliance rate
Node blocking amount
Other indicators
Alarm capability
Node time-consuming alarm
Node blocking amount alarm
Other Alerting Capabilities
So how do we achieve statistics on these indicators? The simplest solution is to add statistical codes to the entry and exit of each node, as follows:

this is our Scenario 0 We used this solution to quickly implement the development of SLA-node push number statistics. However, the shortcomings of this scheme are also obvious. Consider the following issues:
How to achieve another SLA metric development? For example, node time-consuming statistics, it is also necessary to add statistical code inside the method of each node.
What if there are new nodes that need to do SLA statistics? All statistical indicators need to be implemented again on the new node.
How to avoid the failure of the main push process due to abnormal SLA statistics logic? Add try{}catch() everywhere to catch exceptions?
How to divide labor? In addition to node time-consuming statistics, there are many other indicators to be implemented. The simplest way of division of labor is to divide labor according to SLA indicators, and each lead several indicators to develop. The problem is that the statistical logic of each indicator is coupled together, and it is practically impossible to divide labor according to statistical indicators.
The poor division of labor in project development usually means that the code coupling is too high, which is a typical bad code smell and needs to be refactored in time.
From the above questions, we conclude that Scenario 0 Several pain points, and the goal of our subsequent refactoring.
2.1 Pain points
In the process of project development, there are often long-term disputes and no solution can be found. The reason is often that everyone does not understand the basic concepts well, and everyone talks about it. This is the time to stop arguing decisively, first give a consistent definition of the basic concepts, and then start the discussion. Vague concepts are the mortal enemy of effective communication.
Maintenance is difficult.
The statistics of each node need to modify the code of the business node, and the statistical code is scattered in each node of the whole system, which is very troublesome to maintain;
At the same time the main logic of the push process is submerged in the statistics code. The typical code is as follows, one-third of a business method may be the code for SLA statistics.
protected void doRepeatFilter(MessageDTO messageDTO) {
//业务逻辑:防重复过滤
//...
//业务逻辑:防重复过滤
if (messageSwitchApi.isOpenPushSla && messageDTO.getPushModelList().stream()
.anyMatch(pushModel -> pushModel.getReadType().equals(MessageChannelEnums.PUSH.getChannelCode()))) {
messageDTO.setCheckRepeatTime(System.currentTimeMillis());
if (messageDTO.getQueryUserTime() > 0) {
long consumeTime = messageDTO.getCheckRepeatTime() - messageDTO.getQueryUserTime();
//SLA耗时统计逻辑
messageMonitorService.monitorPushNodeTimeCost(
MessageConstants.MsgTimeConsumeNode.checkRepeatTime.name(), consumeTime, messageDTO);
}
}
}affect performance
The SLA monitoring logic is all processed in the push thread, and some monitoring statistics are time-consuming, reducing the push efficiency.
The statistical code will frequently write to the Redis cache, which puts a lot of pressure on the cache. It is best to write some data into the local cache and merge it into Redis regularly.
Difficult to scale
2.2 Objectives
After clarifying the problem, we propose the following reconstruction goals for the existing defects of the system:
The main process belongs to the main process, and the SLA belongs to the SLA.
The SLA monitoring code is separated from the main process logic to completely avoid the pollution of the SLA code to the main process code.
Asynchronous execution of SLA logical calculation, independent of the main process of push business, to prevent abnormal SLA from dragging down the main process.
The calculation of different monitoring indicators is independent of each other to avoid code coupling.
The SLA monitoring code is developed once and reused everywhere.
Quickly support the implementation of new monitoring metrics.
To reuse existing monitoring indicators to new nodes, the ideal way is to add an annotation to the node method to achieve statistics and monitoring of the node.
3.1 Node Definition
SLA is implemented based on nodes, so the concept of nodes does not allow for ambiguity. So before the refactoring started, we fixed the concept of nodes in the form of code.
public enum NodeEnum {
MESSAGE_TO_PUSH("msg","调用推送接口"),
FREQUENCY_FILTER("msg","防疲劳"),
REPEAT_FILTER("push","防重复"),
CHANNEL_PUSH("push","手机厂商通道推送"),
LC_PUSH("push","自研长连推送")
//其他节点...
}
3.2 AOP
Next, consider decoupling the main process code and the SLA monitoring code. The most direct way is of course AOP.

The above is the optimized design diagram of node time-consuming statistics. Take each push node as an AOP cut point, and migrate the SLA statistics on each node to AOP for unified processing. At this point, the decoupling of the SLA code and the main process code is achieved. But this is only the first step in the Long March. What if there is additional statistical logic to implement? Do you want to pile it all up in AOP code?
3.3 Observer Pattern
SLA has many statistical indicators. We don’t want to pile up the statistical logic of all the indicators. So how to decouple it? The answer is the observer pattern. We issue a node entry event (EnterEvent) before the AOP pointcut, and issue a node exit event (ExitEvent) after the pointcut exits. The statistical logic of each indicator is abstracted into a node event handler. Each processor listens to node events to achieve logical decoupling between statistical indicators.

3.4 Adapters
There is one more issue to consider here. The output and input parameters of each node are inconsistent. How can we unify the input and output parameters of different nodes into an event object for distribution? If we directly judge the node to which the pointcut belongs in the AOP code, take out the parameters of the node, and then generate the event object, then the logical complexity of AOP will expand rapidly and need to be changed frequently. A better way is to apply the adapter pattern. AOP is responsible for finding the adapter corresponding to the pointcut, and the adapter is responsible for converting node parameters into event objects, so the scheme evolves as follows:

Now we have found a corresponding solution to each problem, and then string these solutions together to form a complete reconstruction scheme. After refactoring, the SLA logic flow is as follows:

Here the overall design of the program is completed. Before the implementation, it is necessary to design the scheme in synchronization with the relevant members of the scheme, sort out the potential risks, and divide the labor. When it comes to the reconstruction of the whole process, it is difficult to guarantee the completeness and effectiveness of the evaluation of the plan only with a paper plan. We hope to verify the feasibility of the plan, expose the technical risks of the plan as soon as possible, and ensure that there is no major deviation in the understanding of the plan by the project-related partners. A good way to recommend here is to provide a solution prototype.
4.1 Prototype
A solution prototype is the simplest realization of an existing solution, which is used for technical evaluation and solution description.
As the so-called talk is cheap, show me the code. For programmers, no matter how perfect the design is, no executable code is convincing. It took us about two hours to quickly implement a prototype based on an existing design. The prototype code is as follows:
public class EventAop {
@Autowired
private EventConfig eventConfig;
@Autowired
private AdaptorFactory adaptorFactory;
@Around("@annotation(messageNode)")
public Object around(ProceedingJoinPoint joinPoint, MessageNode messageNode) throws Throwable {
Object result = null;
MessageEvent enterEvent = adaptorFactory.beforProceed(joinPoint, messageNode);
eventConfig.publishEvent(enterEvent);
result = joinPoint.proceed();
MessageEvent exitEvent = adaptorFactory.postProceed(joinPoint, messageNode);
eventConfig.publishEvent(exitEvent);
return result;
}
}
public class EventConfig {
@Bean
public ApplicationEventMulticaster applicationEventMulticaster() { //@1
//创建一个事件广播器
SimpleApplicationEventMulticaster result = new SimpleApplicationEventMulticaster();
return result;
}
public void publishEvent(MessageEvent event) {
this.applicationEventMulticaster().multicastEvent(event);
}
}
public class MessageEvent extends ApplicationEvent {}
public class AdaptorFactory {
@Autowired
private DefaultNodeAdaptor defaultNodeAdaptor;
//支持切点之前产生事件
public MessageEvent beforeProceed(Object[] args, MessageNode messageNode) {
INodeAdaptor adaptor = getAdaptor(messageNode.node());
return adaptor.beforeProceedEvent(args, messageNode);
}
//支持切点之后产生事件
public MessageEvent afterProceed(Object[] args, MessageNode messageNode, MessageEvent event) {
INodeAdaptor adaptor = getAdaptor(messageNode.node());
return adaptor.postProceedEvent(args, event);
}
private INodeAdaptor getAdaptor(NodeEnum nodeEnum) {
return defaultNodeAdaptor;
}
}
4.2 Technical Review
On the basis of the overall scheme and prototype code, we also need to review the technology used in the scheme, whether there are risks, and assess the impact of these risks on existing functions, division of labor and scheduling. For example, we mainly use Spring AOP and Spring Event mechanism, then they may potentially have the following problems, which need to be evaluated before development:
Problem with Spring AOP: Private methods in Spring AOP cannot be enhanced. The bean itself cannot be enhanced by calling its own public methods.
The problem with Spring Event: The default event processing and event distribution run in the same thread. When implementing, you need to configure the Spring event thread pool to separate the event processing thread from the business thread.
Potential technical issues are fully communicated. The technical background of each member is different, and the technical problems that are very simple in your eyes may not be solved by others in half a day. Solution designers should fully anticipate potential technical problems, communicate in advance, and avoid unnecessary troubleshooting, thereby improving development efficiency.
4.3 Cost benefit analysis
A complete set of solutions considers not only technical feasibility, but also implementation costs. We use a table to briefly illustrate the cost comparison before and after my reconstruction.
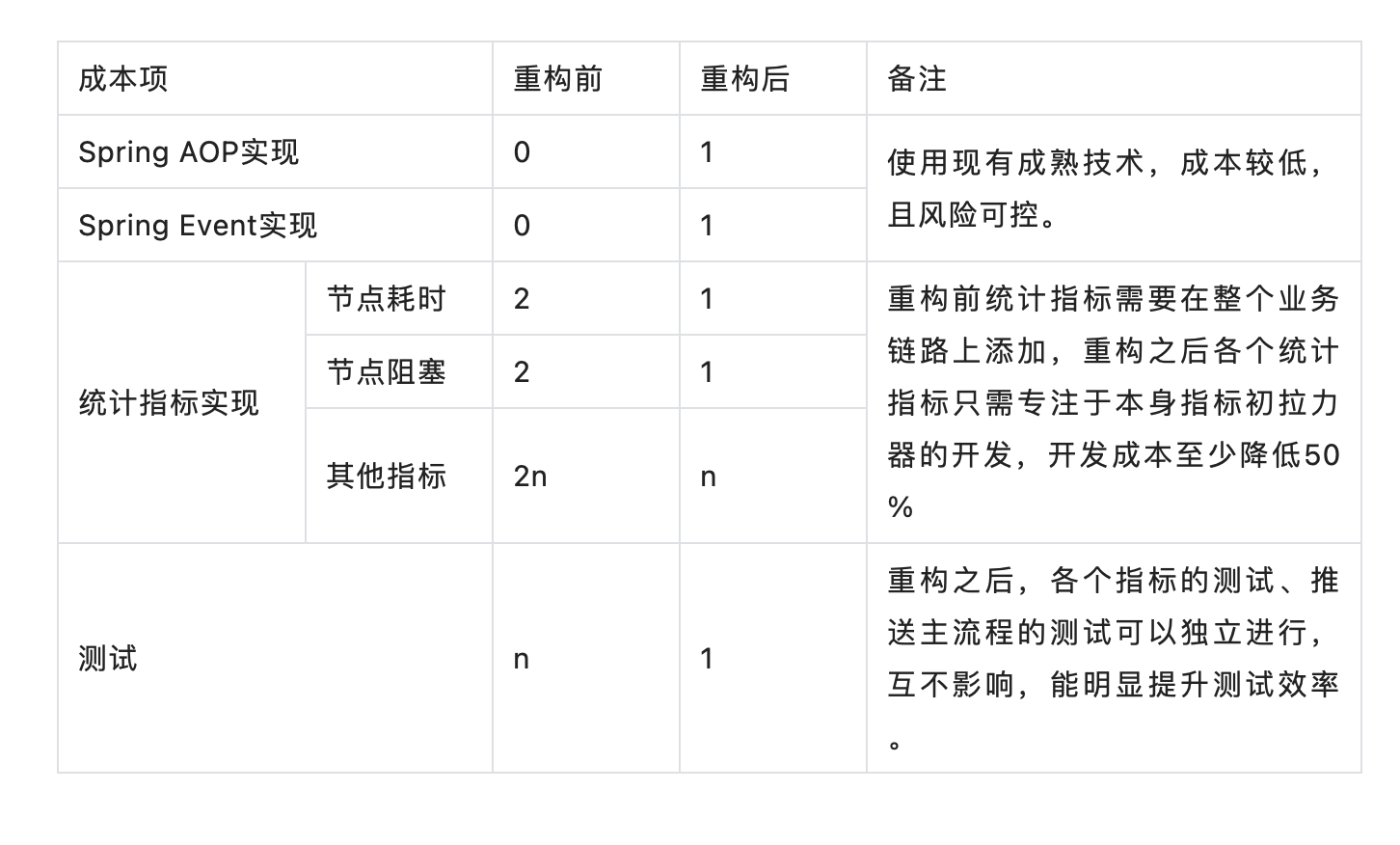
-
income
Code is clear. SLA statistical logic and process logic are decoupled. The statistics of various SLA indicators are completely decoupled and independent of each other.
Improve development efficiency. SLA indicator statistics are developed once and reused everywhere. Just add node annotations to the code that needs to be monitored.
Improve performance. SLA logic is executed in a separate thread and does not affect the main process.
Improve stability. The SLA logic is decoupled from the main process. Frequent SLA changes will not affect the main process code, nor will the main process be dragged down due to SLA exceptions.
Facilitate division of labor and scheduling. Refactoring also solves the problem of poor division of labor. Since each indicator achieves logical isolation through refactoring, it can be developed independently during implementation. Therefore, we can simply arrange the division of labor according to the SLA statistical indicators.
The hardest part of code refactoring is not the technology, but the decision. Deciding whether and when to refactor the system is the hardest part. Often a team will spend a lot of time debating whether to refactor, but in the end no one dares to make the final decision. The difficulty is due to the lack of decision-making materials. We can consider introducing decision-making tools such as cost-benefit statement to conduct qualitative and quantitative analysis of reconstruction to help us make decisions.
Some interesting pits encountered in the process of implementation are listed below for your reference.
5.1 AOP failure
Spring AOP uses cglib and jdk dynamic proxies to implement proxy enhancements to raw bean objects. Either way, a proxy object will be generated for the original bean object. When we call the original object, we actually call the proxy object first, the proxy object performs the slicing logic, and uses reflection to call the method of the original object, which actually runs as follows code.
public static Object invokeJoinpointUsingReflection(@Nullable Object target, Method method, Object[] args) throws Throwable {
//使用反射调用原始对象的方法
ReflectionUtils.makeAccessible(method);
return method.invoke(target, args);
}At this time, if the called method is a method of the original object itself, the proxy object will not be called. This results in the proxy object logic not being executed and thus not triggering code enhancements. For the specific principle, refer to the following example. Suppose we have a service implementation class AServiceImpl, which provides two methods: method1() and method2(). where method1() calls method2().
@Service("aService")
public class AServiceImpl implements AService{
@MessageNode(node = NodeEnum.Node1)
public void method1(){
this.method2();
}
@MessageNode(node = NodeEnum.Node2)
public void method2(){
}
}Our AOP code is weaved into statistical logic via the @MessageNode annotation as a pointcut.
@Component("eventAop")
@Aspect
@Slf4j
public class EventAop {
@Around("@annotation(messageNode)")
public Object around(ProceedingJoinPoint joinPoint, MessageNode messageNode) throws Throwable {
/**
节点开始统计逻辑...
**/
//执行切点
result = joinPoint.proceed();
/**
节点结束统计逻辑...
**/
return result;
}
}When Spring starts, the IOC container will generate two instances for AserviceImpl, one is the original AServiceImpl object, and the other is the enhanced ProxyAserviceImpl object. The method method1 is called as follows. You can see that the method2() method is called from method1(). When the proxy object is not used, the method2() method of the target object is called directly.

5.1.1 Solution
The sample code is as follows:
@Service("aService")
public class AServiceImpl implements AService{
@Autowired
@Lazy
private AService aopSelf;
@MessageNode(node = NodeEnum.Node1)
public void method1(){
aopSelft.method2();
}
@MessageNode(node = NodeEnum.Node2)
public void method2(){
}
}- The above methods treat the symptoms but not the root causes. Let’s explore from the ground up why self-invoking code enhancements occur? The reason is that we want to perform SLA statistical enhancements on two different nodes. However, the methods of these two nodes are defined in the same Service class, which obviously violates the single function principle of coding. So a better way should be to abstract out a separate class to deal with. code show as below:
@Service("aService")
public class AServiceImpl implements AService{
@Autowired
private BService bService;
@MessageNode(node = NodeEnum.Node1)
public void method1(){
bService.method2();
}
}
@Service("bService")
public class BServiceImpl implements BService{
@MessageNode(node = NodeEnum.Node2)
public void method2(){
}
}Refactoring can help us find and locate bad code smells, so as to guide us to re-abstract and optimize bad code.
5.2 Common dependency packages
Another problem encountered in the implementation is how to provide common dependencies. Because there are many different microservices in the message center, for example, we have the Message service that undertakes external business push requests, and the Push service that forwards business requests to various mobile phone manufacturers, and after the push arrives, the Dewu App is marked with red. Point of Hot services, etc., these services need to do SLA monitoring. At this time, it is necessary to abstract the existing solution from public dependencies for use by various services.
Our approach is to abstract[node definition, AOP configuration, Spring Event configuration, node adapter interface class]into a common dependency package, and each service only needs to rely on this common package to quickly access SLA statistics capabilities.
There is a more interesting point here, such as[AOP configuration, Spring Event configuration, node adapter]should the configuration of these beans be open to each service to configure itself, or should the configuration be provided by default in the common package? For example, the following bean configuration determines the key configuration items of the Spring Event processing thread pool, such as the number of core threads and the size of the buffer pool.
@Bean
public ThreadPoolExecutorFactoryBean applicationEventMulticasterThreadPool() {
ThreadPoolExecutorFactoryBean result = new ThreadPoolExecutorFactoryBean();
result.setThreadNamePrefix("slaEventMulticasterThreadPool-");
result.setCorePoolSize(5);
result.setMaxPoolSize(5);
result.setQueueCapacity(100000);
return result;
}This configuration is handed over to each service for its own management, which will be more flexible, but at the same time, it means that the service cost of using the common package is also higher, and the user of the common package needs to decide the configuration content. On the contrary, if it is provided directly in the common package, the flexibility is reduced, but it is convenient to use. Later, referring to the design specification that Spring Boot conventions are greater than configuration, it is still decided to provide configuration directly in the common package. The logic is that the requirements of each service for these configurations will not be much different. For this flexibility, it is not necessary to increase the cost of use. . Of course, if there are subsequent services that really need different configurations, they can also be flexibly supported according to practical needs.
Convention over configuration, also known as convention over configuration, also known as programming by convention, is a software design paradigm that reduces the number of decisions software developers need to make, and obtains simple benefits without Loss of flexibility.
We all know that the concepts of Spring and Spring Boot are very advanced, and in practice, being able to learn from advanced concepts to guide development practice is also a kind of happiness for engineers.
After the code is implemented, steps such as performance stress testing, online grayscale publishing, and online data observation are carried out, which will not be repeated here. So when the SLA technology has evolved here, what business results have we obtained for our push business? Typical results are provided below.
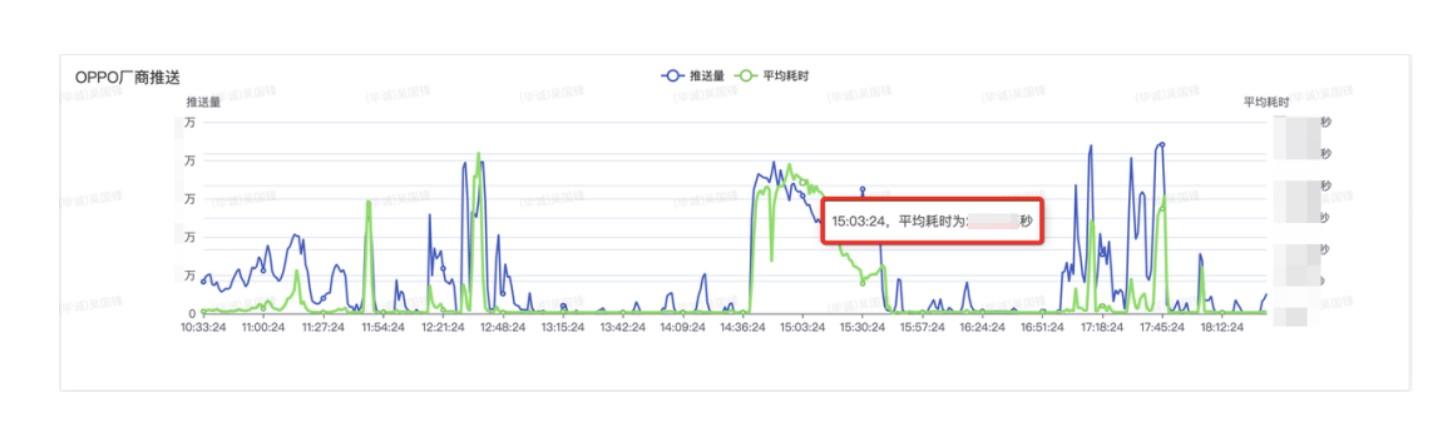
The message push service will call the mobile phone manufacturer’s push service interface. What should we do if we want to monitor the time-consuming performance of the manufacturer’s push interface? Before refactoring, we need to add statistical code before and after each vendor pushes the interface, which takes time to calculate and writes to the cache. After the refactoring, all we have to do is simply add a node annotation. For example, if we want to count the SLA indicators of the OPPO push interface, we only need to add the following annotations:
@MessageNode(node = NodeEnum.OPPO_PUSH, needEnterEvent = true)
public MessageStatisticsDTO sendPush(PushChannelBO bo) {
if (bo.getPushTokenDTOList().size() == 1) {
return sendToSingle(bo);
} else {
return sendToList(bo);
}
}Then we can quickly find the statistics pushed by OPPO on the console. For example, we see that the OPPO push bottleneck on the console takes 20s, which means that the OPPO push connection must have timed out, and the configuration of the connection pool needs to be optimized.
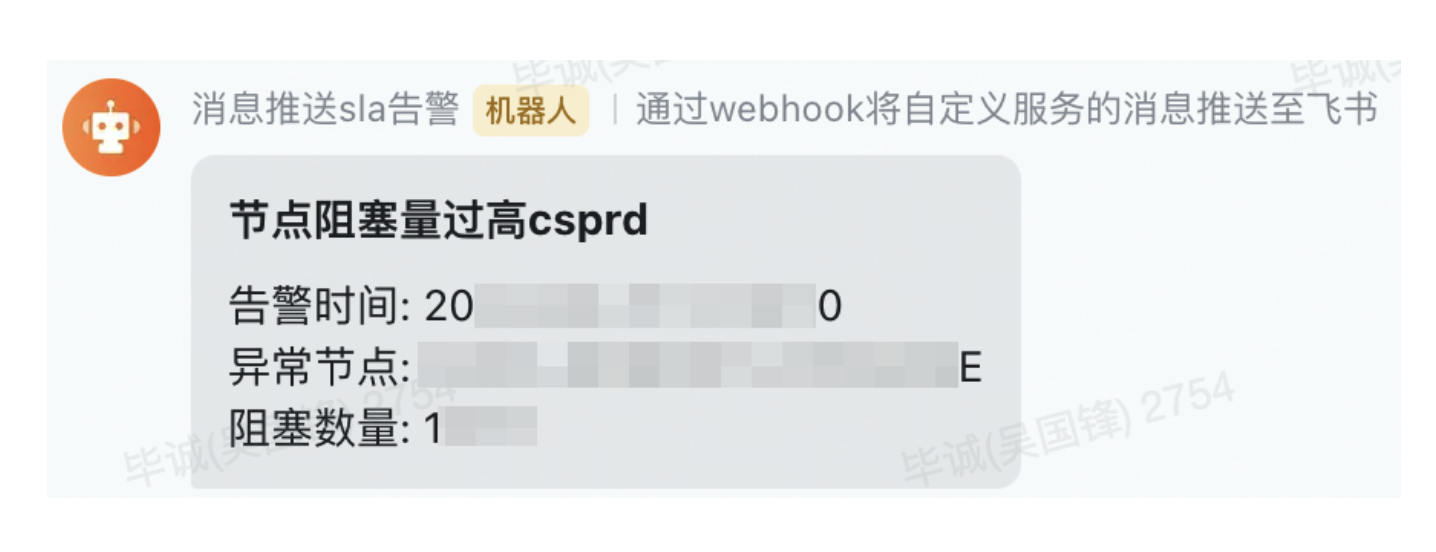
In addition to monitoring indicators, we also support real-time alarms. For example, the following node blocking alarm, we can timely detect the accumulation of many nodes in the system, and quickly check whether the nodes are stuck or whether the upstream call volume is soaring, so as to eliminate potential online problems. strangled in the cradle.
Within a week of the launch of SLA, we have already relied on this technology to find potential problems in the system, but in fact, we can have more room for imagination about the business benefits of SLA. For example:
We are currently monitoring mainly technical indicators, such as node time-consuming, node blocking, etc. Later, we can also support business-related statistics, and we can quickly locate which business party’s call caused the system to block and other business performance data.
Secondly, we can count the ROI data pushed by each business. Currently, the message service supports hundreds of millions of messages, but there is no clear indicator of which pushes have high returns and which ones have low returns. We can collect information such as the push volume and click volume of each business to calculate the ROI indicator of business push.
When we have business performance data and business ROI indicators, we have the opportunity to refine the management and control of business push. For example, if push resources are tight today, can I suspend business push with low ROI? For example, high ROI push has already reached users today, can we cancel similar push of the day to prevent disturbing users, etc.
These are the directions that the message center SLA can push and empower the business, and these directions can be implemented quickly and at low cost based on the current SLA technical architecture, truly realizing that technology serves business and technology promotes business.
The above is the whole process of the reconstruction and evolution of the message center SLA. For message services, there is no end to the development of SLA. We must continue to pay attention to the core indicators of the system and constantly improve monitoring tools. Because of this, we need to consolidate the technical foundation of SLA and realize more complex functions on a flexible and lightweight technical base. Looking back at this refactoring process, we also summarize the following experiences for your reference.
Don’t be afraid to refactor and don’t overdesign. The purpose of refactoring is not to show off skills, but to solve practical problems and improve development efficiency.
Have a prototype. Complex designs are often difficult to develop, and the solution is to start with minimal practice. Prototype is the minimal practice of program design. After reviewing the design after the prototype, it will be much more convenient to evolve the program.
Full control of technology. Predict the potential risks of the technology used and ensure that there are sufficient technical capabilities to solve them. In addition, risks should be exposed to team members in advance to reduce the chance of stepping on pits and avoid unnecessary development and debugging costs.
*arts/Wu Guofeng
Pay attention to Dewu Technology, and update technical dry goods at 18:30 every Monday, Wednesday, and Friday night
If you think the article is helpful to you, please comment, forward and like~
#Stability #monitoring #practice #hundreds #millions #pushes #day