Google published a blog post last week introducing an open source C++ and Python library, TensorStore, that developers can use to store and manipulate multidimensional data, designed to better manage and process large data by set to solve key engineering challenges in scientific computing.

Various applications in computer science and machine learning today operate on cubes that span a single coordinate system. In these applications, a single dataset can require petabytes of storage, and processing such datasets can be challenging as users may receive and write data at different scales and at unpredictable intervals .
TensorStore provides a simple Python API to load and process large data arrays. Arbitrarily large underlying data sets can be loaded and manipulated without the need to store the entire data set in memory, because before requesting exact sharding, TensorStore does not read the actual data or keep it in memory. This can be achieved with indexing and operation syntax, which is basically the same as that used for NumPy operations.
TensorStore also supports a variety of storage systems such as Google Cloud, local and network file systems, and more. It provides a unified API to read and write different array types (such as zarr and N5). With strong atomicity, isolation, consistency, and durability (ACID) guarantees, the library also provides read/writeback caching and transactions.
In addition, the concurrency of TensorStore ensures the safety of parallel operations when many machines access the same dataset. It remains compatible with various underlying storage layers without severely impacting performance.
The researchers mentioned that processing and analyzing large numerical datasets requires significant computational resources, typically done by parallel operations among a large number of CPUs or accelerator cores distributed across multiple devices. Often also spread across numerous machines. The fundamental goal of TensorStore is to be able to safely parallelize individual datasets so that these datasets are not corrupted or inconsistent due to parallel access patterns, while maintaining high performance. In fact, a test in Google’s data centers found that read and write performance increased almost linearly as the number of CPUs increased.
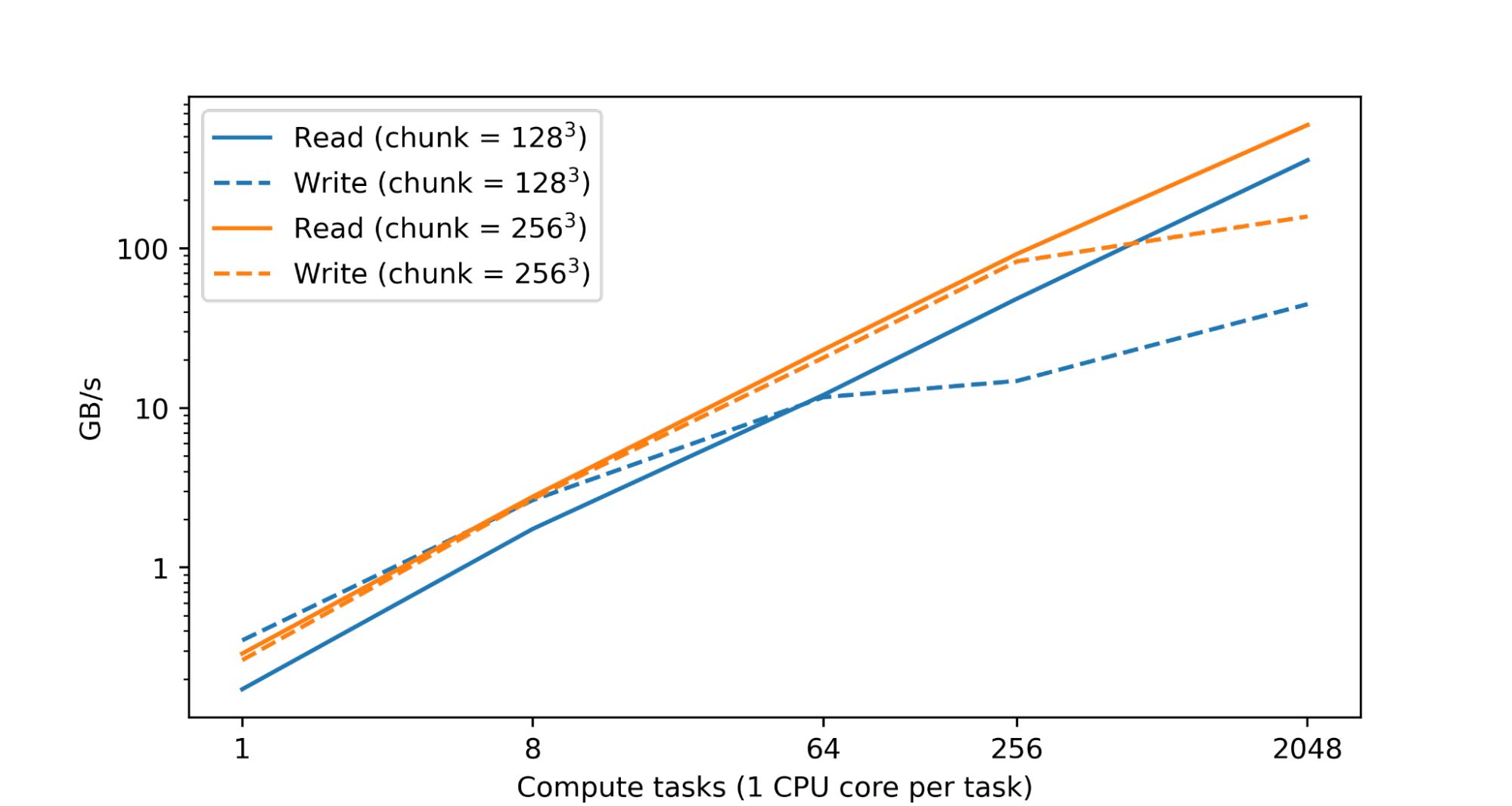
TensorStore also has an asynchronous API that allows programs to continue reading or writing in the background while they are doing other tasks. TensorStore also integrates with parallel computing frameworks such as Apache Beam and Dask to make TensorStore’s distributed computing compatible with many current data processing workflows.
Use cases for TensorStore include language models, which can efficiently read and write model parameters during training, and brain mapping, where high-resolution maps depicting brain nerves are stored.
Project Github address: https://github.com/google/tensorstore
#Google #open #source #TensorStore #designed #reading #writing #large #multidimensional #data #News Fast Delivery