In recent years, there has been a clear trend in the research and application of artificial intelligence at home and abroad.AIThe application’s improvement of models and algorithms is currently reaching a bottleneck, and it is currently changing from traditionalModel-centric(i.e. model-centric), in the direction ofData-centric(Data-centric) transformation.
Formerly the director of Stanford University’s artificial intelligence laboratory, the head of Google’s artificial intelligence brain and the chief artificial intelligence scientist of Baidu, a well-known scholar in the industryAndrew Ng(Wu Enda) Professor2021in the United States through his foundingDeepLearning.AIDelivered an online speech on the topic of “MLOps:From Model-centric to Data-centric AI, which has caused a lot of repercussions in the artificial intelligence industry.In his speech, he believed that the current situation of implementing artificial intelligence in the industry is to improve the effect through model tuning, which is far inferior to the effect improvement brought by data quality tuning.AIThe landing trend is fromModel-centricTowardsData-centricmake the transition.
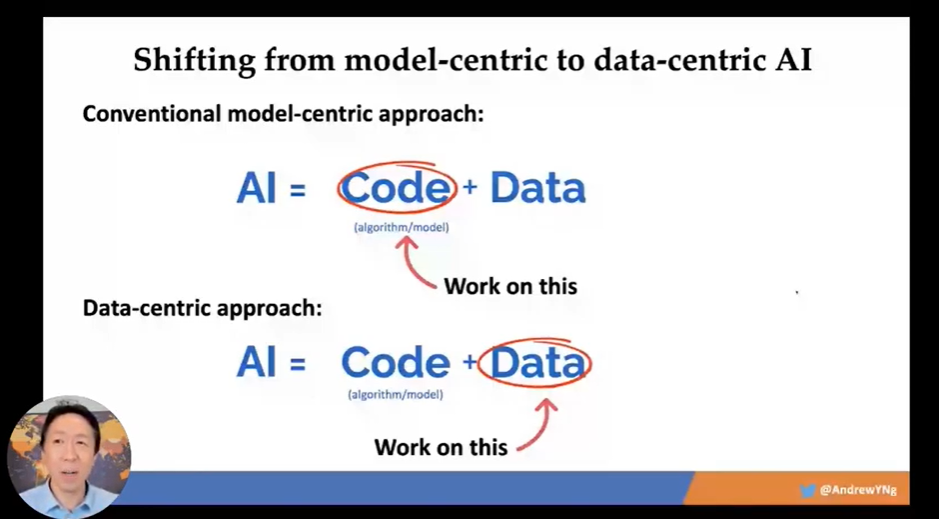
Specifically, usingModel-centricThe method is to keep the data unchanged and constantly adjust the model algorithm, such as using more and deeper network layers, more hyperparameter adjustments, etc., the improvement space for the final result is already very small; on the contrary, usingData-centricThe method is to keep the model algorithm unchanged, and spend energy on improving data quality, such as improving data labels, improving data labeling quality, maintaining data consistency at various stages, etc., but it is easy to achieve better results.for the sameAIThe problem, improving the model or improving the data, the effect is completely different.
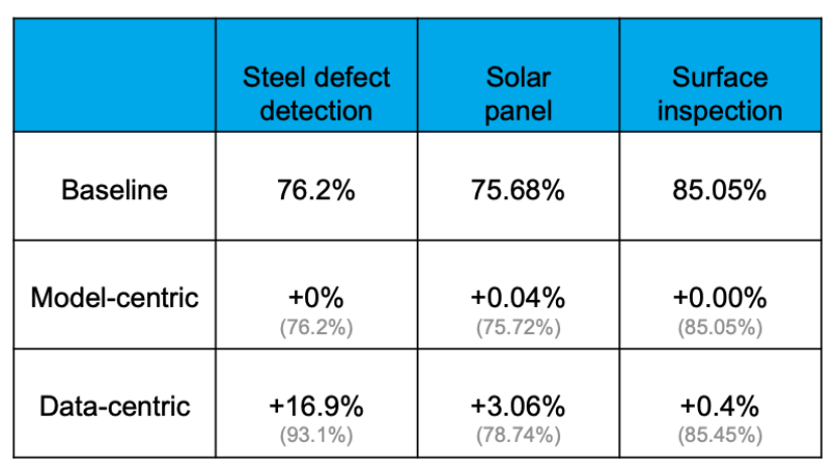
For example, in the following steel plate defect detection task, the accuracy of the baseline is76.2%.useModel-centricmethod, that is, after various operations of changing the model and adjusting the parameters, the improvement of the accuracy rate is very small. The three examples are:+0%,+0.04%,+0%, the final effect has almost no improvement.But usingData-centricmethod, that is, keeping the model algorithm unchanged, optimizing the data (including introducing more data, improving data quality, etc.), the final result is that the accuracy of the model is improved by a much larger margin. The three examples are:+16.9%,+3.06%,+0.4%(Don’t underestimate the improvement of a dozen or a few points, which is very rare in the process of model tuning.) For comparison, useData-centricThe method is better than the adoption of the effect improvement.Model-centricMethods.
This happens because data is far more important than imagined,everybody knows“Data is Food for AI”,Express it with a simple formula.
in a realAIIn application, there are probably80%time is spent processing data-related content, and the rest20%is used to adjust the algorithm. This process is like cooking. Eighty percent of the time is spent on preparing ingredients, processing and adjusting various ingredients, and the real cooking may only take a few minutes for the chef to cook. It can be said that the key to determining whether a dish is delicious lies in the processing of ingredients and ingredients.Therefore, Professor Wu Enda proposedMLOps(“Machine learning Engineering for Production”). he thinks,MLOpsis to help machine learning for large-scale enterprise applications (Production) of a series of engineered things (Engineering),MLOpsThe most important task is to maintain a high-quality data supply at all stages of the machine learning life cycle, including data preparation, model training, model launch, and model monitoring and retraining.in his original“MLOps’ most important task is to make high quality data available through all stages of the ML project lifecycle.”
To this end, he also joined several experts in the industry toCouusera.aiLaunched on the training platformMachine Learning Engineering for Production (MLOps) 》Specialized courses on how to build and maintain machine learning systems that run continuously in production environments, how to deal with changing data, how to run non-stop at low cost and produce the highest performance, etc. (see linkhttps://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops) has already started3Ten thousand8More than 1,000 people have taken this series of courses, and those who have attended all lamented that his courses have maintained the same high quality as before. He has given a very comprehensive lecture on deploying machine learning applications in enterprises and generating value, and at the same time, it is also very practical. Lots of tools to get started quickly.
The above is represented by Professor Wu EndaAIscientists forMLOpsunderstanding, they have realizedMLOpsimportance and key points.
Let’s see againAIanalysts andAIengineer forMLOpsawareness.
First of all, from the perspective of industry analysts, the currentAIProject failure rates are staggeringly high.
2019year5moonDimensional ResearchThe research found that,78%ofAIThe project did not go online in the end;2019year6moon,VentureBeatThe report found that87%ofAIThe project is not deployed to the build environment.2020yearMonte Carlo DataestimateAIProject mortality is90%about.That is, althoughAIthe scientist,AIEngineers did a lot of work together, including data preparation and data exploration, model training, etc., but most of the machine learning models did not go online in the end, that is, they did not generate business value.
then fromAIFrom the point of view of the engineer, it is implemented within the enterpriseAIThe project currently has the following three shortcomings.
1. slow landing: Often, the landing time of a machine learning model is several times longer than the machine learning model tuning.
OneAIScientists sighed at a sharing meeting:” It took me 3 weeks to develop the model. It has been >11 months, and it is still not deployed.”i.e. he only spent3weeks to develop the model algorithm, but then11months, the model still hasn’t been deployed to production to function. In fact, this is not a single thing, it is a common phenomenon in the industry, and similar complaints are often heard in the industry.
2. The effect is not as expected: The machine learning model works very well when it is trained offline, and various indicators have reached the predetermined goals of the project, but when the model is deployed in the online environment, it connects to real online data and online traffic to provide prediction services. At times, the effect is often greatly reduced, which is very different from the effect of offline training.
3. The effect will go back: After a model goes online for a period of time (for example, a week), the effect of the model is OK, but as time goes on, the effect of the model becomes worse and worse. After one month, it becomes worse, and after three months, it becomes worse. Finally, the effect of the model becomes worse. So bad that it’s completely unusable.
Why does this result occur?
Google, a well-known technology company that develops and operates machine learning models and services for a long time, found that:AIScientists implement and train a machine learning model that, given the relevant training data, can produce a model with excellent results in an offline environment. But the real challenge is not to get a model that works well, the real challenge is to build a continuous running machine learning system in production and keep it working well.To this end, Google engineers2015year inNIPSThe paper published on “Hidden Technical Debt in Machine Learning Systems》 (see linkhttps://research.google/pubs/pub43146/) mentioned in a real on-lineAIThe system includes data collection, verification, resource management, feature extraction, process management, monitoring and many other contents.But the real code related to machine learning only accounts for the entireAIsystematic5%,the remaining95%The content is related to engineering and data. And the data is the most important part, and the most error-prone part.
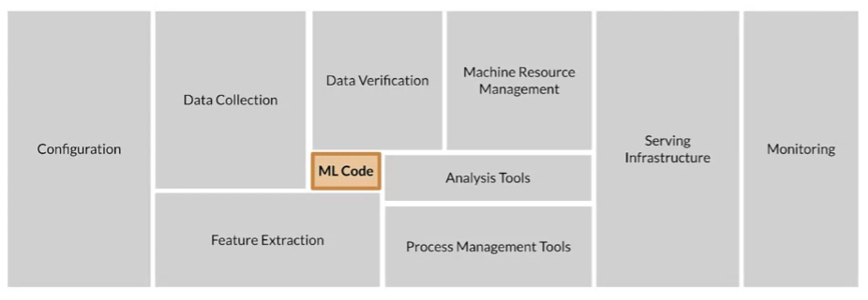
As shown in the figure, what is really related to the calculation of the machine learning model“ML Code“It only occupies a very small part of the whole system. The surrounding configuration management, data collection, feature processing, data verification, machine resource management and scheduling, forecasting services, monitoring, etc. occupy the rest95%part of the workload.
Data is the hardest part of ML and the most important piece to get right… Broken data is the most common cause of problems in production ML systems.
— Uber.
Translated into Chinese is:“Data is the hardest part of machine learning, and the most important part of getting results. Incorrect data is again the most common cause of problems in production environments.“
This isUberThe machine learning engineer mentioned in a well-known machine learning blog.This blog is called“Meet Michelangelo: Uber’s Machine Learning Platform”see linkhttps://www.uber.com/en-HK/blog/michelangelo-machine-learning-platform/this blog system elaboratesUberThe construction ideas and practices of the internal machine learning platform are considered to be theAIOne of engineering’s landmark documents.
The author believes that the challenges of data to a real machine learning system mainly lie in the following points:
- Scale(extensibility): Massive feature reading is a challenge, and training often requires massive feature data, notTsize, moreP(For example, the recommendation systems of major media websites and e-commerce websites need to process massive amounts of user behavior data, including clicks, favorites, viewing, etc.)PdozensPscale data. )
- Low Latency(Low Latency): The prediction service needs to achieve low latency and high throughput. Providing forecasting services often requires high throughput and low latency service capabilities to meet the needs of business scenarios such as risk control and recommendation, ensure basic user experience, and achieve business value.
- Model decay(Model effect decline): The real world is constantly changing, and machine learning models mine and extract rules from real data; when the world changes, the model effect will decline, how to deal with it? It is often necessary to collect updated data and retrain in time, and at the same time, a good effect monitoring system is required.
- Time Travel(Time traversal): It is easy to appear when processing feature data related to time series.“time travel“The problem. (“time travel“It means that during machine learning training, the behavior data that occurs after a certain point in time is also mixed into the overall data set that needs to be trained for training. The result of this training is often that the model training effect is good, but the effect after the model goes online is not. not to standard. It should have excluded behavioral data after this particular point in time from model training. )
- Training/Serving skew: The data and code logic used for model training and model prediction are inconsistent, resulting in good offline and offline training results, but poor online prediction results in an online production environment.
Listed above are some of the data-related challenges in machine learning.
- also,Data Freshnessthat is, the freshness of the data is also very important. It is necessary to keep the data updated. Only real-time data can be used, and real-time data is the latest data that can be closer to the user scenario. In some machine learning scenarios that are very valuable to enterprises (such as e-commerce recommendation, risk control in the financial industry, and logistics forecasting), real-time data needs to be introduced, and real-time data will bring greater challenges.
The last point is the sharing and reuse of feature data. Machine learning projects require the collection of large amounts of raw data (Raw Data), and then perform various data aggregation and transformation for training. For machine learning models in multiple business scenarios of multiple business lines within an enterprise, they need to use a large number of features, and there are often repeated situations.That is, a feature starts from the original log file reading, and then goes through a series of feature engineering steps, and finally obtains a highly expressive feature that can be modeledAused, can also be modeledBUse, this is a problem of feature sharing and reuse. Obviously, if it cannot be shared, then all these are read from massive original files, and then a series of feature engineering tasks need to be repeated, which will waste a lot of storage resources and computing resources.
The number of machine learning models running concurrently in large enterprises is growing rapidly.Taking a large domestic financial enterprise familiar to the author as an example, the internal machine learning scenarios of the enterprise are very rich, and there are1000Runs in multiple application scenarios1500+This model plays an important and critical role in online risk control, recommendation, prediction and other scenarios.
How are so many models supported? That is, how to support the business technically, so that machine learning can be used within the enterprise“more, faster, better, less“landing?
- Multiple: Multiple scenarios need to be implemented around key business processes, which may be a problem for large enterprises1000Even on the order of tens of thousands.
- Fast: The landing time of each scene should be short, and the iteration speed should be fast.For example, in recommended scenarios, it is often necessary to do daily1sub-full training, each15minutes or even every5do it in minutes1sub-incremental training.
- Good: The landing effect of each scene must meet expectations, at least better than before landing.
- Province: The landing cost of each scene is relatively low, which is in line with expectations.
It is not particularly difficult to meticulously improve the training and deployment of a model, but it requires a relatively low cost to implement thousands of models and function. This requires very good scalability, which can only be achieved by strengthening the machine learning system. engineering capabilities to achieve.
So how to solve the problems of slow online launch, poor effect, and even regression in these machine learning, and at the same time need to be scaled?
We can look back at how we solved the quality and efficiency of computer software or online systems. Back then, the coding completion function took a long time, the quality of the online service did not meet expectations, and even the online service crashed and did not respond to user requests.In this case, we use a method calledDevOpsmethod to improve our R&D model and tool system. On the premise of ensuring quality, we can increase the speed of version release faster, achieve more and faster deployment, and conduct more iterations and trial and error.To this end, we use a lot of automated work to carry out the assembly line (commonly known asPipeline) job, that is, starting from code submission, triggering the pipeline to perform a series of automated tasks, including code static inspection, code compilation, code dynamic inspection, unit testing, automated interface testing, automated function testing, small traffic deployment, blue-green deployment, Full flow deployment, etc. After containers became the mainstream of computer systems, related steps were added, such as packaging images of containers, deploying container images to container warehouses, and pulling containers on demand from container warehouses. Of course, this series of tasks needs to be automated as much as possible.
learn fromDevOpsin the field20Years of practical experience, the industry combines machine learning development and modern software development to form a complete set of tools and platforms and R&D processes, which we call“MLOps”.
MLOpsIt is a set of best engineering practices in the successful implementation of machine learning in the enterprise. Refer toDevOpsprinciples and practices involvingAIengineers andAIScientists and other roles, covering the entire life cycle of machine learning including defining projects, collecting and processing data, model training and iteration, model deployment and monitoring, and including continuous integration, continuous deployment, and continuous training of code, models, and data. and continuous monitoring and a series of actions.
Break it apart and elaborate:
(1) MLOpsIt is a set of engineering practices: more emphasis on engineering than algorithms and models
(2) is used in the online environment of the enterprise: it is not used in the research scene of the laboratory, but used in the enterprise, which needs to be combined with the business scene of the enterprise
(3) for the successful implementation of machine learning projects: in order to makeAIBring value to your business
(4)refer toDevOpspractice: DevOpsMany practices ofMLOpsreferenced and extended
(5) involves multiple roles: includingAIthe scientist,AIEngineers and other roles
(6) stage includesAIfull life cycle: Covering end-to-end machine learning lifecycle activities
(7) objects include code, models, data (features): not just code
(8) activities includeCI,CD,CT,CM: not onlyCIandCD
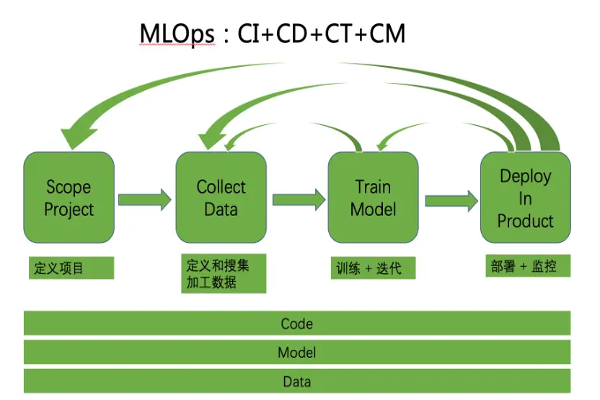
As shown in FIG,MLOpsCovers the whole life cycle activities of the machine learning system, that is, the machine learning system starts from the first step of defining the project, to the second step of feature data processing, to the third step of model training and iteration, to the fourth step of model deployment and Monitoring is carried out continuously in a pipeline manner.There are several small loops. For example, if the model training is not ideal, it may be necessary to return to the previous step to re-process the data; under the model monitoring, it is found that the effect of the online model has regressed, and it is necessary to return to the previous step to re-train the model, etc.; If it is found that the effect is not as expected after being deployed online, it may be necessary to return to the previous steps, including collecting more data and performing more feature engineering.
inCI,CD,CT,CMThe specific meanings are as follows:
- CIwhich isContinuous IntegrationContinuous integration means that data, code, and models are continuously generated, and a series of operations in the pipeline will be triggered after generation, such as unit testing, functional testing, code style adherence, code quality inspection, etc., as well as compilation and packaging. Wait for the process, and finally generate binary files or container image packages and save them in the software product warehouse, which are all automated by using various tools.For data, when new data is generated, for example, another user uses ourAppOr a small program service, his browsing, click, pull-down, like and other activities will be automatically recorded by the computer system in the background, and then through the dataETL(extract, transform, install ) and so on for processing, and then save it to a specific place for continued use and consumption by downstream services.
- CDwhich isContinuous DeployContinuous deployment means that code, data, models, etc. are continuously deployed to the production environment for users to use to generate value. For example, for the code, after the continuous integration process is completed and stored in the software product warehouse, the next step is to deploy these products into the online environment. The operation process includes small flow verification, hierarchical deployment, and full deployment. The same is true for data and models, which are continuously deployed to the online formulation environment to function.
- CTwhich isContinuous TrainingContinuous training, this is a model specifically for machine learning. After the data is continuously generated and deployed, continuous training is required, including full-scale training in an offline environment, and online training using online real-time data. It is hoped that the online model can reflect the laws of reality more quickly. It can be close to the real-time preferences of users, etc.
- CMwhich isContinuous MonitoringContinuous monitoring means that when models, codes, and data are deployed online,24×7At this time, it is necessary to continuously monitor the stability and reliability of the online system, and it is also necessary to monitor the prediction effect of the online machine learning system. For the former, if the online service fails, an alarm can be triggered in real time, and then the operation and maintenance students can either manually intervene to deal with it, or automatically deal with it according to preset rules. For the latter, if the online prediction effect is greatly reduced and the model needs to be updated after a certain threshold is lower, the continuous training process in the background will be triggered to complete the automatic training and update of the model.
In addition, the traditional software development fieldDevOpsIn practice, only code is often included, and code-related operations include code management, code compilation, code testing, output or packaging, etc.;MLOpsrelative toDevOpsand also adds model- and data-related operations.
Of course, MLOps isn’t just about processes and pipelines, it’s much bigger than that. for example:
(1) Storage platform: storage and reading of features and models
(2) Computing platform: streaming, batch processing for feature processing
(3) Message queue: used to receive real-time data
(4) Scheduling tools: scheduling of various resources (computing/storage)
(5) Feature Store: Register, discover and share various features
(6) Model Store: Features of the model
(7) Evaluation Store: Model monitoring/AB testing
Among them, Feature Store, Model store and Evaluation store are all emerging applications and platforms in the field of machine learning, because sometimes multiple models are run online at the same time. To achieve rapid iteration, a good infrastructure is needed to retain this information, so To make the iteration more efficient, these new applications and new platforms will emerge as the times require.
MLOps’s unique project – Feature Store
The following is a brief introduction to the Feature Store, the feature platform. As a platform specific to the field of machine learning, the Feature Store has many features.
First, the requirements for model training and prediction need to be met at the same time. Feature data storage engines have completely different application requirements in different scenarios. Model training requires good scalability and large storage space; real-time prediction needs to meet the requirements of high performance and low latency.
Second, the inconsistency between feature processing during training and prediction must be addressed. During model training, AI scientists generally use Python scripts, and then use Spark or SparkSQL to complete feature processing. This kind of training is not sensitive to delay and is inefficient when dealing with online business, so engineers will translate the feature processing process in a language with higher performance. However, the translation process is extremely cumbersome, and engineers have to repeatedly check with scientists whether the logic is in line with expectations. As long as it does not meet expectations a little, it will bring the problem of inconsistency between online and offline.
Third, it is necessary to solve the reuse problem in feature processing, avoid waste, and share efficiently. In an enterprise’s AI application, this situation often occurs: the same feature is used by different business departments, the data source comes from the same log file, and the extraction logic in the middle is similar, but because it is in different departments Or used in different scenarios, it cannot be reused, which is equivalent to the same logic being executed N times, and the log files are massive, which is a huge waste of storage resources and computing resources.
In summary, Feature Store is mainly used to solve high-performance feature storage and service, feature data consistency and feature reuse for model training and model prediction, and data scientists can use Feature Store for deployment and sharing.
At present, the mainstream feature platform products on the market can be roughly divided into three categories.
- Each AI company is self-developed. As long as the business needs real-time training, these companies will basically develop a similar feature platform to solve the above three problems. But this feature platform is deeply bound to the business.
- Part of the SAAS product or machine learning platform provided by the cloud vendor. For example, SageMaker provided by AWS, Vertex provided by Google, and the Azure machine learning platform provided by Microsoft. They will have a built-in feature platform in the machine learning platform, which is convenient for users to manage various complex features.
- Some open source and commercial products. To name a few examples, Feast, an open source Feature Store product; Tecton, a complete open source commercial feature platform product; OpenMLDB, an open source Feature Store product.
Maturity Model for MLOps
The maturity model is used to measure the capability goals of a system and a set of rules. In the field of DevOps, maturity models are often used to evaluate a company’s DevOps capabilities. There is also a corresponding maturity model in the field of MLOps, but there is no specification yet. Here is a brief introduction to Azure’s maturity model for MLOps. It divides the mature models of MLOps into (0, 1, 2, 3, 4) levels according to the degree of automation of the whole process of machine learning, of which 0 is no automation. (1,2,3) is partially automated, 4 is highly automated.
- Maturity is 0, i.e. no MLOps. This stage means that data preparation is manual, model training is also manual, and model training deployment is also manual. All the work is done manually, which is suitable for some business departments that are piloting AI innovations.
- Maturity 1 means there is DevOps and no MLOps. Its data preparation is done automatically, but model training is done manually. After scientists get the data, they make various adjustments and training before completing it. The deployment of the model is also done manually.
- Maturity is 2, which is automated training. The model training is done automatically. In short, when the data is updated, a similar pipeline is started immediately for automatic training, but the evaluation and online of the training results are still done manually.
- Maturity 3, which is automated deployment. After the automatic training of the model is completed, the evaluation and launch of the model are completed automatically without manual intervention.
- Maturity 4, which is automated retraining and deployment. It is constantly monitoring online models, and when it finds that the Model DK has degraded online model capabilities, it will automatically trigger repeated training. The whole process is fully automated, which can be called the most mature system.
#ModelCentric #DataCentric #MLOps #helps #implemented #quickly #costeffectively #Tan #Zhongyis #Personal #Space #News Fast Delivery