I. Introduction
High concurrency, high availability, and high performance are called the three high architectures of the Internet. These three are all factors that engineers and architects must consider in system architecture design. Today we will talk about the high availability in the three H, which is also the system stability we often talk about.
This article only talks about ideas and does not go into too many in-depth details. It takes about 5-10 minutes to read the full text.
Second, the definition of high availability
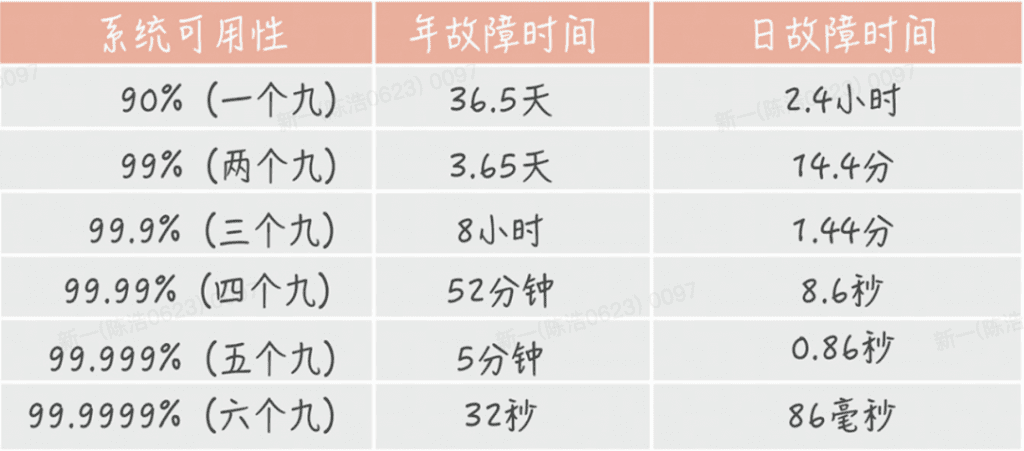
The industry often uses N 9s to quantify the degree of system availability, which can be directly mapped to the percentage of website uptime.

The formula for calculating availability:

The requirement of most companies is 4 9s, that is, the annual downtime cannot exceed 53 minutes. It is still very difficult to achieve this goal in practice, and each sub-module needs to cooperate with each other.
In order to improve the availability of a system, you first need to know what factors affect the stability of the system.
3. Factors Affecting Stability
First, let’s sort out some common problem scenarios that affect system stability, which can be roughly divided into three categories:
Unreasonable changes, external attacks, etc.
Code bugs, design vulnerabilities, GC problems, thread pool exceptions, upstream and downstream exceptions
Network failure, machine failure, etc.
The following is the right medicine,The first is prevention before failure, and the second is rapid recovery capability after failurelet’s talk about some common solutions.
Four, several ideas to improve stability
4.1 System Split
The purpose of splitting is not to reduce unavailable time, but to reduce the impact of failures. Because a large system is split into several small independent modules, a problem with one module will not affect other modules, thereby reducing the impact of failures. System splitting includes access layer splitting, service splitting, and database splitting.
Generally, it is divided according to the dimensions of business module, importance, frequency of change, etc.
Generally, after splitting according to business, if necessary, you can also do vertical splitting, that is, data sharding, read-write separation, data hot and cold separation, etc.
4.2 Decoupling
After the system is split, it will be divided into multiple modules. There are strong and weak dependencies between modules. If it is strongly dependent, then if there is a problem with the relying party, it will also be implicated in the problem. At this time, the calling relationship of the entire process can be sorted out and made into weak dependency calls. Weakly dependent calls can be decoupled in the way of MQ. Even if there is a problem downstream, it will not affect the current module.
4.3 Technical Selection
It can conduct a full evaluation in terms of applicability, advantages and disadvantages, product reputation, community activity, actual combat cases, scalability, etc., and select middleware & databases suitable for current business scenarios. Preliminary research must be sufficient.First compare, test, research, and then decide, sharpening knives is not wrong for chopping wood.
4.4 Redundant Deployment & Automatic Failover
The redundant deployment of the service layer is well understood. A service deploys multiple nodes, and redundancy is not enough. Every time a fault occurs, manual intervention is required to restore the system, which will inevitably increase the unserviceable time of the system. Therefore, high availability of the system is often achieved through “automatic failover”. That is, after a node goes down, it needs to be able to automatically remove upstream traffic, and these capabilities can basically be achieved through the detection mechanism of load balancing.
It is more complicated when it comes to the data layer, but there are generally mature solutions for reference. It is generally divided into one master and one slave, one master with multiple slaves, and multiple masters with multiple slaves.But the general principle isData synchronization realizes multiple slaves, and data sharding realizes multiple mastersboth during failoverA new master node is elected through an election algorithmThen provide services to the outside world (here, if you do not perform strong consistent synchronization when writing, some data will be lost during failover). For details, please refer to Redis Cluster, ZK, Kafka and other cluster architectures.
4.5 Capacity Assessment
Before the system goes online, it is necessary to evaluate the capacity of the machines, DBs, and caches used by the entire service. The capacity of the machines can be evaluated in the following ways:
- Clarify the expected traffic indicator – QPS;
- Specify acceptable delay and safety water level indicators (such as CPU% ≤ 40%, core link RT ≤ 50ms);
- Evaluate the highest QPS that a single machine can support below the safe water level through stress testing (it is recommended to verify through mixed scenarios, such as stress testing multiple core interfaces at the same time according to the estimated traffic ratio);
- Finally, the specific number of machines can be estimated.
In addition to QPS, DB and cache evaluation also needs to evaluate the amount of data. The method is roughly the same. After the system is online, it can be expanded or reduced according to the monitoring indicators.
4.6 Service Rapid Capacity Expansion & Flood Discharge Capability
At this stage, whether it is a container or an ECS, simple node replication and expansion is very easy. The key point of expansion is to evaluate whether the service itself is stateless, for example:
- What is the maximum number of connections to the downstream DB that can support the expansion of the current service?
- Does the cache need to be warmed up after expansion?
- heavy volume strategy
These factors all need to be prepared in advance, and a complete SOP document should be sorted out. Of course, the best way is to conduct a drill.
Flood discharge capability generally refers to selecting several nodes as backup nodes in the case of redundant deployment, and usually bears a small part of the traffic. When the traffic peak comes, a part of the traffic of the hot node is transferred to the backup node by adjusting the traffic routing strategy.
Compared with the expansion plan, the cost is relatively high, but the advantage is thatFast response and low risk.
4.7 Traffic shaping & circuit breaker downgrade
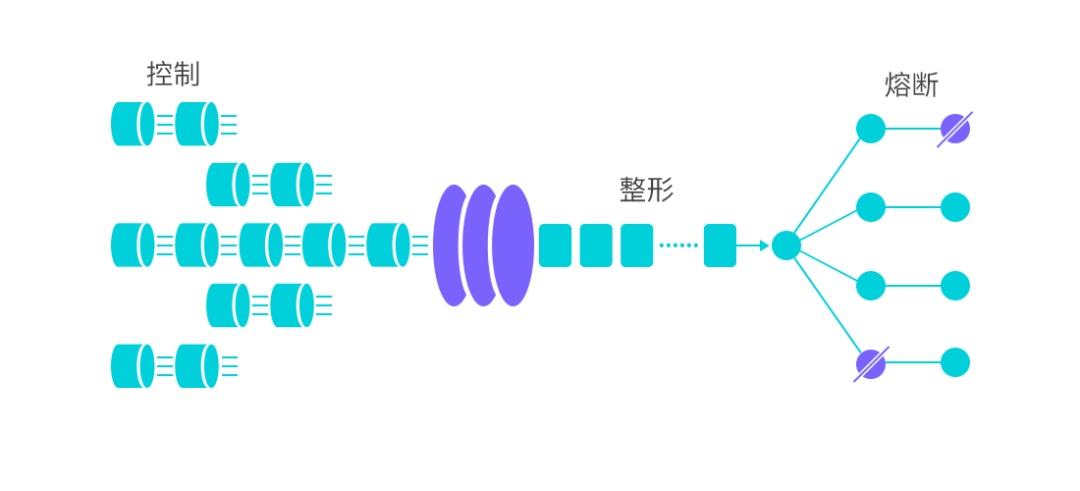
Traffic shaping, also known as current throttling, is mainly to prevent the service from being overwhelmed by unexpected traffic. Fusing is for the failure of its own components or relying on downstream failures, which can quickly fail to prevent long-term blockage and lead to avalanches. Regarding the ability of current limiting and fusing, the open source component Sentinel basically has it, and it is very simple and convenient to use, but there are some points to pay attention to.
- The current limiting threshold is generally the highest water level that can be supported by a resource configured as a service, which needs to be evaluated through stress testing. This value may need to be continuously adjusted as the system iterates. If the configuration is too high, the protection will not be triggered when the system crashes, and if the configuration is too low, accidental injury will occur.
- Fusing downgrade – After an interface or a resource is blown, it is necessary to evaluate whether to throw an exception or return a bottom-line result according to the business scenario and the importance of the blown resource. For example, if the deduction inventory interface is blown in the ordering scenario, because the deduction inventory is a necessary condition for the order placement interface, after the fuse, an exception can only be thrown to make the entire link fail and roll back. If the interface related to obtaining product reviews is blown, Then you can choose to return a null without affecting the entire link.
4.8 Resource isolation
If multiple downstreams of a service are blocked at the same time, and a single downstream interface fails to meet the fuse standard (for example, the ratio of exceptions and slow requests does not reach the threshold), it will cause the throughput of the entire service to drop and more threads to be occupied. , and even lead to thread pool exhaustion in extreme cases. After resource isolation is introduced, the maximum thread resources that can be used by a single downstream interface can be limited to ensure that the throughput of the entire service is affected as little as possible before the interruption.
When it comes to the isolation mechanism, it can be expanded here. Since the traffic of each interface is different from RT, it is difficult to set a reasonable maximum number of threads available, and with business iteration, this threshold is also difficult to maintain. Here, sharing and exclusive use can be used to solve this problem. Each interface has its own exclusive thread resource. When the exclusive resource is full, the shared resource is used. After the shared pool reaches a certain water level, the exclusive resource is forced to be used and wait in line. The obvious advantage of this mechanism is that it can ensure isolation while maximizing resource utilization.
The number of threads here is only one type of resource, and the resource can also be the number of connections, memory, and so on.
4.9 Systematic Protection

Systematic protection is a kind of indiscriminate flow restriction. The concept in one sentence is to perform indiscriminate flow restriction on all flow inlets before the system is about to collapse, and stop flow restriction when the system returns to a healthy water level. The specific point is to combine the monitoring indicators of several dimensions such as application Load, overall average RT, ingress QPS, and number of threads, so that the ingress traffic of the system and the load of the system can be balanced, so that the system can run at the maximum throughput as much as possible while ensuring overall system stability.
4.10 Observability & Alerting

When the system fails, we first need to find the cause of the failure, then solve the problem, and finally restore the system. The speed of troubleshooting largely determines the overall recovery time, and the greatest value of observability lies in fast troubleshooting. Secondly, configure alarm rules based on the three pillars of Metrics, Traces, and Logs, so that possible risks and problems in the system can be discovered in advance to avoid failures.
4.11 Three Axes for Change Process
Change is the biggest enemy of availability. 99% of failures come from changes, which may be configuration changes, code changes, machine changes, and so on. So how to reduce the failure caused by change?
Use a small percentage of traffic to verify the changed content to reduce the impact on the user base.
After a problem occurs, there can be an effective rollback mechanism. When data modification is involved, dirty data will be written after publishing. A reliable rollback process is required to ensure the cleanup of dirty data.
By observing the changes in indicators before and after the change, problems can be found in advance to a large extent.
In addition to the above three axes, other development processes should also be standardized, such as code control, integrated compilation, automated testing, static code scanning, etc.
V. Summary
For a dynamically evolving system, there is no way for us to reduce the probability of failure to 0. What we can do is to prevent and shorten the recovery time during failure as much as possible. Of course, we don’t have to blindly pursue availability. After all, while improving stability, maintenance costs and machine costs will also increase. Therefore, it is necessary to combine the business SLO requirements of the system, and the most suitable one is the best.
How to ensure stability and high availability is a huge proposition. This article does not have too many in-depth details. It only talks about some overall ideas, mainly for everyone to have a set of high-availability construction in the future. The framework of the system can refer to. Finally, I would like to thank the students who read it patiently.
*Text/New One
Pay attention to Dewu Technology, and update technical dry goods at 18:30 every Monday, Wednesday, and Friday night
If you think the article is helpful to you, please comment, forward and like~
#Talking #Ideas #System #Stability #High #Availability #Guarantee