ElasticSearch is a real-time distributed search and analysis engine, which is often used in the storage and fast retrieval scenarios of large amounts of unstructured data, and has strong scalability.Even though it has many advantages, it is far superior to relational databases in the search field, but it still has the same deep paging problem as relational databases. This article makes a practical analysis and discussion on this issue
The from + size paging method is the most basic paging method of ES, similar to the limit method in relational databases. The from parameter indicates: the starting position of the paging; the size parameter indicates: the number of data items obtained per page. E.g:
GET /wms_order_sku/_search
{
"query": {
"match_all": {}
},
"from": 10,
"size": 20
}This DSL statement indicates that starting from the 10th data position in the search result, the next 20 data are taken as the result and returned. How is this paging method implemented inside the ES cluster?
In ES, the search generally includes two stages, the Query stage and the Fetch stage. The Query stage mainly determines which docs to obtain, that is, returns the id set of the docs to be obtained. The Fetch stage mainly obtains specific docs through ids.
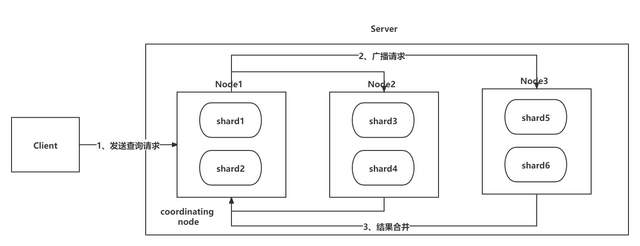
As shown in the figure above, the Query phase is roughly divided into 3 steps:
- Step 1: Client sends a query request to the server, Node1 receives the request and creates a priority queue with a size of from + size to store the results, at this time Node1 is called the coordinating node (coordinating node);
- Step 2: Node1 broadcasts the request to the involved shards, each shard internally executes the search request, and then stores the execution result in its own internal priority queue with the same size as from+size;
- Step 3: Each shard returns the results in its temporary priority queue to Node1. After Node1 gets the results returned by all shards, it merges the results once to generate a global priority queue. level queue. (As shown in the figure above, Node1 will get (from + size) * 6 pieces of data, which only contain the unique identifier _id of doc and _score for sorting, and then Node1 will merge and sort these data, and select from + size size pieces of data are stored in the priority queue);
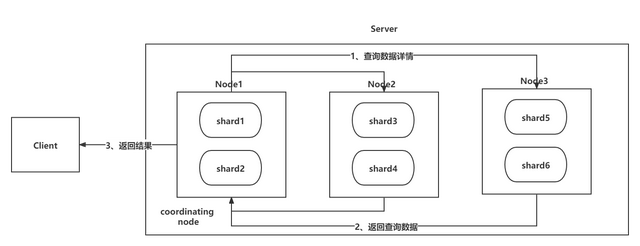
As shown in the figure above, when the Query phase is over, it immediately enters the Fetch phase, and the Fetch phase is also divided into 3 steps:
- Step 1: Node1 sends a request to the corresponding shard to query the doc data details according to the id set of the from+size pieces of data saved in the priority queue after the merger just now;
- Step 2: After each shard receives the query request, it queries the corresponding data details and returns it as Node1; (the _id of the from + size pieces of data is saved in the priority queue in Node1, but it does not need to be fetched in the Fetch stage To retrieve all the data, you only need to retrieve the size data details between from and from + size. These size data may be in the same shard or in different shards, so Node1 uses multi-get to improve performance)
- Step 3: After Node1 obtains the corresponding paging data, it returns to Client;
Based on the above two-stage analysis of the from + size paging method, we will find that if the starting position from or the page number size is particularly large, there will be a huge performance loss for data query and coordinating node result merging.
For example: the index wms_order_sku has 100 million data, divided into 10 shards for storage, when a request has from = 1000000, size = 10. In the Query stage, each shard needs to return _id and _score information of 1000010 pieces of data, and the coordinating node needs to receive 10 * 1000010 pieces of data. After getting these data, it needs to perform global sorting to get the _ of the first 1000010 pieces of data. The id set is saved in the priority queue of the coordinating node, and then the details of the 10 pieces of data are obtained in the Fetch stage and returned to the client.
Analysis: During the execution of this example, there will be a huge amount of queries on each shard in the Query phase. When returning to the coordinating node, a large amount of data sorting operations need to be performed, and the amount of data saved to the priority queue is also large , occupying a large amount of node machine memory resources.
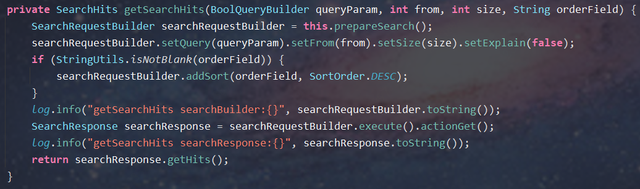
private SearchHits getSearchHits(BoolQueryBuilder queryParam, int from, int size, String orderField) {
SearchRequestBuilder searchRequestBuilder = this.prepareSearch();
searchRequestBuilder.setQuery(queryParam).setFrom(from).setSize(size).setExplain(false);
if (StringUtils.isNotBlank(orderField)) {
searchRequestBuilder.addSort(orderField, SortOrder.DESC);
}
log.info("getSearchHits searchBuilder:{}", searchRequestBuilder.toString());
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
log.info("getSearchHits searchResponse:{}", searchResponse.toString());
return searchResponse.getHits();
}In fact, ES has a default limit of 10,000 pieces of returned data in the result window (parameter: index.max_result_window = 10,000). When the number of pieces from + size is greater than 10,000 pieces, ES prompts that you can page through scroll. It is not recommended to increase the result window parameter value.
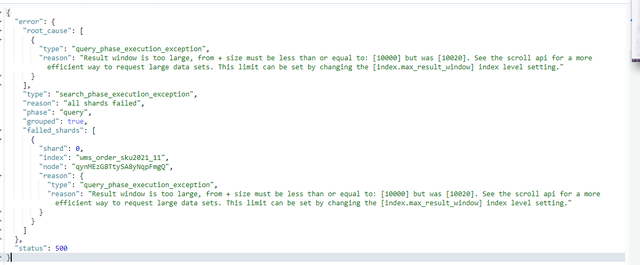
The scroll paging method is similar to the cursor in a relational database. The snapshot will be generated and cached at the first query, and the location parameter (scroll_id) read by the snapshot will be returned to the client. Each subsequent request will access the snapshot through scroll_id to achieve fast query needs data, effectively reducing the performance loss of query and storage.
The scroll paging method also broadcasts query requests from the coordinating node in the Query stage to obtain, merge, and sort the data _id sets returned by other shards. The difference is that the scroll paging method will generate snapshots of the returned data _id collections and save them on the coordinating node. In the Fetch phase, the _id of size pieces of data is obtained from the generated snapshot in the form of a cursor, and the details of the data are obtained from other shards and returned to the client. At the same time, the next cursor start position identifier _scroll_id is also returned. In this way, the next time the client sends a request to obtain the next page, it will bring the scroll_id identifier, and the coordinating node will obtain the next size piece of data from the position marked by scroll_id, and return the new cursor position identifier scroll_id again, and so on until all the data is fetched .
You don’t need to pass in _scroll_id for the first query, just bring the expiration time parameter of scroll (scroll=1m), the size of each page (size), and the custom conditions that need to query data. After the query, not only the result data will be returned , also returns _scroll_id.
GET /wms_order_sku2021_10/_search?scroll=1m
{
"query": {
"bool": {
"must": [
{
"range": {
"shipmentOrderCreateTime": {
"gte": "2021-10-04 00:00:00",
"lt": "2021-10-15 00:00:00"
}
}
}
]
}
},
"size": 20
}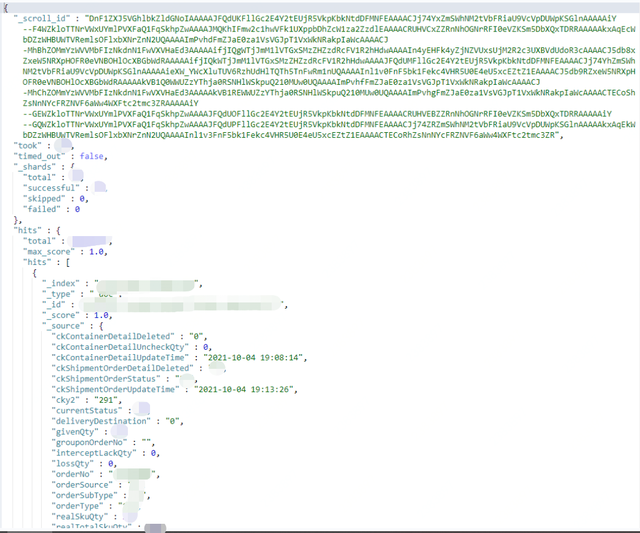
It is not necessary to specify an index for the second query. The scroll_id returned by the previous query is included in the JSON request body, and the scroll parameter is passed in at the same time to specify the cache time for refreshing the search results (the last query is cached for 1 minute, and this query will be updated again. Reset cache time to 1 minute)
GET /_search/scroll
{
"scroll":"1m",
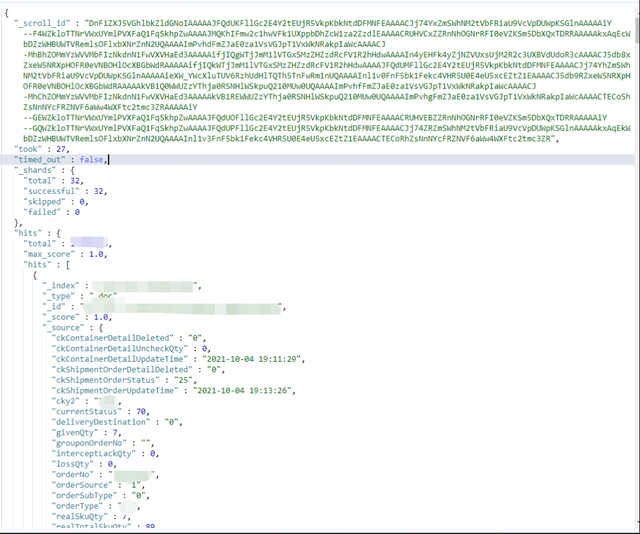
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoIAAAAAJFQdUKFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACJj74YxZmSWhNM2tVbFRiaU9VcVpDUWpKSGlnAAAAAiY--F4WZkloTTNrVWxUYmlPVXFaQ1FqSkhpZwAAAAJMQKhIFmw2c1hwVFk1UXppbDhZcW1za2ZzdlEAAAACRUHVCxZZRnNhOGNrRFI0eVZKSm5DbXQxTDRRAAAAAkxAqEcWbDZzWHBUWTVRemlsOFlxbXNrZnN2UQAAAAImPvhdFmZJaE0za1VsVGJpT1VxWkNRakpIaWcAAAACJ-MhBhZOMmYzWVVMbFIzNkdnN1FwVXVHaEd3AAAAAifjIQgWTjJmM1lVTGxSMzZHZzdRcFV1R2hHdwAAAAIn4yEHFk4yZjNZVUxsUjM2R2c3UXBVdUdoR3cAAAACJ5db8xZxeW5NRXpHOFR0eVNBOHlOcXBGbWdRAAAAAifjIQkWTjJmM1lVTGxSMzZHZzdRcFV1R2hHdwAAAAJFQdUMFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACJj74YhZmSWhNM2tVbFRiaU9VcVpDUWpKSGlnAAAAAieXW_YWcXluTUV6RzhUdHlTQTh5TnFwRm1nUQAAAAInl1v0FnF5bk1Fekc4VHR5U0E4eU5xcEZtZ1EAAAACJ5db9RZxeW5NRXpHOFR0eVNBOHlOcXBGbWdRAAAAAkVB1Q0WWUZzYThja0RSNHlWSkpuQ210MUw0UQAAAAImPvhfFmZJaE0za1VsVGJpT1VxWkNRakpIaWcAAAACJ-MhChZOMmYzWVVMbFIzNkdnN1FwVXVHaEd3AAAAAkVB1REWWUZzYThja0RSNHlWSkpuQ210MUw0UQAAAAImPvhgFmZJaE0za1VsVGJpT1VxWkNRakpIaWcAAAACTECoShZsNnNYcFRZNVF6aWw4WXFtc2tmc3ZRAAAAAiY--GEWZkloTTNrVWxUYmlPVXFaQ1FqSkhpZwAAAAJFQdUOFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACRUHVEBZZRnNhOGNrRFI0eVZKSm5DbXQxTDRRAAAAAiY--GQWZkloTTNrVWxUYmlPVXFaQ1FqSkhpZwAAAAJFQdUPFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACJj74ZRZmSWhNM2tVbFRiaU9VcVpDUWpKSGlnAAAAAkxAqEkWbDZzWHBUWTVRemlsOFlxbXNrZnN2UQAAAAInl1v3FnF5bk1Fekc4VHR5U0E4eU5xcEZtZ1EAAAACTECoRhZsNnNYcFRZNVF6aWw4WXFtc2tmc3ZR"
}
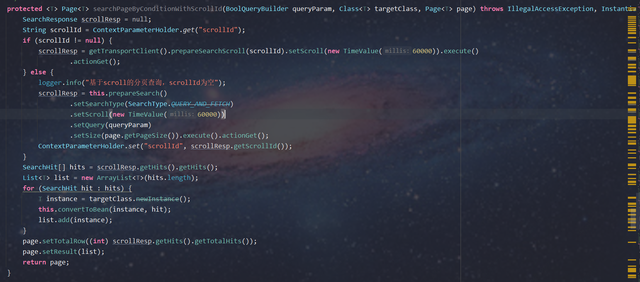
protected <T> Page<T> searchPageByConditionWithScrollId(BoolQueryBuilder queryParam, Class<T> targetClass, Page<T> page) throws IllegalAccessException, InstantiationException, InvocationTargetException {
SearchResponse scrollResp = null;
String scrollId = ContextParameterHolder.get("scrollId");
if (scrollId != null) {
scrollResp = getTransportClient().prepareSearchScroll(scrollId).setScroll(new TimeValue(60000)).execute()
.actionGet();
} else {
logger.info("基于scroll的分页查询,scrollId为空");
scrollResp = this.prepareSearch()
.setSearchType(SearchType.QUERY_AND_FETCH)
.setScroll(new TimeValue(60000))
.setQuery(queryParam)
.setSize(page.getPageSize()).execute().actionGet();
ContextParameterHolder.set("scrollId", scrollResp.getScrollId());
}
SearchHit[] hits = scrollResp.getHits().getHits();
List<T> list = new ArrayList<T>(hits.length);
for (SearchHit hit : hits) {
T instance = targetClass.newInstance();
this.convertToBean(instance, hit);
list.add(instance);
}
page.setTotalRow((int) scrollResp.getHits().getTotalHits());
page.setResult(list);
return page;
}The advantage of the scroll paging method is that it reduces the number of queries and sorting and avoids performance loss. The disadvantage is that it can only realize the page turning function of the previous page and the next page, and is not compatible with the page jumping of the query data through the page number. At the same time, because it will generate a snapshot during the search initialization stage, subsequent data changes cannot be reflected in the query results in time, so It is more suitable for one-time batch query or paging query of non-real-time data.
When enabling cursor query, you need to pay attention to setting the expected expiration time (scroll = 1m) to reduce the resources consumed to maintain the cursor query window. Note that this expiration time will be reset and refreshed to 1 minute for each query, indicating the idle expiration time of the cursor (the query after the second time must be implemented with the scroll = 1m parameter)
The Search After paging method is a new paging query method added by ES5. Its implementation idea is basically the same as that of the Scroll paging method. The next paged data query is performed by recording the position identifier of the previous paged page. Compared with the Scroll paging method, its advantage is that it can reflect data changes in real time and solve the problem of query result delay caused by querying snapshots.
The Search After method also does not support the page jump function, and one page of data is queried each time. For the first time, each shard returns a page of data (size items), and the coordinating node obtains a total of shard number * size items of data. Next, the coordinating node sorts in memory, and takes out the first size items of data and returns them as the first page of search results. When pulling the second page, unlike the Scroll pagination method, the Search After method will find the maximum value of the data pulled from the first page as the query condition for pulling the data on the second page.
In this way, each shard still returns one page of data (size items), and the coordinating node obtains the number of shards * size items of data for memory sorting, and obtains the first size items of data as the global second page search results.
Subsequent paging queries and so on…
The first query only passes in the sort field and the size of each page
GET /wms_order_sku2021_10/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"shipmentOrderCreateTime": {
"gte": "2021-10-12 00:00:00",
"lt": "2021-10-15 00:00:00"
}
}
}
]
}
},
"size": 20,
"sort": [
{
"_id": {
"order": "desc"
}
},{
"shipmentOrderCreateTime":{
"order": "desc"
}
}
]
}
Next, bring the _id and shipmentOrderCreateTime fields of the last piece of data in this query every time you query, and the function of continuing to the next page can be realized by repeating the cycle
GET /wms_order_sku2021_10/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"shipmentOrderCreateTime": {
"gte": "2021-10-12 00:00:00",
"lt": "2021-10-15 00:00:00"
}
}
}
]
}
},
"size": 20,
"sort": [
{
"_id": {
"order": "desc"
}
},{
"shipmentOrderCreateTime":{
"order": "desc"
}
}
],
"search_after": ["SO-460_152-1447931043809128448-100017918838",1634077436000]
}

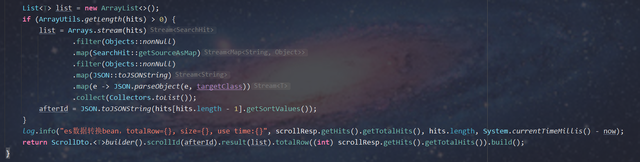
public <T> ScrollDto<T> queryScrollDtoByParamWithSearchAfter(
BoolQueryBuilder queryParam, Class<T> targetClass, int pageSize, String afterId,
List<FieldSortBuilder> fieldSortBuilders) {
SearchResponse scrollResp;
long now = System.currentTimeMillis();
SearchRequestBuilder builder = this.prepareSearch();
if (CollectionUtils.isNotEmpty(fieldSortBuilders)) {
fieldSortBuilders.forEach(builder::addSort);
}
builder.addSort("_id", SortOrder.DESC);
if (StringUtils.isBlank(afterId)) {
log.info("queryScrollDtoByParamWithSearchAfter基于afterId的分页查询,afterId为空");
SearchRequestBuilder searchRequestBuilder = builder.setSearchType(SearchType.DFS_QUERY_THEN_FETCH)
.setQuery(queryParam).setSize(pageSize);
scrollResp = searchRequestBuilder.execute()
.actionGet();
log.info("queryScrollDtoByParamWithSearchAfter基于afterId的分页查询,afterId 为空,searchRequestBuilder:{}", searchRequestBuilder);
} else {
log.info("queryScrollDtoByParamWithSearchAfter基于afterId的分页查询,afterId=" + afterId);
Object[] afterIds = JSON.parseObject(afterId, Object[].class);
SearchRequestBuilder searchRequestBuilder = builder.setSearchType(SearchType.DFS_QUERY_THEN_FETCH)
.setQuery(queryParam).searchAfter(afterIds).setSize(pageSize);
log.info("queryScrollDtoByParamWithSearchAfter基于afterId的分页查询,searchRequestBuilder:{}", searchRequestBuilder);
scrollResp = searchRequestBuilder.execute()
.actionGet();
}
SearchHit[] hits = scrollResp.getHits().getHits();
log.info("queryScrollDtoByParamWithSearchAfter基于afterId的分页查询,totalRow={}, size={}, use time:{}", scrollResp.getHits().getTotalHits(), hits.length, System.currentTimeMillis() - now);
now = System.currentTimeMillis();
List<T> list = new ArrayList<>();
if (ArrayUtils.getLength(hits) > 0) {
list = Arrays.stream(hits)
.filter(Objects::nonNull)
.map(SearchHit::getSourceAsMap)
.filter(Objects::nonNull)
.map(JSON::toJSONString)
.map(e -> JSON.parseObject(e, targetClass))
.collect(Collectors.toList());
afterId = JSON.toJSONString(hits[hits.length - 1].getSortValues());
}
log.info("es数据转换bean,totalRow={}, size={}, use time:{}", scrollResp.getHits().getTotalHits(), hits.length, System.currentTimeMillis() - now);
return ScrollDto.<T>builder().scrollId(afterId).result(list).totalRow((int) scrollResp.getHits().getTotalHits()).build();
}The Search After paging method uses records as cursors, so Search After requires at least one globally unique variable in the doc (the example uses _id and timestamp, but actually _id is already globally unique). The Search After method is a stateless paging query, so data changes can be reflected in the query results in a timely manner, avoiding the disadvantage that the Scroll paging method cannot obtain the latest data changes. At the same time, Search After does not need to maintain scroll_id and snapshots, so it also saves a lot of resources.
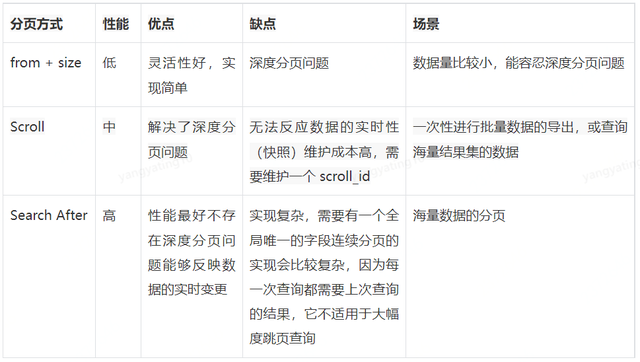
- If the amount of data is small (from+size is within 10,000), or you only care about the TopN data of the result set, you can use from/size pagination, which is simple and rude
- For tasks such as large amount of data, deep page turning, and background batch processing tasks (data migration), use the scroll method
- Large amount of data, deep page turning, user real-time, high concurrent query requirements, use the search after method
- In general business query pages, in most cases, 10-20 pieces of data are one page, and 10,000 pieces of data are 500-1000 pages. Under normal circumstances, for users, there is very little need to turn to a relatively late page number to view the data, and more is to frame a part of the data through query conditions to view its details. Therefore, in the initial stage of finalizing the business requirements, the limit of 10,000 pieces of data can be agreed with the business personnel. If the number of pieces exceeds 10,000 pieces, the data can be exported to an Excel table, and specific operations can be performed in the Excel table.
- If a large amount of data is returned to the export center, the Scroll or Search After paging method can be used. In contrast, it is better to use the Search After method, which can not only ensure the real-time performance of the data, but also have high search performance.
- In short, when using ES, you must avoid the problem of deep paging, and you must make a trade-off between the realization of page jumping function and ES performance and resources. If necessary, you can also increase the max_result_window parameter. In principle, this is not recommended, because ES can basically maintain very good performance within 10,000 items. Deep paging beyond this range is time-consuming and resource-consuming, so choose this method carefully.
Author: He Shouyou
#Detailed #Explanation #ElasticSearch #Depth #PaginationJD #Cloud #Developers #Personal #Space #News Fast Delivery