

 Introduction | Reasonable use of cache does improve the throughput and stability of the system, but it comes at a price. This price is the challenge of cache and database consistency. This article will thoroughly explain how to maintain cache consistency under the most common cache-aside strategy.
Introduction | Reasonable use of cache does improve the throughput and stability of the system, but it comes at a price. This price is the challenge of cache and database consistency. This article will thoroughly explain how to maintain cache consistency under the most common cache-aside strategy.
But objectively, the scale of our business is likely to require higher QPS. Some businesses are very large in size, and some businesses will encounter some traffic peaks, such as e-commerce encountering big promotions.
At this time, most of the traffic is actually read requests, and most of the data does not change so much, such as popular product information, Weibo content and other common data. At this point, caching is our weapon to deal with such scenarios.

The so-called cache is actually exchanging space for time, to be precise, exchanging time with higher-speed space, so as to improve the performance of reading as a whole.
What is a higher speed space?
Faster storage media. Usually, if the database is slow, you have to replace it with a faster storage component, and the most common one is Redis (memory storage). The read QPS of a single instance of Redis can be as high as 10w/s, and in 90% of the scenarios, only Redis can be used correctly.
Use local memory as close as possible. Just like the CPU also has a cache, the cache can also be divided into a first-level cache and a second-level cache. Even if the performance of Redis itself is high enough, accessing Redis requires a network IO after all, and using local memory is undoubtedly faster. However, the memory of a single machine is very limited, so this level-1 cache can only store a very small amount of data, usually the data corresponding to the hottest keys. This is equivalent to consuming additional valuable service memory in exchange for high-speed reading performance.

Trading space for time means that data exists in multiple spaces at the same time. The most common scenario is that the data exists on Redis and MySQL at the same time (for the universality of the problem, unless otherwise specified in the following examples, the cache refers to the Redis cache).
In fact, the most authoritative and complete data is still in MySQL. And in case the Redis data is not updated in time (for example, the database is updated but not updated to Redis), there will be data inconsistency.
In most cases, as long as the cache is used, there will inevitably be inconsistencies, just to say whether the inconsistent time window can be made small enough. Some unreasonable designs may lead to continuous data inconsistency, which we need to improve the design to avoid.
The consistency here is actually the same for the local cache. For example, if the local cache is not updated in time after the database is updated, there is also a consistency problem. The following will use the Redis cache as an introduction to describe it. In fact, the principle of dealing with local cache is basically the same.
Why can’t we achieve strong consistency between the cache and the database?
Ideally, we need to synchronize the corresponding latest data to the cache after the database is updated, so that new data can be read instead of old data (dirty data) when reading requests. But unfortunately, since there is no transaction guarantee between the database and Redis, we cannot guarantee that after writing to the database, the writing to Redis will also be successful; During the period before the entry is successful, the Redis data must also be inconsistent with MySQL. As shown in the following two figures:
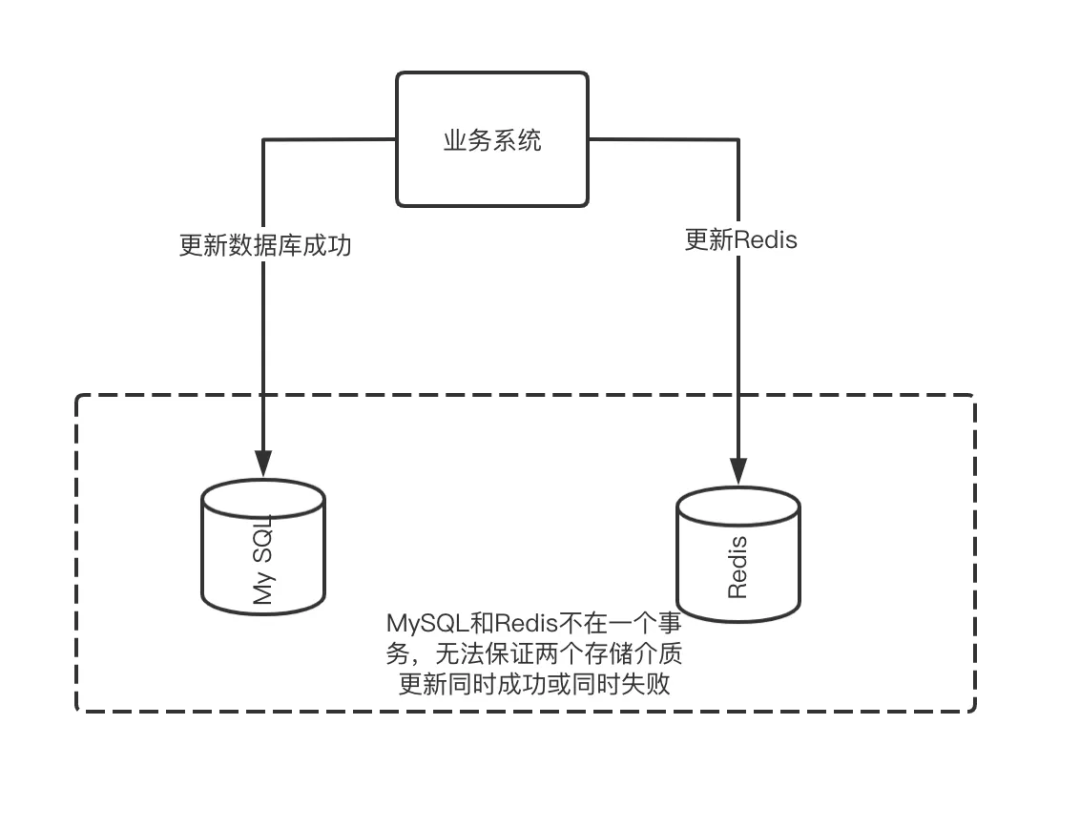
Unable to keep transactions consistent
Therefore, there is no way to completely eliminate this time window, unless we pay a huge price and use various means such as distributed transactions to maintain strong consistency, but this will greatly reduce the overall performance of the system, even worse than not using cache Slow, doesn’t this run counter to our goal of using caching?
However, although we cannot achieve strong consistency, what we can do is to achieve final consistency between the cache and the database, and we can make the inconsistent time window as short as possible. According to experience, if the time can be optimized to within 1ms, We can ignore the impact of this consistency problem.
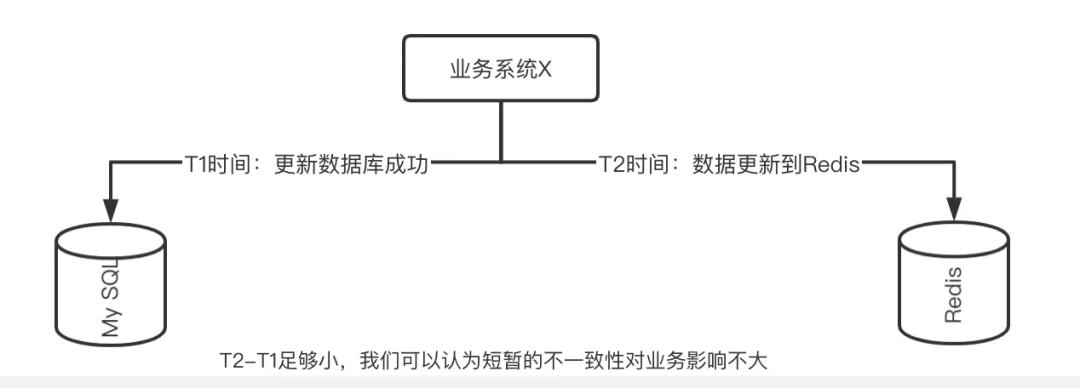
 means of updating the cache
means of updating the cache
Usually, when we process query requests, the logic of using cache is as follows:
data = queryDataRedis(key);
if (data ==null) {
data = queryDataMySQL(key); //缓存查询不到,从MySQL做查询
if (data!=null) {
updateRedis(key, data);//查询完数据后更新MySQL最新数据到Redis
}
}
That is to say, the cache is queried first, and the database is queried when the query is not available. If the database finds the data at this time, the cached data will be updated. This is the cache aside strategy we often say, and it is also the most commonly used strategy.
Such logic is correct, and the problem of consistency generally does not come from this, but occurs when processing write requests. So we simplify it to the simplest write request logic. At this time, you may face multiple choices. Should you directly update the cache or invalidate the cache? Whether it is updating the cache or invalidating the cache, you can choose to operate before or after updating the database.
In this way, four strategies have evolved: update the cache after updating the database, update the cache before updating the database, delete the cache after updating the database, and delete the cache before updating the database. Let’s talk about them separately.
A common operation is to set an expiration time so that the write request is based on the database. After the expiration time, the read request synchronizes the latest data in the database to the cache. So after adding the expiration time, will there be no problem? Not so.
Imagine this scenario.
If there is a counter here, the database is decremented by 1, the original database data is 100, and there are two write requests at the same time, the counter is decremented by 1, assuming that thread A successfully decrements the database first, and then thread B succeeds in decrementing the database. Then the value in the database at this time is 98, and the correct value in the cache should also be 98.
But in special scenarios, you may encounter such a situation:
Thread A and thread B update this data at the same time
The order of updating the database is first A and then B
When updating the cache, the order is first B and then A
If our code logic still updates the cached data immediately after updating the database, then——
updateMySQL();
updateRedis(key, data);
It may appear: the value of the database is 100->99->98, but the cached data is 100->98->99, that is, the database is inconsistent with the cache. And this inconsistency can only be fixed until the next database update or cache failure.
| time | Thread A (write request) | Thread B (write request) | question |
|---|---|---|---|
| T1 | update database to 99 | ||
| T2 | update database to 98 | ||
| T3 | Update cache data to 98 | ||
| T4 | Update the cache data to 99 | At this time, the cached value is explicitly updated to 99, but in fact the value in the database is already 98, and the data is inconsistent |
Of course, if the update of Redis itself fails, the values on both sides are also inconsistent. This is also explained in the previous article, and it is almost impossible to eradicate.
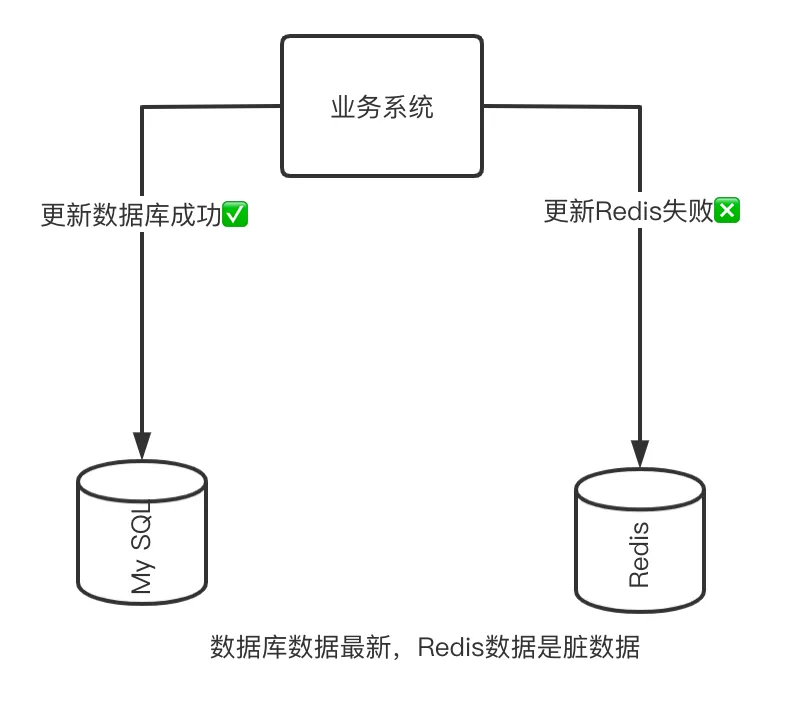
(2) The inconsistency of updating the cache before updating the database
Then you may think, does this mean that I should let the cache update first, and then update the database? Something like this:
updateRedis(key, data);//先更新缓存
updateMySQL();//再更新数据库
The problems caused by this operation are even more obvious, because we cannot guarantee the success of the database update. If the database update fails, the data you cache is not just dirty data, but wrong data.
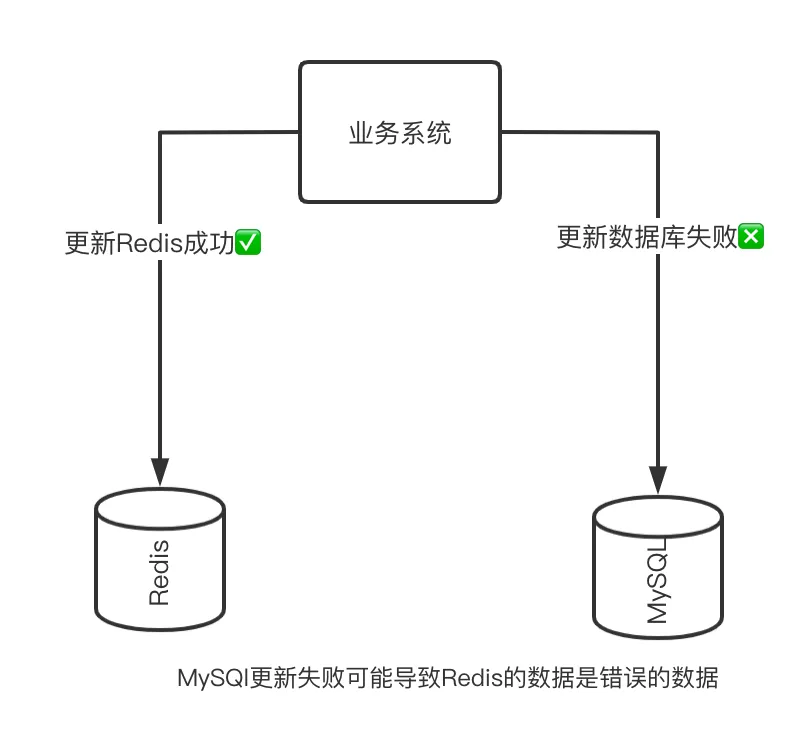
You may think, can I do Redis rollback when updating the database fails? This is actually unreliable, because we cannot guarantee that the rollback operation will be successfully executed 100%.
At the same time, in the scenario of concurrent writing and writing, there are also similar consistency problems, please see the following situation:
Thread A and thread B update the same data at the same time
The order of updating the cache is first A and then B
The order of updating the database is first B and then A
for example. Thread A wants to set the counter to 0, and thread B wants to set it to 1. According to the above scenario, the cache is indeed set to 1, but the database is set to 0.
| time | Thread A (write request ****) | Thread B (write request) | question |
|---|---|---|---|
| T1 | update cache to 0 | ||
| T2 | update cache to 1 | ||
| T3 | update database to 1 | ||
| T4 | Update database data to 0 | At this time, the cached value is explicitly updated to 1, but the actual value of the database is 0, and the data is inconsistent |
So in general, updating the cache and then updating the database is a means we should avoid.
So what if the strategy of deleting the cache is adopted? That is to say, when we update the database, we invalidate the corresponding cache, so that the cache will be updated the next time a read request is triggered. Would it be better? Similarly, let’s compare the difference between the two deletion timings before and after updating the database.
The most intuitive way, we may invalidate the cache first, and then update the database. The code logic is as follows:
deleteRedis(key);//先删除缓存让缓存失效
updateMySQL();//再更新数据库
This kind of logic seems to be no problem. After all, even if the database update fails after deleting the cache, there is no data in the cache. Then two concurrent write requests come over, no matter what the execution order is, the last value in the cache will also be deleted, that is to say, such processing is no problem under concurrent write requests.
However, this kind of processing has hidden dangers in the scenario of concurrent reading and writing.
Or just update the count example. For example, the cached data is now 100, and the database is also 100. At this time, the count needs to be reduced by 1. After the reduction is successful, the database should be 99. If a read request is triggered after this, if the cache is valid, it should also be updated to 99 to be correct.
Then consider a request like this:
While thread A updates this data, thread B reads this data
Thread A successfully deletes the old data in the cache. At this time, thread B queries the data and finds that the cache is invalid.
Thread A successfully updated the database
| time | Thread A (write request) | Thread B (read request) | question |
|---|---|---|---|
| T1 | delete cached value | ||
| T2 | 1. Read the cached data, the cache is missing, read the data from the database 100 | ||
| T3 | Update the value of data X in the database to 99 | ||
| T4 | Write the value of data 100 to the cache | At this time, the cached value is explicitly updated to 100, but in fact the value in the database is already 99 |
It can be seen that in the scenario of concurrent reading and writing, there will also be inconsistencies.
For this scenario, there is a so-called “delay double delete strategy”, that is, since it is possible to write back an old value due to a read request, after the write request is processed, I will wait until a similar time delay and then delete it. Re-delete this cached value.
| time | Thread A (write request ) | Thread C (new read request) | Thread D (new read request) | question |
|---|---|---|---|---|
| T5 | sleep(N) | The cache exists, read the cache old value 100 | Other threads may read dirty data before the double delete is successful | |
| T6 | delete cached value | |||
| T7 | Cache miss, latest value of data read from database (99) |
The key to this solution lies in the judgment of the N time. If the N time is too short, the time when thread A deletes the cache for the second time is still earlier than the time when thread B writes dirty data back to the cache, which is equivalent to doing useless work. And if N is set too long, all new requests will see dirty data before double deletion is triggered.
So if we put the update database before deleting the cache, will the problem be solved? Let’s continue to look at the scenario of concurrent reading and writing to see if there are similar problems.
| time | Thread A (write request) | Thread B (read request) | Thread C (read request) | potential problems |
|---|---|---|---|---|
| T1 | Update main library X = 99 (original value X = 100) | |||
| T2 | Read data, query cache and data, return 100 | Thread C actually read data inconsistent with the database | ||
| T3 | delete cache | |||
| T4 | Query the cache, the cache is missing, query the database to get the current value 99 | |||
| T5 | Write 99 to cache |
It can be seen that, in general, it is no problem to adopt the strategy of updating the database first and then deleting the cache. Only within the time difference between the successful update of the database and the deletion of the cache—the window of[T2T3)maybeblockedbyotherthreadsReadtotheoldvalue[T2T3)的窗口,可能会被别的线程读取到老值。
At the beginning of the article, we said that the problem of cache inconsistency cannot be completely eliminated objectively, because we cannot guarantee that the operations of the database and the cache are in one transaction, and all we can do is shorten the time window of inconsistency as much as possible.
In the scenario of deleting the cache after updating the database, the inconsistency window is only the time from T2 to T3, which is usually less than 1ms in the intranet state, and we can ignore it in most business scenarios. Because in most cases, it is difficult for a user’s request to quickly initiate a second request within 1ms.
However, in a real scenario, there is still a possibility of inconsistency. In this scenario, the read thread finds that the cache does not exist, so when reading and writing are concurrent, the read thread writes back the old value. The concurrency is as follows:
| time | Thread A (write request) | Thread B (read request–cache does not exist) | potential problems |
|---|---|---|---|
| T1 | Query the cache, the cache is missing, query the database to get the current value 100 | ||
| T2 | Update main library X = 99 (original value X = 100) | ||
| T3 | delete cache | ||
| T4 | write 100 to cache | At this time, the cached value is explicitly updated to 100, but in fact the value in the database is already 99 |
In general, the conditions for this inconsistent scenario are very strict, because when the amount of concurrency is large, the cache is unlikely to exist; if the concurrency is large, but the cache does not exist, it is likely that there are many writing scenarios at this time. Because writing the scene will delete the cache.
So we will mention later that writing scenes is often not suitable for deletion strategies.
As mentioned above, we compared the four methods of updating the cache, and made a summary and comparison, and provided references for the countermeasures. The details are not expanded, as shown in the following table:
| Strategy | concurrent scenario | potential problems | Solution |
|---|---|---|---|
| Update database + update cache | write+read | Before thread A finishes updating the cache, thread B’s read request will briefly read the old value | Can be ignored |
| write + write | The order of updating the database is first A and then B, but when updating the cache, the order is first B and then A, and the database and cache data are inconsistent | Distributed lock (heavy operation) | |
| update cache + update database | no concurrency | Thread A has not yet updated the cache but may fail to update the database | Use MQ to confirm that the database update is successful (complex) |
| write + write | The order of updating the cache is first A and then B, but the order of updating the database is first B and then A | Distributed locks (heavy operation) | |
| delete cached value + update database | write+read | Thread A of the write request deletes the cache before updating the database. At this time, the read request thread B arrives. Because the cache is missing, the current data is read out and placed in the cache, and then thread A successfully updates the database. | Delay double deletion (but the delay time is not easy to estimate, and there are still inconsistent time windows during the delay process) |
| Update database + delete cached value | write+read (cache hit) | After thread A completes the database update successfully, the cache has not been deleted, and thread B will read old dirty data if there are concurrent read requests | Can be ignored |
| write+read (cache miss) | The read request does not hit the cache, and the read request is written back to the cache after the write request is processed. At this time, the cache is inconsistent | Distributed lock (heavy operation) |
From a consistency point of view, it is a more appropriate strategy to delete the cached value after updating the database. Because the conditions for inconsistent scenarios are more stringent, the probability is lower than other schemes.
So is the strategy of updating the cache useless? no!
Deleting the cached value means that the corresponding key will become invalid, and all read requests will hit the database at this time. If the write operation of this data is very frequent, the effect of the cache will become very small. And if some keys are still very large hot keys at this time, the system may be unavailable because the data volume cannot be carried.
As shown below:
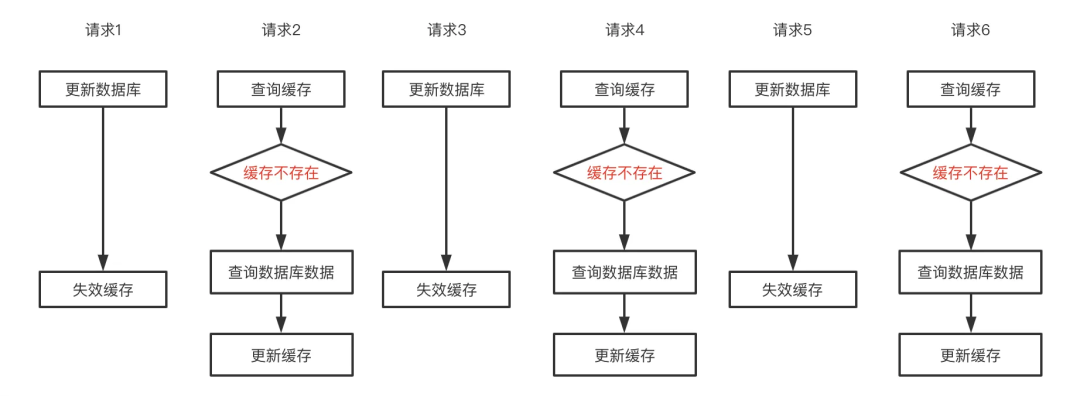
Frequent cache invalidation of the deletion strategy prevents read requests from utilizing the cache
So to make a simple summary, it is enough to adapt to the decision-making of most Internet development scenarios:
For most scenarios with more reads and fewer writes, it is recommended to choose the strategy of deleting the cache after updating the database.
For scenarios where reads and writes are equal or more writes and fewer reads, it is recommended to choose the strategy of updating the cache after updating the database.

How to guarantee the final consistency?
Cache setting expiration time
The first method is what we mentioned above. When we cannot be sure that the MySQL update is complete, the update/deletion of the cache must be successful. For example, Redis hangs and the write fails, or the network fails at that time. The service just happened to be restarted at that time, and there was no code to execute this step.
At these times, MySQL data cannot be flushed to Redis. In order to prevent this inconsistency from persisting permanently, when using the cache, we must set an expiration time for the cache, such as 1 minute, so that even if there is an extreme scenario where updating Redis fails, the inconsistent time window is only 1 minute at most.
This is our final consistency solution. In case of any inconsistency, the database can be re-queried after the cache expires, and then written back to the cache to achieve the final consistency between the cache and the database.

If the step of deleting the cache is not performed because the service is restarted, or Redis is temporarily unavailable and the deletion of the cache fails, there will be a long period of time (the remaining expiration time of the cache) for data inconsistency.
So do we have any means to reduce this inconsistency? At this time, it is a good choice to use a reliable message middleware.
Because the message middleware has an ATLEAST-ONCE mechanism, as shown in the following figure.
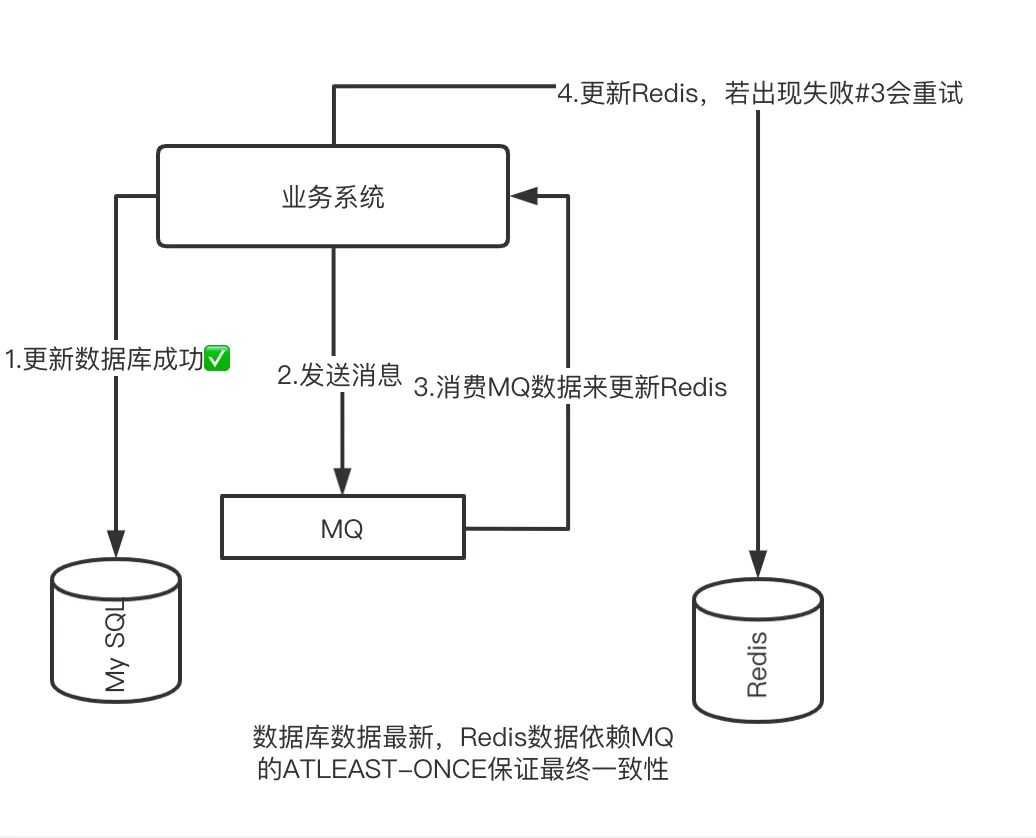
We use MQ message consumption to invalidate the corresponding Key value for the request to delete Redis. If there is an abnormality in Redis that prevents the deletion from being successful, we can still rely on the MQ retry mechanism to invalidate the Key corresponding to Redis.
And you may ask, in extreme scenarios, is there a situation where the MQ message is not sent successfully after the database is updated, or the machine restarts without a chance to send it out?
This scenario is really troublesome. If MQ uses RocketMQ, we can use RocketMQ’s transaction messages to let the cached deletion messages be sent out eventually. And if you do not use RocketMQ, or the message middleware you use does not have the feature of transactional messages, you can use the message table to make updating the database and sending messages succeed together. In fact, this topic is relatively large, and we will not expand it here.

Sometimes, the real caching scenario is not as simple as a record in the database corresponding to a Key. It is possible that the update of a database record will involve the update of multiple Keys. Another scenario is that the same Key value may need to be updated when updating records in different databases, which is common in the cache of some App homepage data.
Let’s take the scenario where one database record corresponds to multiple keys as an example.
If the system is designed, we cache a fan’s homepage information, the TOP10 fans of the anchor’s reward list, the TOP 100 fans in a single day, and other information. If the fan logs out, or the fan triggers a reward, the above multiple keys may need to be updated. Just a reward record, you may have to do:
updateMySQL();//更新数据库一条记录
deleteRedisKey1();//失效主页信息的缓存
updateRedisKey2();//更新打赏榜TOP10
deleteRedisKey3();//更新单日打赏榜TOP100
This involves multiple Redis operations, and each step may fail, affecting subsequent updates. Even from the perspective of system design, updating the database may be a separate service, but the cache maintenance of these different keys is in three different microservices, which greatly increases the complexity of the system and improves the failure of cache operations. possibility. The most frightening thing is that there is a high probability that the place to operate and update records is not only in one business logic, but distributed in various scattered locations in the system.
For this scenario, the solution is the same as the operation to ensure the final consistency mentioned above, which is to send the operation of updating the cache as an MQ message, which is subscribed by different systems or a dedicated system, and aggregated operate. As shown below:
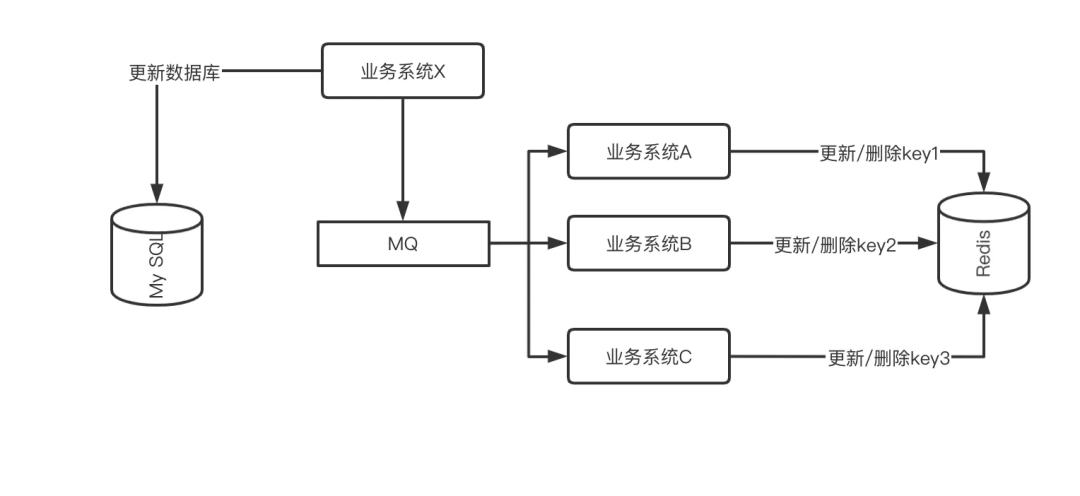 Different business systems subscribe to MQ messages and maintain their own cache keys separately
Different business systems subscribe to MQ messages and maintain their own cache keys separately
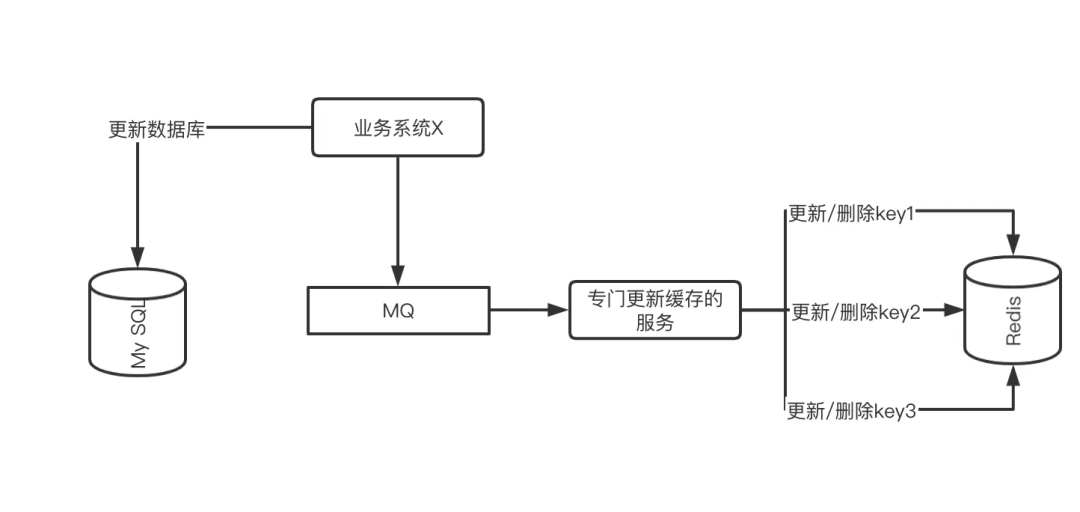
The service that specifically updates the cache subscribes to the MQ message and maintains the cache operations of all related Keys

The MQ processing method mentioned above needs to explicitly send MQ messages in the business code. Another elegant way is to subscribe to MySQL’s binlog and monitor the real changes of data to handle related caches.
For example, in the example just mentioned, if a fan triggers a reward again, we can use the binlog table to monitor and find out in time. After the discovery, it can be processed centrally, and no matter what system or location to update the data, all Can do centralized processing.
Canal is currently a similar product in the industry, and the specific operation diagram is as follows:
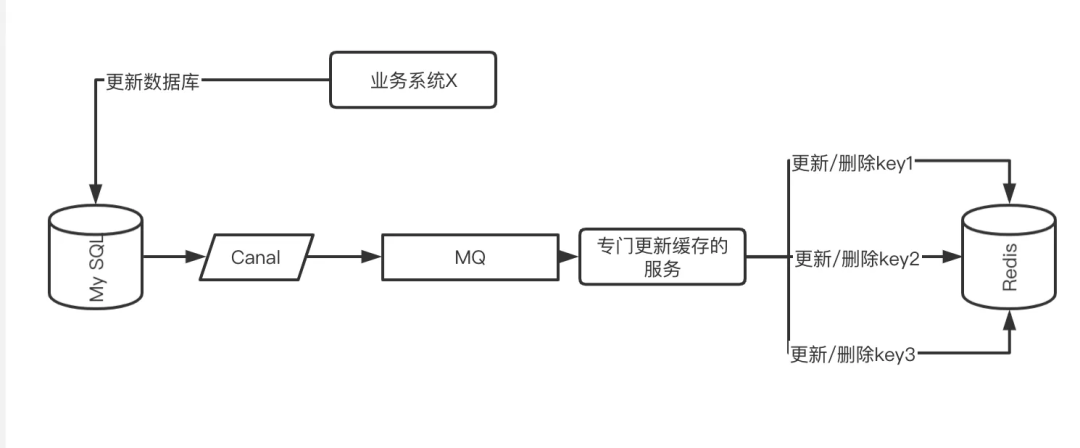
Use Canel to subscribe to database binlog changes to send MQ messages, and let a dedicated consumer service maintain all relevant Key cache operations
So far, we have described in detail how to ensure the final consistency of large-scale system cache design from the perspectives of strategies, scenarios, and operation schemes, hoping to help you.
Note: This article is based on my blog https://jaskey.github.io/blog/2022/04/14/cache-consistency/
The author’s personal email jaskeylin@apache.org, WeChat: JaskeyLam
#graphics #explain #database #cache #consistency #problem #Tencent #Cloud #Technology #Community #News Fast Delivery