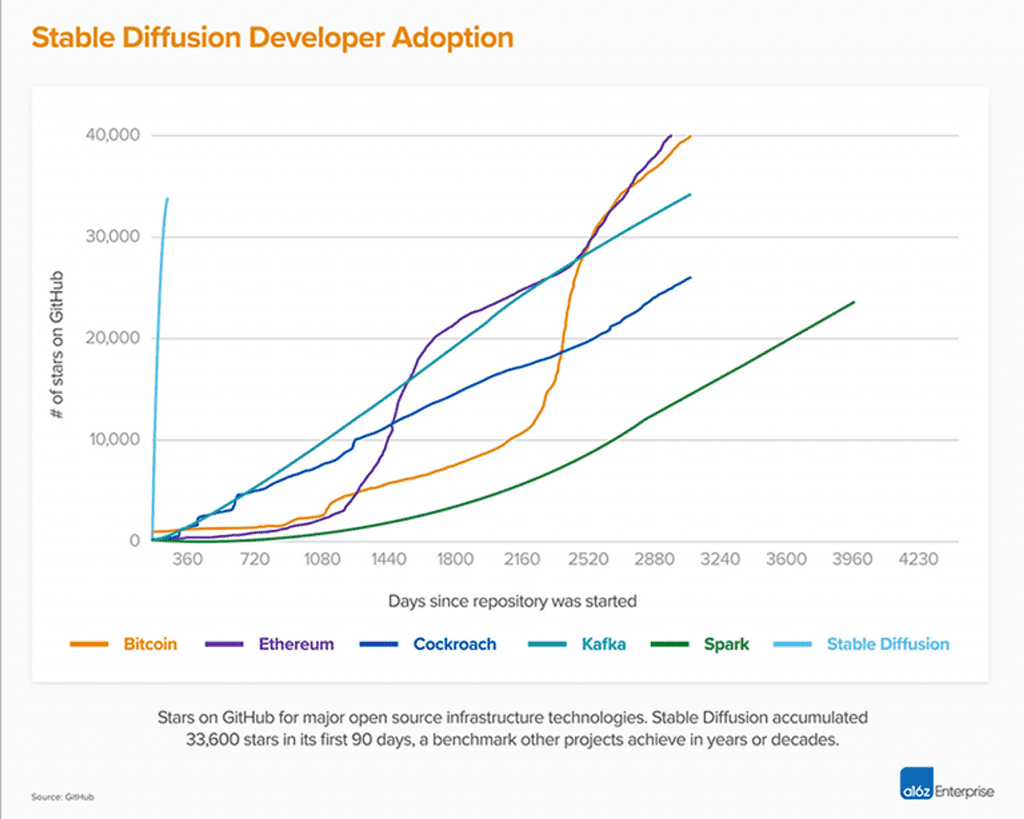
Stable Diffusion V1, led by CompVis, changed the nature of open source AI models and spawned hundreds of other models and innovations worldwide. Stable Diffusion is also now one of the fastest climbs to Github 10K Stars of any software, with its Stars soaring to 33K in less than two months.

Stable Diffusion 2.0 offers many significant improvements and features over the original V1 release.
New Text-to-Image Diffusion Model
The Stable Diffusion 2.0 release includes a text-to-image model trained with a brand new text encoder (OpenCLIP), developed by LAION with the support of Stability AI, which greatly improves the quality of generated images compared to earlier V1 releases. The text-to-image model in this release can generate images at default resolutions of 512×512 pixels and 768×768 pixels.
The models were trained on a subset of the LAION-5B dataset created by Stability AI’s DeepFloyd team, and then further filtered using LAION’s NSFW filter to remove adult content.

Super Resolution Upscaler Diffusion Model
Stable Diffusion 2.0 also includes an Upscaler Diffusion model that increases the resolution of images by a factor of 4. Below is an example of the model upscaling a low resolution image (128×128) to a high resolution image (512×512). Combined with the text-to-image model, Stable Diffusion 2.0 can now generate images with a resolution of 2048×2048 or higher.

Depth-to-Image (depth to image) Diffusion model
The new depth-guided stable diffusion model, called depth2img, extends the previous image-to-image functionality of V1, opening up entirely new possibilities for creative applications. depth2img infers the depth of an input image (using an existing model), then uses the text and depth information to generate a new image.

Depth to image can provide a variety of new creative applications, providing a completely different transformation from the original image, but still retaining the consistency and depth information of that image.
Updated Inpainting Diffusion model
The new version also includes a new text-guided painting model, fine-tuned on the new Stable Diffusion 2.0 base text-to-image, which makes it easier to intelligently and quickly switch out parts of an image.

Stability AI will publish these models to the API platform (platform.stability.ai) and DreamStudio in the coming days.
More details can be viewed: https://stability.ai/blog/stable-diffusion-v2-release
#Stable #Diffusion #Released #Enhanced #Adult #Content #Filtering #News Fast Delivery