Bytedance feature storage pain points
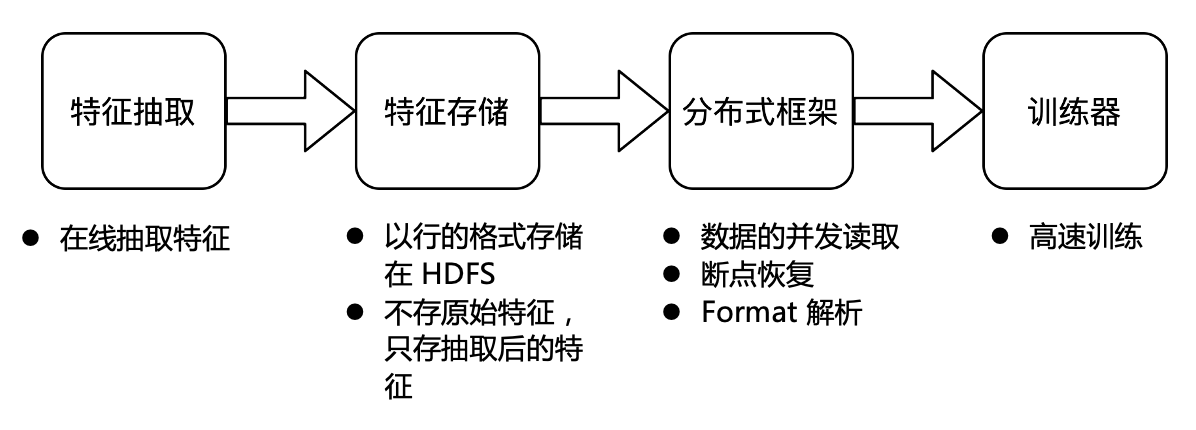
The overall process of feature storage in the current industry is mainly divided into the following four steps:
The overall process of feature storage
Online business feature module extraction;
The extracted features are stored in HDFS in row format. Considering the cost, the original features are not stored at this time, only the extracted features are stored;
The distributed framework developed by ByteDance will concurrently read and decode the stored features and send them to the trainer;
The trainer is responsible for high-speed training.
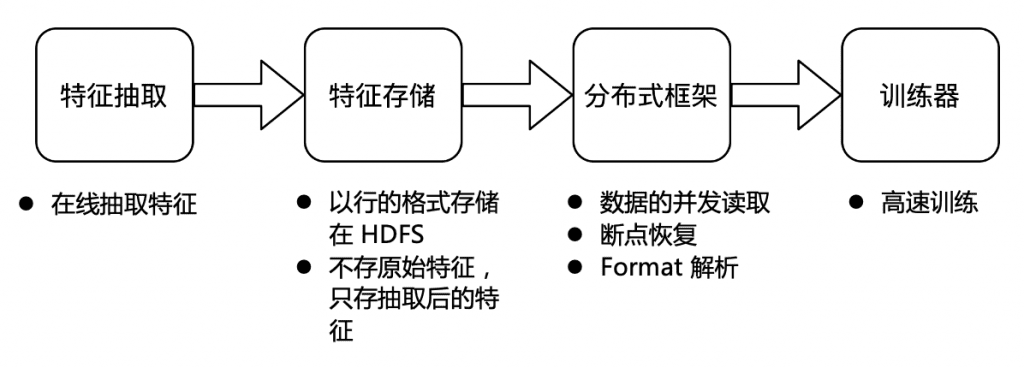
Byte Beat FeaturesThe total storage is EB level,dailyIncrement reaches PB leveland the daily resources used for training also reachedmillion cores, so the overall size of byte storage and calculation is very large. Under such a volume, we encountered the following three pain points:
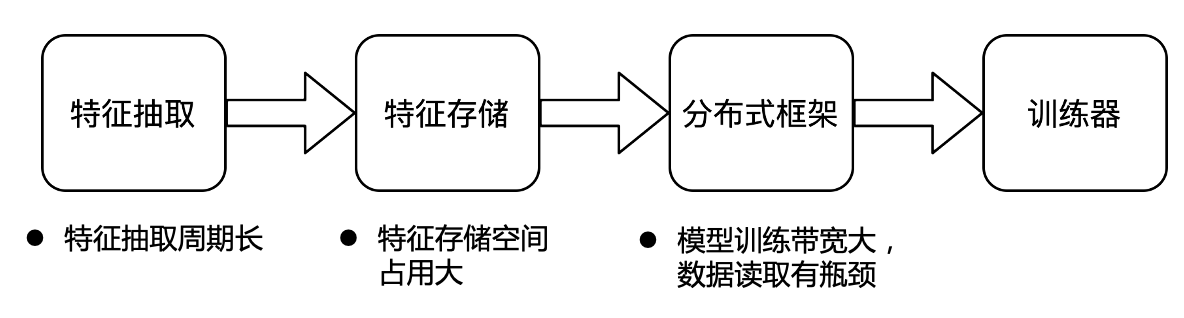

The feature extraction cycle is long.In terms of feature extraction, the online extraction method is currently used. A large number of algorithm engineers are conducting a large number of feature-related experiments every day. In the current online extraction mode, if an algorithm engineer wants to investigate a new feature, he first needs to define the calculation method of the feature, wait for the unified launch of the online module, and then wait for the online extracted features to accumulate to a certain level Only after training can we judge whether this feature is effective. This process usually takes 2 weeks or longer. And, if you find that the calculation logic of the feature is written incorrectly or you want to change the calculation logic, you need to repeat the above process. Online feature extraction leads to very inefficient current byte feature surveys. Based on the current architecture, the cost of offline feature research is very high.
Feature storage takes up a lot of space.The feature storage of bytes is currently stored in the form of row storage. If you do feature research based on the current line storage, you need to generate a new data set based on the original path. On the one hand, additional space is required to store new data sets, and on the other hand, additional computing resources are required to read the original full amount of data to generate new data, and it is difficult to manage and reuse data. For feature storage, line storage is also difficult to optimize and takes up a lot of space.
The model training bandwidth is large, and the data reading has a bottleneck.Byte currently stores most of the features of each business line under one path, and training will be directly based on this path during training. For each model, the features required for training are different. Each business line may have tens of thousands of features, and most model training often only needs a few hundred features, but because the features are stored in the row storage format , so it is necessary to read tens of thousands of features during training, and then filter them in memory, which makes the bandwidth requirement of model training very large, and data reading becomes the bottleneck of the entire training.
Requirements sorting based on pain points
Based on the above problems, we have summarized several requirements with the business side:
Store original features: Due to the inefficiency of online feature extraction in feature investigation, we expect to be able to store original features;
Offline research capability: On the basis of the original features, offline research can be carried out, thereby improving the efficiency of feature research;
Support feature backfill: support feature backfill, after the survey is completed, all the historical data can be brushed with the surveyed features;
Reduce storage costs: make full use of the particularity of data distribution, reduce storage costs, and free up resources to store original features;
Reduce training cost: Only read the required features during training, instead of full features, reducing training costs;
Improve training speed: Minimize data copying and serialization and deserialization overhead during training.
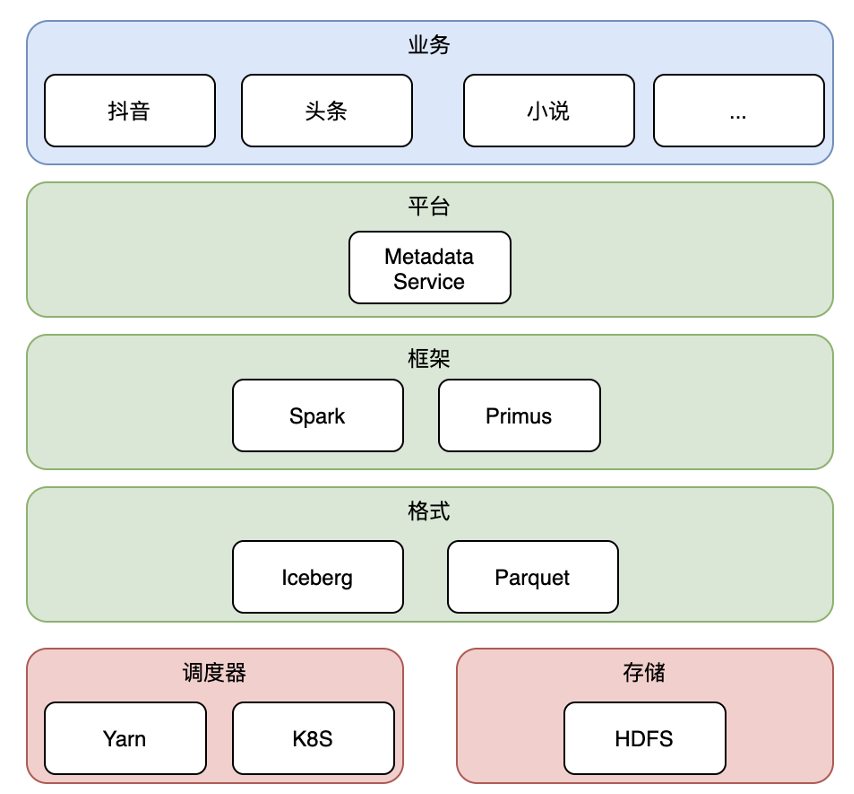
In Byte’s overall structure, the top layer is the business layer, including most of Byte’s business lines such as Douyin, Toutiao, and novels;
Next, we provide business students with easy-to-use UI and access control functions through the platform layer;
At the framework layer, we use Spark as the feature processing framework (including preprocessing and offline feature research, etc.), and Byte’s self-developed Primus as the training framework;
existformat layer,usselectParquet as the file format,Iceberg as tabular;
The lowest layer is the scheduler Yarn & K8s and storage HDFS.
Below we focus onformat layerfor details.
Technology Selection


In order to meet the six requirements mentioned by the business side, we first thought of using the Parquet column storage format to reduce the storage cost of the row storage, and the saved space can be used to store the original features. At the same time, due to the feature that Parquet column selection can be pushed down to the storage layer, only the required features can be read during training, thereby reducing the cost of deserialization during training and improving the speed of training.
However, using Parquet introduces additional problems. The original line storage is based on the semi-structured data defined by Protobuf, and there is no need to pre-define the Schema. After using Parquet, we need to know the Schema before we can access the data. Then in When features are added or eliminated, Schema update is a difficult problem to solve. Parquet does not support data backfilling. If you want to backfill the data of several years, you need to read the data in full, add new columns, and then write it back in full. On the one hand, it will waste a lot of computing resources. On the other hand, when doing feature backfilling The overwrite operation will cause the task currently being trained to fail due to the file being replaced.
In order to solve these problems, we introduced Iceberg to support schema evolution, feature backfill and concurrent read and write.
Iceberg is an open source table format suitable for large datasets. It has features such as schema evolution, hidden partition & partition evolution, transaction, MVCC, computing and storage engine decoupling, etc. These features match all our needs. Therefore, we chose Iceberg as our data lake.
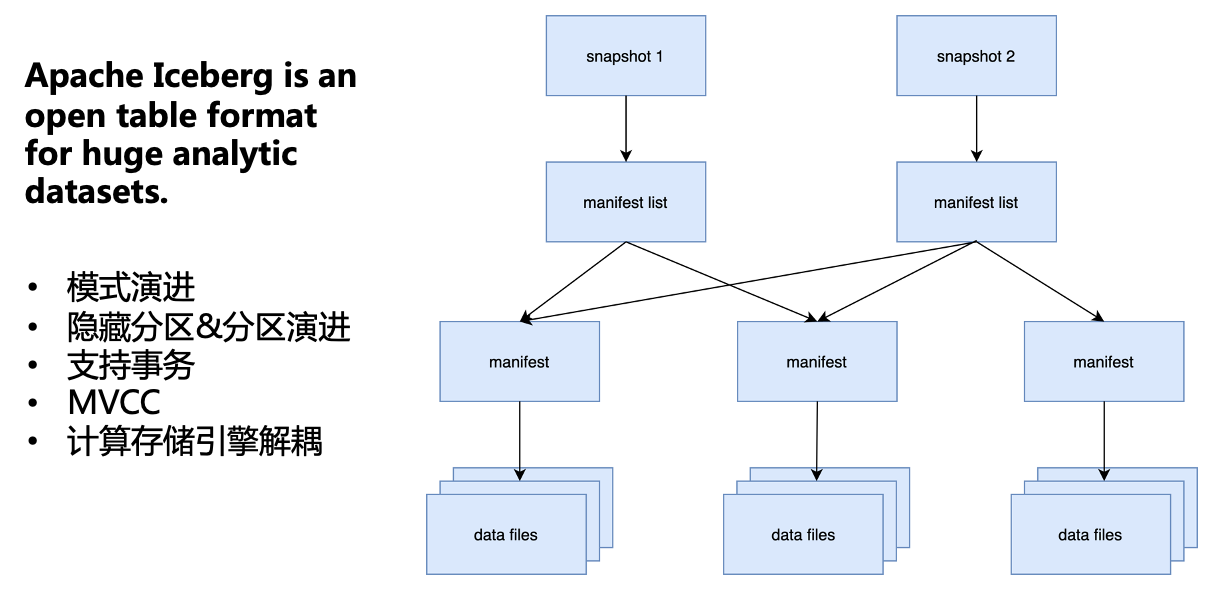
Overall, Iceberg is a layered structure. The snapshot layer stores all the snapshots of the current table; the manifest list layer stores the manifest cloud data contained in each snapshot. The purpose of this layer is mainly for multiple snapshots to be reused in the next The manifest of the layer; the manifest layer stores the metadata of the underlying Data Files; the bottom Data File is the actual data file. Through such a multi-layer structure, Iceberg can support the above-mentioned several features including schema evolution.
Let’s go one by oneDescribes how Iceberg supports these features.
ByteDance Massive Feature Storage Solution
concurrent read and write
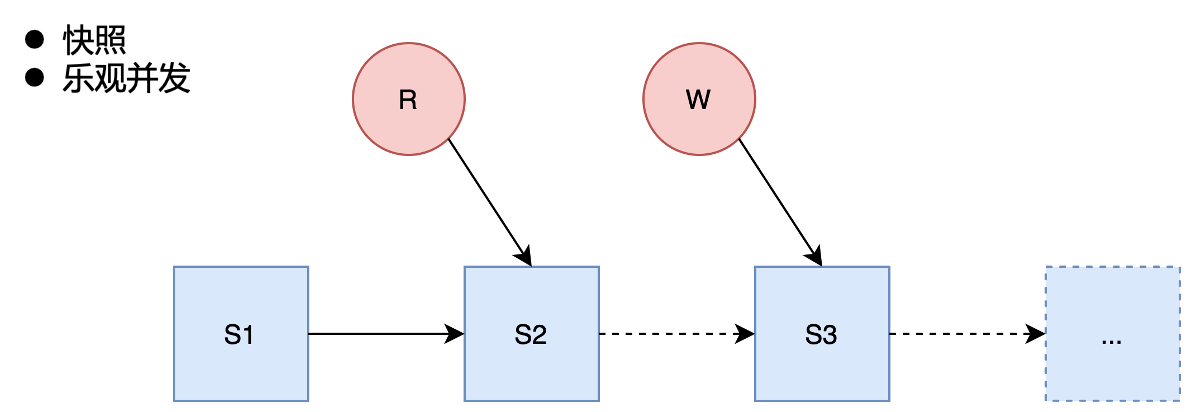

In terms of concurrent reading, Iceberg is a snapshot-based read. Each operation on Iceberg will generate a new snapshot without affecting the snapshot being read, thus ensuring that reading and writing do not affect each other.
In terms of concurrent writing, Iceberg adopts an optimistic concurrency method, using the atomic semantics of HDFS mv to ensure that only one can be written successfully, while other concurrent writing will be checked for conflicts. If there is no conflict, write the next A snapshot.
schema evolution

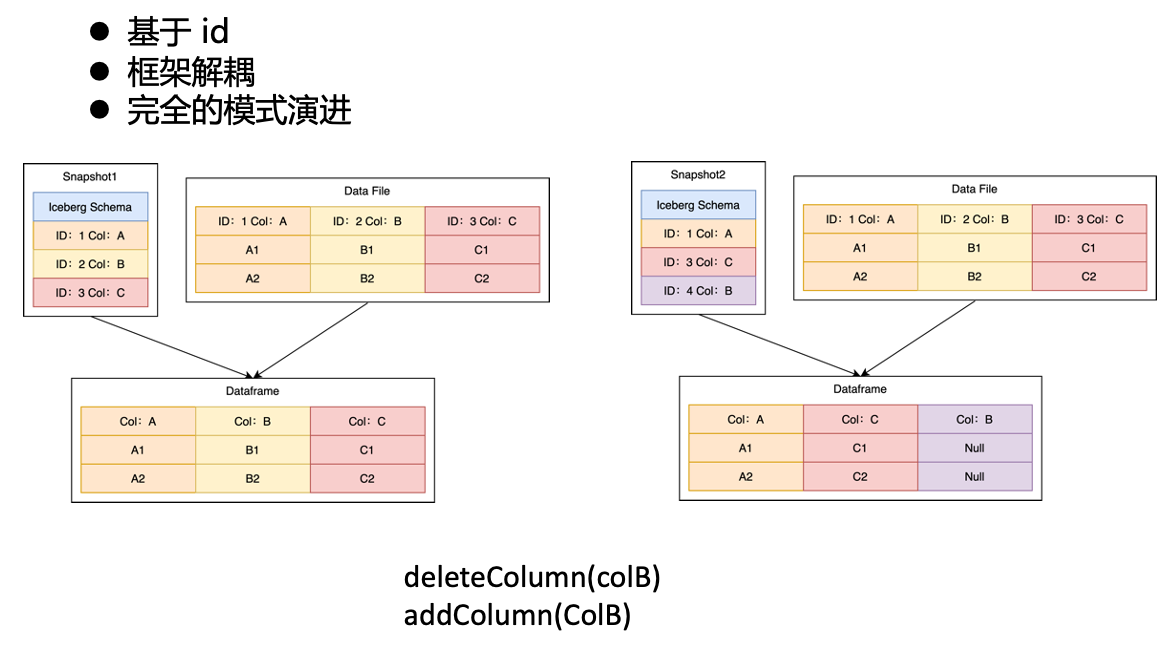
Iceberg’s Schema Evolution Principles
We know that both Iceberg metadata and Parquet metadata have Columns, and the intermediate mapping relationship is one-to-one mapping through the ID field.
For example, in the left figure above, Iceberg and Parquet have three columns ABC, corresponding to ID 1, 2, and 3. The final read Dataframe is consistent with Parquet and contains ABC three columns with IDs 1, 2, and 3. And when we perform two operations on the left picture, delete the old B column, and write the new B column, the three column IDs corresponding to Iceberg will become 1, 3, 4, so the Dataframe read in the right picture, although There are also three columns ABC, but the ID of column B is not the ID of column B in Parquet, so in the final actual data, column B is null.
feature backfill

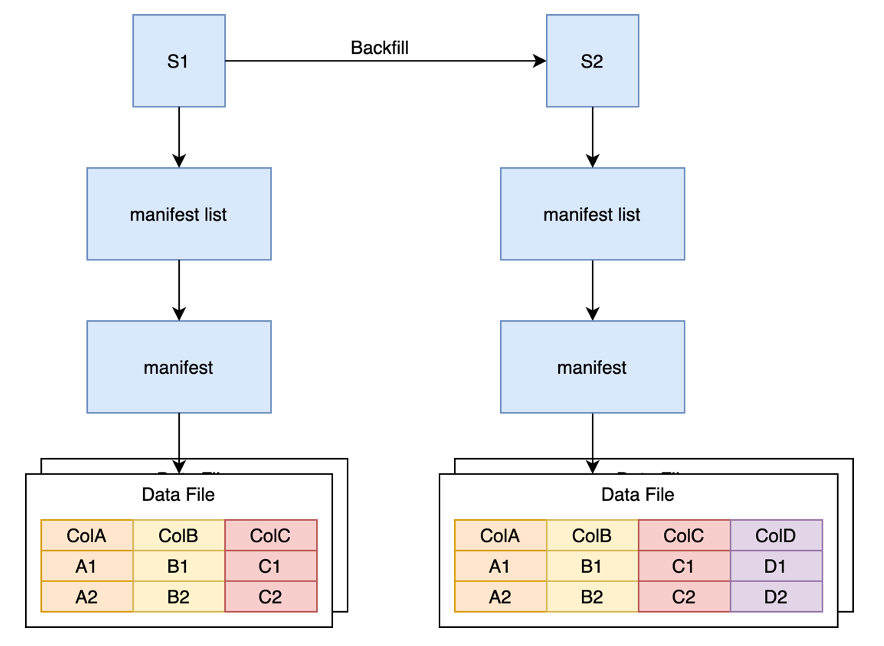
As shown in the figure above, the feature backfill of the COW method reads all the data in the original snapshot through a Backfill task, then writes it into a new column, writes it out to a new Data File, and generates a new snapshot.
The disadvantage of this method is that although we only need to write one column of data, we need to read out all the data and then write it back. This not only wastes a lot of computing resources for encoding and decoding the entire Parquet file, but also wastes a lot of time. IO to read the full amount of data, and waste a lot of storage resources to store duplicate ABC columns.
Therefore, we developed the MOR Backfill solution based on the open source Iceberg.
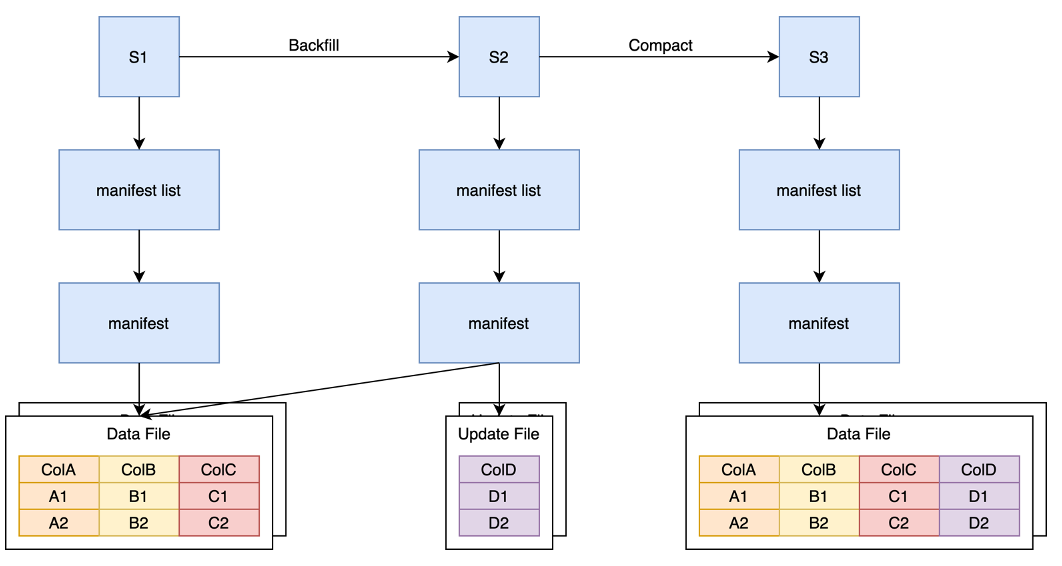

As shown in the figure above, in the MOR scheme, we still need a Backfill task to read the original Data File, but here we only read the required fields. For example, we only need column A to generate column D through some calculation logic, then the Backfill task only reads the data of A, and only the update file containing column D needs to be written in Snapshot2. With the increase of new columns, we also need to merge the Update file back into the Data File file.
For this reason, we also provide Compaction logic, that is, to read the old Data File and Update File and merge them into a single Data File.

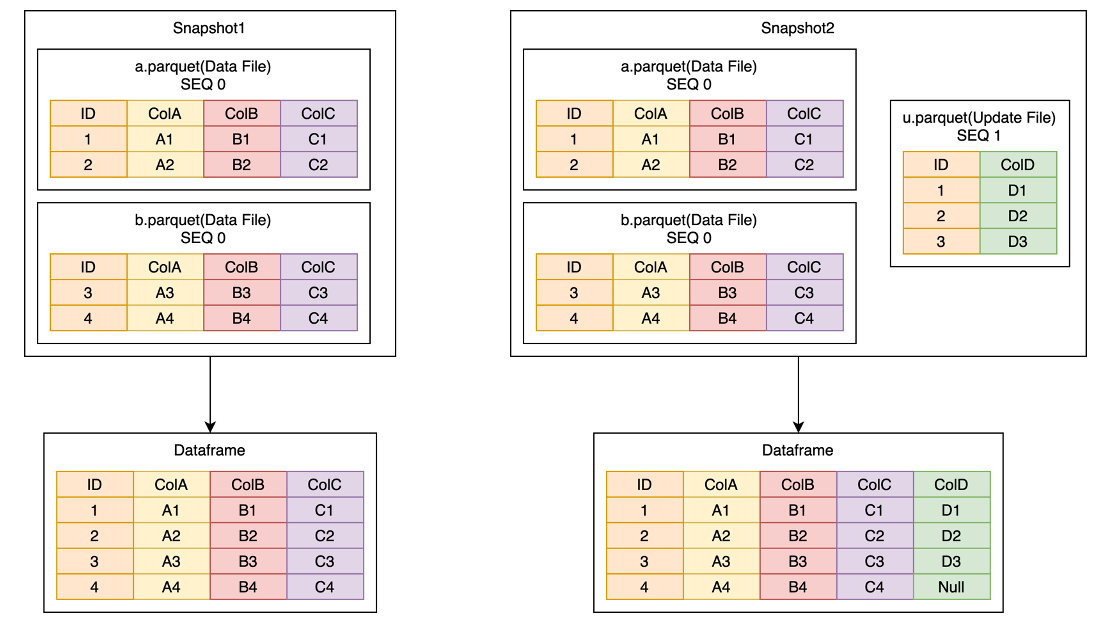
The principle of MOR is as shown in the figure above, assuming that there is a logical Dataframe composed of two Data Files, and now it is necessary to backfill the contents of a ColD. We will write an Update File containing ColD so that the logical Dataframe in Snapshot2 will contain four columns ABCD.
Implementation details:
- Both Data File and Update File need a primary key, and each file needs to be sorted by the primary key, in this case ID;
- When reading, it will analyze which Update File and Data File are needed according to the column selected by the user;
- Select the Update File corresponding to the Data File according to the min-max value of the primary key in the Data File;
- The entire process of MOR is a process of multiple merging of multiple Data Files and Update Files;
- The order of merging is determined by SEQ, and data with a large SEQ will overwrite data with a small SEQ.

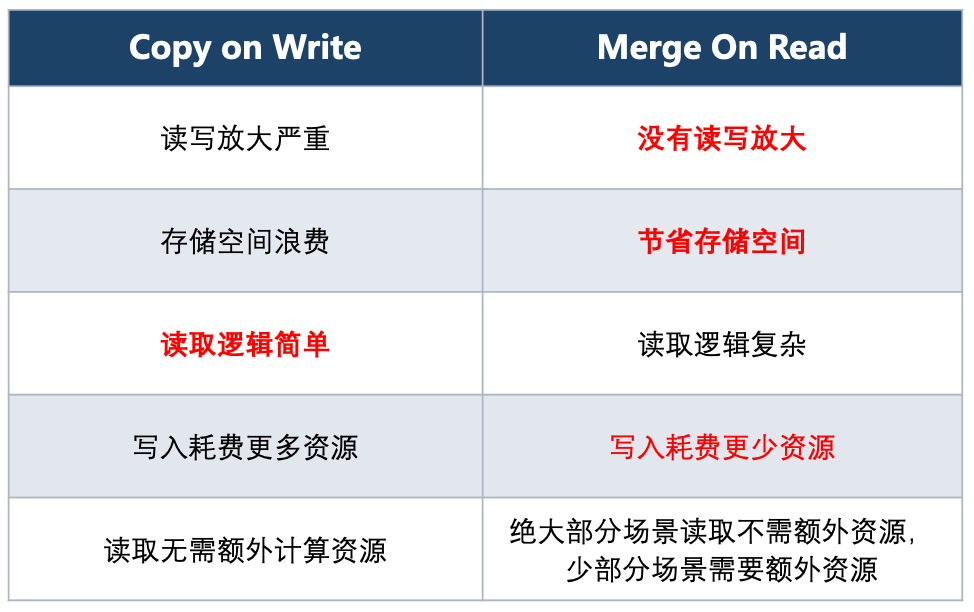
Compared with the COW method, which reads and writes all columns in full, the advantage of MOR is that only the required columns are read and updated columns are written, and there is no problem of read-write amplification. It saves a lot of computing resources, and greatly reduces the IO of reading and writing. Compared with the COW method, which doubles the COW every time, MOR only needs to store new columns, which greatly avoids the waste of storage resources.
Considering the performance overhead, we need regular compaction. Compaction is a relatively heavy operation, comparable to COW. However, Compaction is an asynchronous process, and one Compaction can be performed after multiple MORs. Then the overhead of one compaction can be amortized to multiple MORs. For example, compared with 10 times of COW and 10 times of MOR + 1 time of compaction, the storage and read and write costs are reduced from the original 10x to the current 2x.
MOR is expensive to implement, but this can be addressed with good design and extensive testing.
For model training, since most model training only needs its own columns, a large number of online models do not need to follow the logic of MOR, and it can be said that there is basically no overhead. And a small number of research models often only need to read their own Update File instead of other Update Files, so the overall additional resources for reading do not increase too much.
training optimization
After changing from line storage to Iceberg, we also made a lot of optimizations in training.
In our original architecture, the distributed training framework does not parse the actual data content, but directly transmits the data to the trainer in the form of rows, and the trainer performs operations such as deserialization and column selection internally.
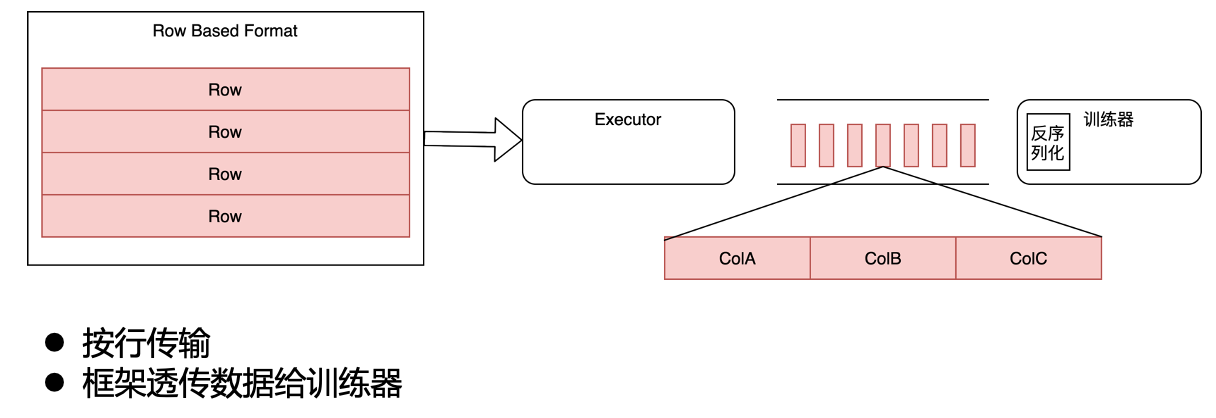
original architecture
After the introduction of Iceberg, if we want to get the CPU and IO benefits brought by the column selection, we need to push the column selection down to the storage layer. Initially, in order to ensure that the downstream trainer does not perceive it, we deserialize the selected column at the training framework level, construct it into the original ROW format, and send it to the downstream trainer. Compared with the original, there is an additional layer of serialization and deserialization overhead.
As a result, after migrating to Iceberg, the overall training speed slowed down and resources increased.
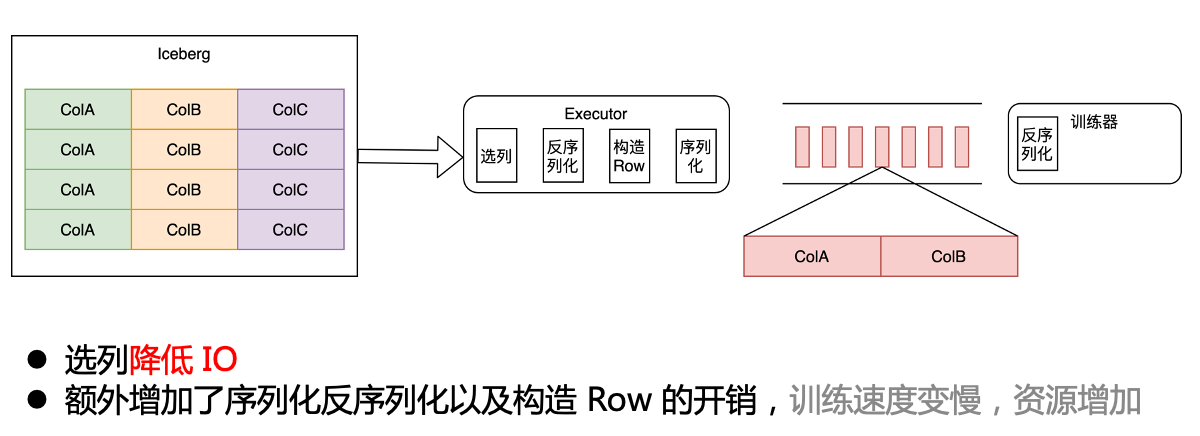
column transformation
In order to improve the training speed, we directly read the Iceberg data into Batch data and send them to the trainer through vectorized reading. This step improves the training speed and reduces some resource consumption.
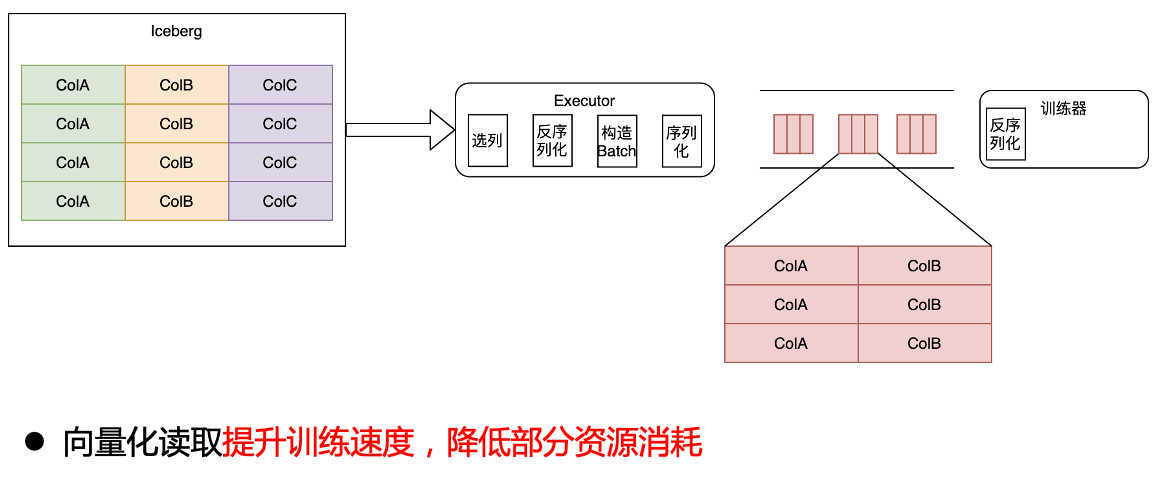

vectorized read
In order to achieve the best results, we cooperated with the trainer team and directly modified the inside of the trainer so that the trainer can directly recognize the Arrow data, so that we realized the end-to-end Arrow format from Iceberg to the trainer, so that we only need to At the beginning, it is deserialized into Arrow, and subsequent operations are completely based on Arrow, thereby reducing serialization and deserialization overhead, further improving training speed, and reducing resource consumption.
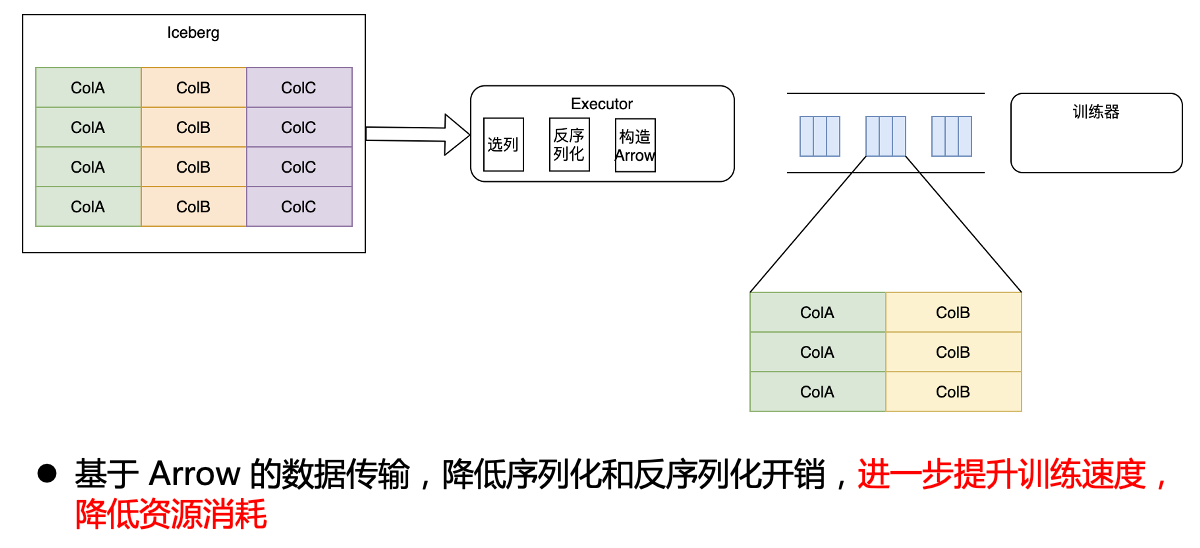
Arrow
Optimize revenue
Finally, we achieved our original goal and achieved the capability of offline feature engineering.
In terms of storage costs, it is generally reduced by more than 40%; at the same training speed, the CPU is reduced by 13%, and the network IO is reduced by 40%.
In the future, we plan to support the following four capabilities:
The capability of Upsert supports partial data backflow of users;
The ability of materialized view supports users to create materialized views on commonly used data sets to improve reading efficiency;
Data Skipping capability to further optimize data arrangement, push down more logic, and further optimize IO and computing resources;
Based on Arrow’s data preprocessing capabilities, it provides users with a good data processing interface, and at the same time, preprocessing is expected in advance to further accelerate subsequent training.
byte beatingInfrastructure Batch Computing TeamOngoing recruitment,The batch computing team is responsible for ByteDance offline data processing & distributed training, supporting business scenarios such as offline ETL & machine learning within the company. The components involved include offline computing engine Spark/self-developed distributed training framework Primus/feature storage Feature Store (such as Iceberg/Hudi)/Ray et al. Facing the ultra-large-scale scenario of bytes, a lot of function and performance optimization have been done in Spark/Primus/Feature Store, etc., and at the same time, it supports the implementation of the new generation of distributed application framework Ray in the company’s relevant scenarios.
Work location: Beijing/Hangzhou
Contact information: Wechat bupt001, or send your resume to qianhan@bytedance.com
#ByteDances #massive #feature #storage #practice #based #Iceberg #Personal #Space #ByteDance #Cloud #Native #Computing #News Fast Delivery