Summary:This article focuses on several ways to improve program performance by optimizing Cache usage.
This article is shared from HUAWEI CLOUD community “Things about Compiler Optimization (7): Cache Optimization”, author: Assistant Bi Sheng.
introduction
Software developers often expect computer hardware to have unlimited capacity, zero access delay, unlimited bandwidth, and cheap memory, but the reality is that the larger the memory capacity, the longer the corresponding access time; the faster the memory access speed, the more expensive the price; the bandwidth The bigger it is, the more expensive it is. In order to solve the contradiction between large capacity, high speed, and low cost, based on the principle of locality of program access, more commonly used data is placed in small-capacity high-speed memory, and various memories with different speeds are cascaded in layers to coordinate work.

Figure 1 memory hierarchy for server [1]
The storage hierarchy of modern computers can be divided into several layers. As shown in Figure 1, registers are located inside the processor; a little farther away is the first-level cache, which can generally store 64k bytes, and it takes about 1ns to access it. At the same time, the first-level cache is usually divided into instruction cache (processing The processor fetches the instruction to be executed from the instruction cache) and the data cache (the processor stores/fetches the operand of the instruction from the data cache); then there is the second-level cache, which usually saves both instructions and data, with a capacity of about 256k, accessing it It takes about 3-10ns; then there is a three-level Cache with a capacity of about 16-64MB, and it takes about 10-20ns to access it; then there is main memory, hard disk, etc. Note that CPU and Cache are transmitted in word, and Cache to main memory is transmitted in blocks (generally 64byte).
The principle of program locality was mentioned above, which generally refers to temporal locality (a program may access the same memory space multiple times within a certain period of time) and spatial locality (a program may access nearby memory spaces within a certain period of time) ), the efficiency of the cache (Cache) depends on the locality of the space and time of the program. For example, a program repeatedly executes a loop. Ideally, the first iteration of the loop fetches code into the cache, and subsequent iterations fetch data directly from the cache without reloading from main memory. Therefore, in order to achieve better performance of the program, data access should occur in the cache as much as possible. However, if data access conflicts in the cache, it may also cause performance degradation.
Due to space reasons, this article focuses on what the compiler can do in Cache optimization. If readers are interested in other memory-level optimizations, please leave a message. The following will introduce several ways to improve program performance by optimizing Cache usage.
Alignment and layout
Modern compilers can improve the Cache hit rate by adjusting the layout of code and data, thereby improving program performance. This section mainly discusses the impact of data and instruction alignment and code layout on program performance. In most processors, Cache to main memory is transmitted by Cache line (generally 64Byte, also called Cache block in some places, this article uses Cache line uniformly) , The CPU loads data from the memory one cache line at a time, and the CPU writes data to the memory one cache line at a time. Assume that the processor accesses data object A for the first time, and its size is exactly 64 bytes. If the first address of data object A is not aligned, that is, data object A occupies part of two different Cache lines. At this time, the processor needs two cache lines to access the data object. memory access, low efficiency. However, if the data object A is memory-aligned, that is, it happens to be in a Cache line, then the processor only needs one memory access when accessing the data, and the efficiency will be much higher. The compiler can arrange data objects reasonably, avoid unnecessary spanning them in multiple Cache lines, try to make the same object concentrate in one Cache, and then effectively use Cache to improve the performance of the program. Objects are allocated sequentially, that is, if the next object cannot be placed in the remaining part of the current Cache line, skip the remaining part, allocate the object from the beginning of the next Cache line, or allocate objects of the same size in the In the same storage area, all objects are aligned on the boundaries of multiples of size to achieve the above purpose.
Cache line alignment may lead to waste of storage resources, as shown in Figure 2, but the execution speed may be improved accordingly. Alignment can be applied not only to global static data, but also to data allocated on the heap. For global data, the compiler can notify the linker through the assembly language alignment directive.For data allocated on the heap, the work of placing objects on the boundaries of cache lines or minimizing the number of times objects cross cache lines is not done by the compiler, but by the storage allocator in runtime[2].
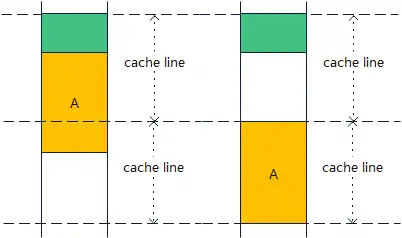
Figure 2 May waste storage space due to block alignment
As mentioned earlier, data object alignment can improve program performance. The alignment of the instruction cache can also improve program performance. At the same time, the code layout will also affect the performance of the program. Aligning the first address of the frequently executed basic block on the size multiple boundary of the Cache line can increase the number of basic blocks that can be accommodated in the instruction cache at the same time, and align the infrequently executed instructions with the frequently executed instructions. The instructions of the instructions are placed in different Cache lines, and the program performance is improved by optimizing the code layout.
Take advantage of hardware assistance
Cache prefetching is to store instructions and data in the memory into the Cache in advance to speed up the execution speed of the processor. Cache prefetch can be realized by hardware or software. Hardware prefetch is realized by a special hardware unit in the processor. Read these data from the main memory to the Cache; software prefetch is to insert prefetch instructions explicitly in the program, and let the processor read the specified address data from the memory to the Cache in a non-blocking manner. Since the hardware prefetcher cannot normally be closed dynamically, software prefetching and hardware prefetching coexist in most cases, and software prefetching must cooperate with hardware prefetching to achieve better results. This article assumes that the hardware prefetcher is turned off, and discusses how to use software prefetch to achieve performance improvement.
The prefetch instruction prefech(x) is just a reminder to tell the hardware to start adding the addressxThe data in the cache is read from the main memory to the cache. It does not cause a processing stall, but if the hardware detects that an exception will be generated, the prefetch operation will be ignored.If prefech(x) is successful, it means that the next fetchxWill hit the Cache; an unsuccessful prefetch operation may cause a Cache miss on the next read, but it will not affect the correctness of the program[2].
How does data prefetching change program performance? The following program:
double a[n];
for (int i = 0; i < 100; i++)
a[i] = 0;Suppose a Cache line can store two double elements, when accessing a for the first time[0]when, due to a[0]If it is not in the Cache, a Cache miss will occur, and it needs to be loaded into the Cache from the main memory. Since a Cache line can store two double elements, when accessing a[1]Cache miss will not occur. And so on, visit a[2]A Cache miss will occur when accessing a[3]Cache miss does not occur when , we can easily get a total of 50 cache misses in the program.
We can reduce the number of Cache misses and improve program performance through related optimizations such as software prefetching.First introduce a formula[3]:
In the above formula, L is the memory latency, and S is the shortest time to execute a loop iteration. iterationAhead indicates that the loop needs to execute several iterations before the prefetched data reaches the Cache. Assuming that iterationAhead=6 calculated by our hardware architecture, the original program can be optimized into the following program:
double a[n];
for (int i = 0; i < 12; i+=2) //prologue
prefetch(&a[i]);
for (int i = 0; i < 88; i+=2) { // steady state
prefetch(&a[i+12]);
a[i] = 0;
a[i+1] = 0;
}
for (int i = 88; i < 100; i++) //epilogue
a[i] = 0;Because our hardware architecture needs to execute the loop 6 times, the prefetched data will reach the Cache. A Cache line can store two double elements. In order to avoid wasting prefetch instructions, both prologue and steady state loops are expanded, that is, prefetch(&a[0]) will replace a[0]、a[1]Loaded from the main memory into the Cache, there is no need to reload a[1]Loaded from main memory to Cache. The prologue loop first executes the prefetch instructions of the first 12 elements of the array a, and waits until the steady state loop is executed. When i = 0, a[0]and a[1]has been loaded into the Cache, there will be no Cache miss. By analogy, after the above optimization, without changing the semantics, by using prefetch instructions, the number of cache misses of the program will be reduced from 50 to 0, and the performance of the program will be greatly improved.
Note that prefetching does not reduce the latency of fetching data from main memory to cache, it just hides this latency by overlapping prefetching with computation. In short, when the processor has a prefetch instruction or a non-blocking read instruction that can be used as a prefetch, for the processor cannot dynamically rearrange instructions or the dynamic rearrangement buffer is smaller than the specific Cache latency we want to hide, and all Prefetching is applicable when the considered data is larger than the Cache or it is impossible to determine whether the data is already in the Cache. Prefetching is not a panacea. Improper prefetching may cause cache conflicts and degrade program performance. We should first use data reuse to reduce latency, and then consider prefetching.
In addition to software prefetching, ARMv8 also provides Non-temporal Load/Store instructions, which can improve Cache utilization. For some data, if you only access it once and do not need to occupy the Cache, you can use this command to access it, so as to protect the key data in the Cache from being replaced. For example, in the scenario of memcpy big data, using this command is useful for its key business. certain income.
cyclic transformation
Reusing data in the Cache is the most basic way to use the Cache efficiently. For multi-layer nested loops, you can exchange two nested loops (loop interchange), reverse the order of loop iteration execution (loop reversal), merge two loop bodies into one loop body (loop fusion), and loop split (loop distribution), loop tiling, loop unroll and jam and other loop transformation operations. Choosing an appropriate loop transformation method can not only maintain the semantics of the program, but also improve the performance of the program. The main reason we do these loop transformations is to achieve optimizations in the use of registers, data caches, and other storage hierarchies.
Space is limited. This section only discusses how loop tiling improves program performance. If you are interested in loop interchange,PleaseclickCheck out. Here’s a simple loop:
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
x = x+a[i]+c*b[j];
}
}We assume that the arrays a and b are both very large arrays, m and n are equal and both are large, and the program will not have an out-of-bounds access to the array. then if b[j]When the span in the j-level loop is too large, the data has been cleared out of the cache when it is reused by the next i-level loop. i.e. program access b[n-1]when b[0]b[1]The cache has been cleared. At this time, the data needs to be reloaded from the main memory to the cache, and the program performance will be greatly reduced.
How can we improve program performance by reducing the number of Cache misses? By doing loop tiling on the loop, we can meet our expectations, that is, through loop rearrangement, the data is divided into tiles, so that the data of each tile can be hinted in the Cache[4]. Start tiling from the inner loop, assuming that the size of the tile is t, t is much smaller than m and n, and the value of t makes b[t-1]when accessed b[0]Still in the Cache, the number of Cache misses will be greatly reduced. Assuming that n-1 is exactly divisible by t, the access sequence of the b array is as follows:
i=1; b[0]、b[1]、b[2]...b[t-1]
i=2; b[0]、b[1]、b[2]...b[t-1]
...
i=n; b[0]、b[1]、b[2]...b[t-1]
...
...
...
i=1; b[n-t]、b[n-t-1]、b[n-t-2]...b[n-1]
i=2; b[n-t]、b[n-t-1]、b[n-t-2]...b[n-1]
...
i=n; b[n-t]、b[n-t-1]、b[n-t-2]...b[n-1]After loop tiling, the loop is transformed into:
for(int j = 0; j < n; j+=t) {
for(int i = 0; i < m; i++) {
for(int jj = j; jj < min(j+t, n); jj++) {
x = x+a[i]+c*b[jj];
}
}
}Assuming that each Cache line can hold X array elements, the number of Cache misses of a before loop tiling is m/X, the number of Cache misses of b is m*n/X, and the total number of Cache misses is m*(n+1) /x. After loop tiling, the number of cache misses of a is (n/t)*(m/X), the number of cache misses of b is (t/X)*(n/t)=n/X, and the total number of cache misses is n *(m+t)/xt.At this time, since n is equal to m, the Cache miss can be reduced by about t times after loop tiling[4].
The previous article discussed how loop tiling can improve program performance in small use cases. In short, for different loop scenarios, choosing an appropriate loop exchange method can not only ensure the correct semantics of the program, but also obtain opportunities to improve program performance.
summary
Your honey is his arsenic. For different hardware, we need to combine the specific hardware architecture, use performance analysis tools, analyze reports and programs, think about problems from the system level and algorithm level, and often have unexpected gains. This article briefly introduces several methods related to memory level optimization, and explains some knowledge related to memory level optimization in a simple way with some small examples. What is learned on paper is superficial, and we know that this matter must be practiced. More knowledge related to performance optimization needs to be explored slowly in practice.
refer to
John L. Hennessy, David A. Patterson. Computer Architecture: Quantitative Research Methods (6th Edition). Jia Hongfeng, translated
Andrew W. Apple, with Jens Palsberg. Modern Compiler Implementation in C
http://www.cs.cmu.edu/afs/cs/academic/class/15745-s19/www/lectures/L20-Global-Scheduling.pdf
https://zhuanlan.zhihu.com/p/292539074
Click to follow and learn about Huawei Cloud’s fresh technologies for the first time~
#Compiler #Optimization丨Cache #Optimization #HUAWEI #CLOUD #Developer #Alliances #personal #space #News Fast Delivery