etcd is an important basic component in the cloud native architecture, and it is incubated and hosted by CNCF.ETCD is a distributed and consistent KV storage system for shared configuration and service discovery. It is an open source project initiated by CoreOS, and the license agreement is Apache.etcd is implemented based on the Go language and is mainly used in scenarios such as shared configuration, service discovery, cluster monitoring, leader election, and distributed locks. In microservices and Kubernetes clusters, it can not only be used as a service registration discovery, but also as a middleware for key-value storage.
When it comes to key-value storage systems, ZOOKEEPER is the most widely used in the field of big data, and ETCD can be regarded as a rising star. Compared with Zookeeper, ETCD has advantages in multiple dimensions such as project implementation, comprehensibility of consensus protocol, operation and maintenance, and security.
ETCD vs ZK
| | etcd | ZK |
| consensus agreement | Raft protocol | ZAB (Paxos-like protocol) |
| Operation and maintenance | Convenient operation and maintenance | Difficult to operate and maintain |
| Project activity | active | no etcd active |
| APIs | ETCD provides HTTP+JSON, gRPC interface, cross-platform and cross-language | ZK needs to use its client |
| access security | etcd supports HTTPS access | ZK does not support this in |
etcd is a distributed and reliable key-value storage system, which is used to store key data in distributed systems, and this definition is very important.
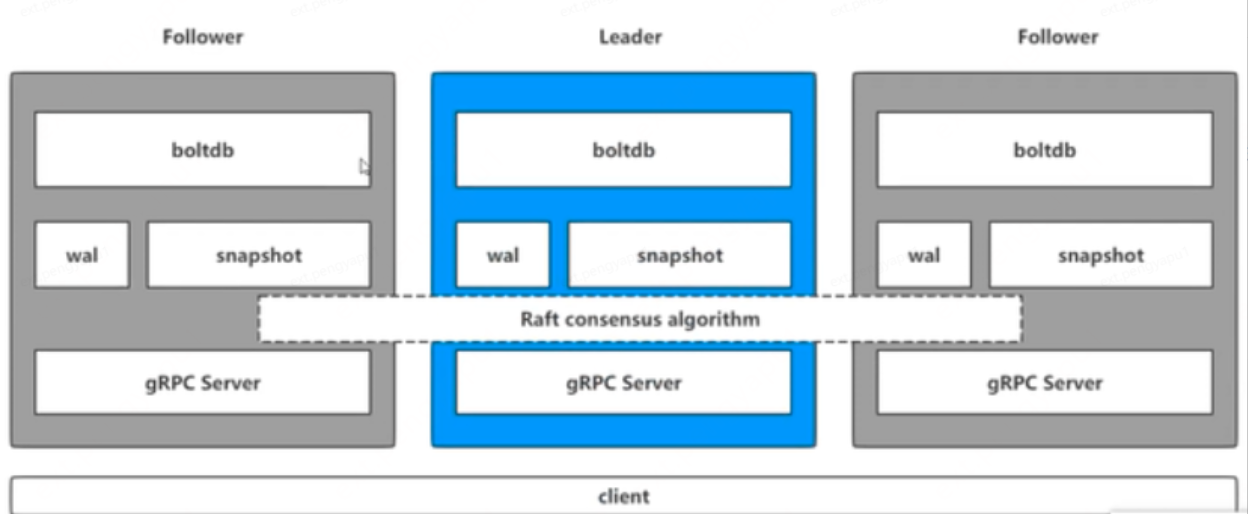
Through the following command, understand the execution process of etcd command, among which etcdctl: is a client, used to operate etcd.
etcdctl put key testUsually etcd provides services in the form of clusters. When etcdctl operates commands, it will correspond to the gRPC Server in the leader
gRPC Server
It is used to receive specific requests from clients for processing, but not only to handle client connections, it is also responsible for handling communication between nodes in the cluster.
wal: Write Ahead Log
How etcd stores data. In addition to storing the state of all data and the index of the node in memory, etcd uses WAL for persistent storage. In WAL, all data will be logged in advance before submission. A standard method for implementing transaction logs; write logs before performing write operations, similar to redo in mysql, wal implements sequential writing.
When the put operation is executed, the state of etcd data will be modified, and specific modification operations will be performed. wal is a log. When modifying the state of the database, the log will be modified first. The put key test will record the log in wal, and then broadcast it to other nodes in the cluster to set the key log. Other nodes will then return whether the leader agrees to the modification of the data. When the leader receives half of the requests, it will flush the value to the disk.
snapshot
The snapshot set by etcd to prevent too many WAL files is used to store all data of etcd at a certain time.Snapshot with WAL Combine,etcd Operations such as data storage and node failure recovery can be efficiently performed.
boltdb
Equivalent to the storage engine in mysql, each key in etcd will create an index, corresponding to a B+ tree.
•
Storage: Data is stored hierarchically in a file directory, similar to the file system we use every day;
•
Watch mechanism: watch the specified key, the change of the prefix directory, and notify the change time;
•
Secure communication: support SSL certificate verification;
•
High performance: a single instance of etcd can support 2K/s read operations, and the official benchmark test script is also provided;
•
Consistent and reliable: Based on the Raft consensus algorithm, the consistency and high availability of internal data storage and service calls in the distributed system are realized;
•
Revision mechanism: Each Key has a Revision number, which is incremented by one every time a transaction is performed, so it is globally unique. For example, the initial value is 0, and a Put operation is performed, and the Revision of the Key becomes 1. The same operation, and then Perform it once, Revision becomes 2; change to Key1 for Put operation, Revision will become 3. This mechanism has a function, that is, the order of write operations can be known through the size of Revision, which is very beneficial for realizing fair locks and queues;
•
Lease mechanism:Lease is a common concept in distributed systems, used to represent a distributed lease. Typically, when it is necessary to detect whether a node is alive in a distributed system, a lease mechanism is required.

First, a 10s lease is created. If no operation is performed after the lease is created, the lease will automatically expire after 10s. Then bind the two key values of key1 and key2 to the lease, so that etcd will automatically clean up key1 and key2 when the lease expires, so that the nodes key1 and key2 have the ability to automatically delete when timeout.
If you want the lease to never expire, you need to periodically call the KeeyAlive method to refresh the lease. For example, if you need to detect whether a process in a distributed system is alive, you can create a lease in the process and call the KeepAlive method periodically in the process. If everything is normal, the lease of the node will be maintained consistently. If the process hangs up, the lease will eventually expire automatically.
Similar to redis expire, redis expore key ttl, if the key expires, redis will delete the key when the expiration time is reached. Implementation of etcd: All keys with the same expiration time are bound to a global object to manage expiration. etcd only needs to detect the expiration of this object.By binding multiple keys to the same lease mode, we can aggregate keys with similar timeouts together, thereby greatly reducing the lease refresh overhead, and greatly increasing the usage scale supported by etcd without losing flexibility.
Service Registry Discovery
etcd is based on the Raft algorithm, which can effectively guarantee the consistency in distributed scenarios. Each service is registered to etcd when it starts, and the TTL time of the key is configured for these services at the same time. Each service instance registered on etcd periodically renews the lease through heartbeat to realize the status monitoring of the service instance.The service provider is in etcd The service is registered under the specified directory (supported by the prefix mechanism), and the service caller queries the service under the corresponding directory.pass watch Mechanism, the service caller can also monitor the changes of the service.

The engine service consists of two modules, one is the master service and the other is the scheduling service.
master service
After the master service starts successfully, register the service with etcd and send heartbeats to etcd regularly
server, err := NewServiceRegister(key, serviceAddress, 5)
if err != nil {
logging.WebLog.Error(err)
}Send heartbeat to etcd regularly
//设置续租 定期发送需求请求
leaseRespChan, err := s.cli.KeepAlive(context.Background(), resp.ID)Scheduling service
As a consumer of the service, the scheduling service listens to the service directory: key=/publictest/pipeline/
// 从etcd中订阅前缀为 "/pipeline/" 的服务
go etcdv3client.SubscribeService("/publictest/pipeline/", setting.Conf.EtcdConfig)Monitor put and delete operations, and maintain the serverslist locally. If there is a put or delete operation, the local serverslist will be updated
Client discovery means that the client directly connects to the registration center, obtains service information, implements load balancing by itself, and initiates a request using a load balancing strategy. The advantage is that you can customize the discovery strategy and load balancing strategy, but the disadvantage is also obvious. Each client needs to implement corresponding service discovery and load balancing.
watch mechanism
etcd canWatch Changes of the specified key, prefix directory, and notification of the change time. In the BASE engine, the cache clearing strategy is implemented with the help of etcd.
Cache expiration strategy: In the implementation of compilation acceleration, each item that needs to be cached has a corresponding cache key, monitor the key through etcd, and set the expiration time, for example, 7 days, if the key is hit again within 7 days, pass lease to renew the contract; if the key is not used within 7 days, the key will expire and be deleted. By monitoring the corresponding prefix, when the key is expired and deleted, the method of deleting the cache will be called.
storage.Watch("cache/",
func(id string) {
//do nothing
},
func(id string) {
CleanCache(id)
})In addition, the engine also uses the watch mechanism of etcd in the scene of pipeline cancellation and manual confirmation timeout to monitor the key of a certain prefix. If the key changes, it will perform corresponding logical processing.
Cluster monitoring andleader election mechanism
Cluster monitoring: Through the watch mechanism of etcd, when a key disappears or changes, the watcher will find out and notify the user immediately. The node can set a lease (TTL) for the key, such as sending a heartbeat renewal to etcd every 30 s, so that the key representing the node remains alive. Once the node fails, the renewal stops, and the corresponding key will be invalidated and deleted. In this way, the health status of each node can be detected at the first time through the watch mechanism to complete the monitoring requirements of the cluster.
Leader election: Using distributed locks, the leader election can be well realized (the one who successfully grabs the lock becomes the leader). The classic scenario of Leader application is to establish a full index in the search system. If each machine performs index building separately, it is not only time-consuming, but also cannot guarantee the consistency of the index. The leader is elected through the lock mechanism implemented in etcd, and the leader performs index calculation, and then distributes the calculation results to other nodes.
Similar to Kafka’s controller election, the engine’s scheduling service starts, and all services are registered under /leader of etcd. Among them, the first successfully registered node becomes the leader node, and other nodes automatically become followers.

The leader node is responsible for obtaining tasks from redis, and dispatching tasks to the corresponding go master service according to the load balancing algorithm.
The follow node monitors the status of the leader node. If the service of the leader node is unavailable and the corresponding node is deleted, the follow node will preempt again and become the new leader node.
At the same time, the leader ID set in etcd by the leader expires at 60s, and the leader updates every 30s. followEvery 30s, notify itself to etcd of its survival, and check the leader’s survival.
#Practice #Distributed #Registration #Service #Center #etcd #Cloud #Native #Engine #Cloud #Developers #Personal #Space #News Fast Delivery