
Author: Qiu Wei
Introduction
At present, the live broadcast industry is becoming more and more popular. Users are usually in different environments. Noises such as keyboard sounds, percussion sounds, air conditioner sounds, and loud noises sometimes cause serious interference to real-time interaction. However, the traditional noise reduction algorithm has a relatively good noise reduction effect for stationary noise, and it is difficult to deal with the above-mentioned non-stationary noise, with little effect, and the noise reduction effect is very poor.
With the wide application of deep learning in recent years, noise reduction algorithms using neural networks have spewed out, and such algorithms are superior to traditional noise reduction in terms of noise reduction strength and robustness. The preferred solution for different scene noises.
However, in a real-time interactive environment, the requirements for real-time audio processing and performance are relatively high, which brings huge challenges to the design of AI models and the balance of effects.
Based on the above challenges, the audio team of Lizhi Group proposed a lightweight noise reduction solution–LizhiAiDenoiser, which can not only deal with stationary and non-stationary noises common in daily life, but also preserve the sound quality of speech. The memory and CPU consumption occupied by the AI noise reduction model during operation are extremely low, which satisfies all iPhone models and most low-end Android models.
one,Fundamental
LizhiAiDenoiser adopts a hybrid structure combining traditional algorithms and deep learning. In order to actually deploy on the mobile terminal, LizhiAiDenoiser adopts a relatively fine model structure, mainly using the CNN-RNN structure with low performance consumption.
1. Data and Enhancements
The dataset for training the deep learning noise reduction model is by mixing clean speech and noisy audio. Pure Voice mainly uses open source datasets, including English datasets and Chinese datasets, with 300 hours of English datasets and 200 hours of Chinese datasets. The noise audio consists of two parts, one is the open source noise set audioset, which is about 120 hours, and the other is the noise set recorded by myself, which is about 60 hours. Data augmentation methods are applied to speech and noise samples to further expand the data distribution seen by the model during training. Currently, LizhiAiDenoiser supports the following random enhancement methods:
- Resampling speed and changing pitch
- Add reverb, add a small amount of reverb to the pure voice
- use[-5,25]signal-to-noise ratio to mix clean speech and noise
2. model target
Speech noise reduction usually adopts the short-time Fourier transform (STFT) of noisy speech, which only enhances the amplitude spectrum and keeps the phase spectrum unchanged. This is done because it is believed that the phase spectrum is not important for speech enhancement. However, recent studies have shown that phase is important for perceptual quality.Our method uses a deep neural network to estimate the real and imaginary components of the ideal ratio Mask in the complex domain, which better preserves the quality of speech
At the same time, the same noise reduction effect of the large model is achieved with smaller model parameters. The original AI noise reduction model, the model size is about 3M, and the fixed test set mos is divided into 3.1. Do some pruning to the model and adjust the model structure at the same time, and then adjust the output target of the model. In the case of maintaining the mos of 3.1, the final model size is reduced to 900k.
The derivation process of the complex ideal ratio Mask is as follows:
![]()
In formula (1)![]() represents pure voice,
represents pure voice,![]() represents noisy speech,
represents noisy speech,![]() represents the ideal ratio in the complex domain estimated by the model
represents the ideal ratio in the complex domain estimated by the model
For convenience, the above formula does not reflect the subscripts of time and frequency, but gives the definition of each TF unit. Equation (1) can be extended to:
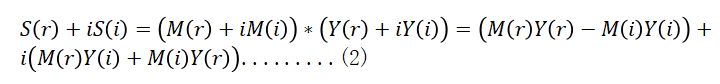
The real and imaginary components of pure speech are:
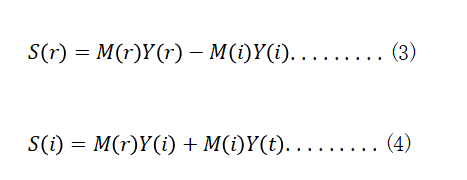
According to formula (3) and formula (4), the real and imaginary components of M can be obtained:
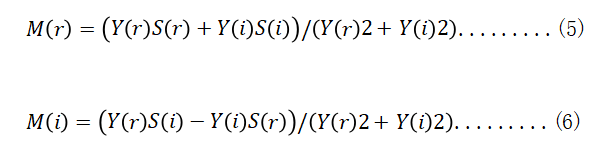
Thus, the Mask of the ideal ratio in the complex field is obtained:
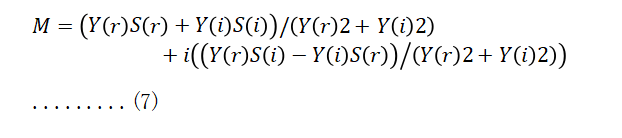
3. network model
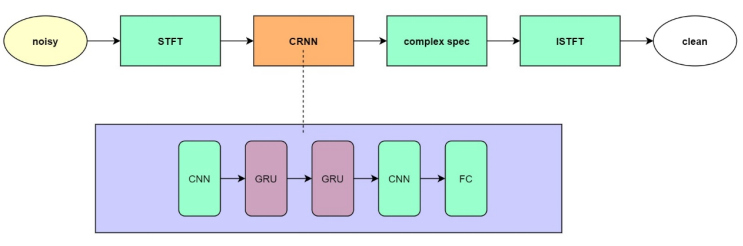
As can be seen from the above figure, the model structure we use is extremely simple, and CNN can extract local features very well, and GRU can learn time series features, which is very positive for model generalization and real-time reasoning. to the effect.
two,Effects and performance
Effect
In effect verification, we use eight common noises with different signal-to-noise ratios and traditional noise reduction for comparison test, and use POLQA to test the audio mos score after noise reduction. The comparison results are as follows:
0db | 10db | 25db | 40db | 50db | |
traditional noise reduction | 1.366 | 2.117 | 4.276 | 4.61 | 4.72 |
LizhiAiDenoiser | 1.959 | 2.744 | 4.446 | 4.74 | 4.75 |
As shown in the above results, LizhiAiDenoiser has achieved good results in different signal-to-noise ratios and scenarios.
The audio of 40db and 50db is tested here, mainly to test whether LizhiAiDenoiser has any damage to almost pure voice. From the final results, it can be seen that LizhiAiDenoiser has almost no damage to pure voice.
Example of sound quality protection
with noise frequency |
|
damaged |
|
LizhiAiDenoiser |
|
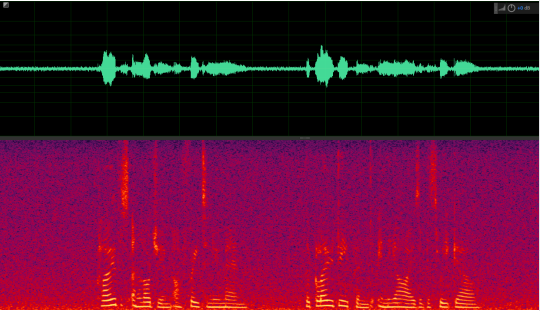
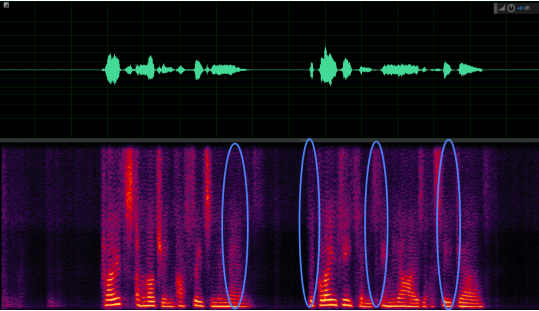
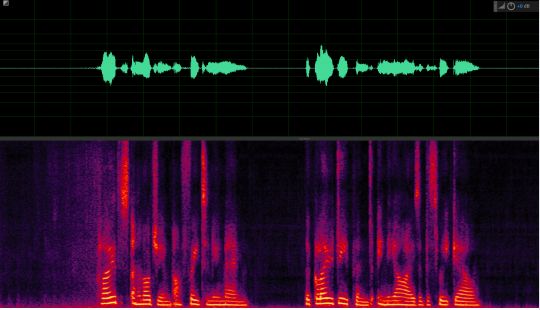
Conclusion: In the mid-frequency part of the voice, it can be seen that the LizhiAiDenoiser retains the voice better after noise reduction.
Noise reduction example
steady state noise | astable noise | |
with noise frequency |
|
|
traditional noise reduction |
|
|
LizhiAiDenoiser |
|
|






performance
In the forward inference process of LizhiDenoiser’s model, we did not use an open-source inference framework, but a self-developed inference framework. The reasons for not using an open-source inference framework are as follows:
- Does not rely on third-party reasoning framework, making forward reasoning more flexible;
- Reduce the package size of LizhiDenoiser module;
- More freedom and flexibility to optimize the ultimate inference speed for the model structure
We tested the performance of lower iPhone and Android models respectively. Here we mainly use cpu consumption and real-time rate to measure the performance of LizhiAiDenoiser.
cpu consumption
Because the model design is relatively fine, the parameter occupancy is relatively small, and the CPU occupancy does not exceed 3%.
real-time rate
The real-time rate refers to the time it takes to process each frame of audio. Usually, the entire audio is processed to count the total time-consuming, and then divided by the total number of audio frames to get the average time-consuming per frame. This method requires a relatively high real-time rate. It is difficult to be convincing in the task of , because the task is relatively simple at this time, and the CPU utilization rate is relatively high, so the total time-consuming statistics are greatly reduced.
We use the most realistic statistical method when calculating the real-time rate, that is, to count the real time-consuming situation of each frame of audio in the RTC application. The statistics are as follows:
Vivo X9 | iPhone7 |
|
|
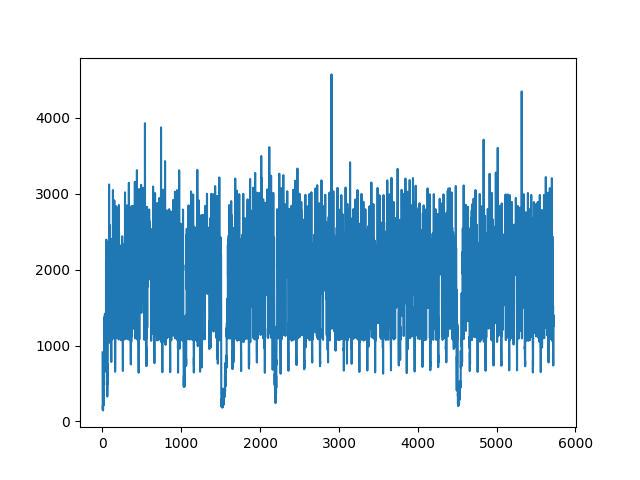
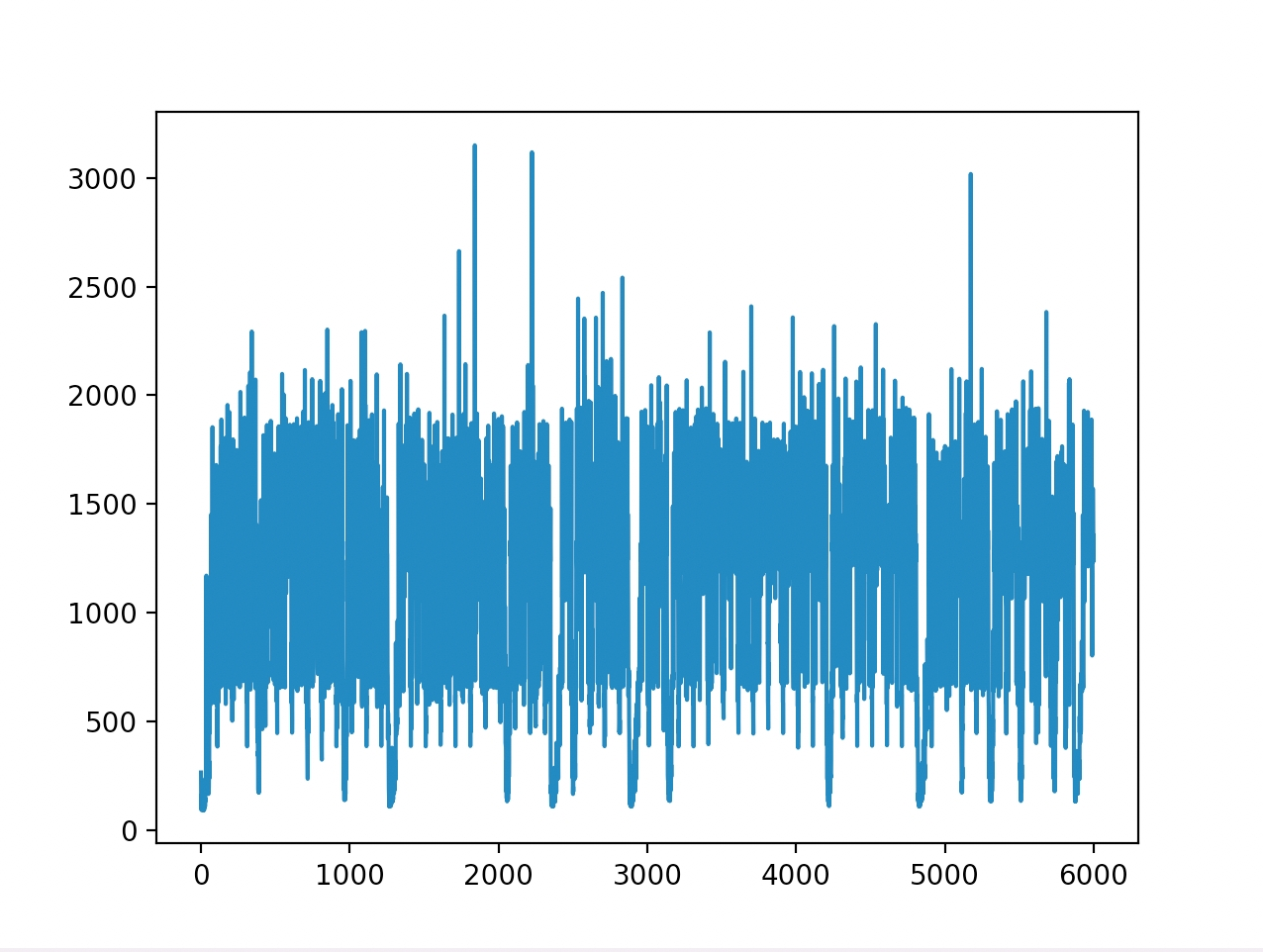
Description: The abscissa in the above figure is the number of audio frames, each frame is 10 milliseconds, and the ordinate is the time spent by LizhiAiDenoiser noise reduction for each frame, the unit is microseconds.
As can be seen from the figure, the real-time rate of lower android models does not exceed 0.3, and the real-time rate of lower iPhone models does not exceed 0.2.
three,planning
AI noise reduction still has a lot of room for optimization in RTC tasks:
- Real-time rate optimization
We will further prune the model and use a network with lower computational consumption. At the same time, we will further optimize our AI inference framework and quantify the model. Through the optimization of these dimensions, we will further improve the real-time rate of our AI noise reduction.
- Full-band AI noise reduction
Because the full-band AI noise reduction is relatively large in terms of feature input and network structure design, it is difficult to achieve good results in tasks such as RTC, which require relatively high real-time rates, so we are going to convert the audio to comparison. On a small feature dimension, the task is fitted by designing a relatively small network.
- Compression of the model
In the implementation of the algorithm, there are sometimes certain requirements for the size of the model, and it is also a reflection of the light weight of the model, which occupies less equipment resources. Therefore, when the model is implemented, the size of the model is generally compressed. Next, we will use data types that occupy less memory to store data, and optimize the format of model storage to further reduce the size of model storage.
author:
Qiu Wei: Senior Audio Algorithm Engineer of Lizhi Audio and Video R&D Center, mainly engaged in the research of audio-related AI algorithms and the deployment of AI models on mobile terminals.
#Practice #research #noise #reduction #technology #high #fidelity #lychee #sound #quality
Practice and research on noise reduction technology with high fidelity of lychee sound quality