Gobrs-Async It is a high-performance asynchronous orchestration framework with powerful functions, flexible configuration, full-link exception callback, memory optimization, and exception state management. Provide enterprises with the ability to dynamically schedule tasks in complex application scenarios. For complex scenarios, the complexity of asynchronous threads, task dependencies, and abnormal states are difficult to control; Gobrs-Async Born for this.
resource index
what can be solved
can solve CompletableFuture problems that cannot be solved. How to understand it?
traditionalFuture,CompleteableFutureTo a certain extent, task scheduling can be completed, and the results can be passed to the next task. For example, CompletableFuture has a then method, but it cannot call back each execution unit. For example, if A is executed successfully, followed by B. I hope that A will have a callback result after execution, so that I can monitor the current execution status, or make a log or something. If it fails, I can also log an exception message or something.
At this point, CompleteableFuture is powerless.
Gobrs-AsyncThe framework provides such a callback function. Moreover, if the execution succeeds, fails, exceptions, timeouts and other scenarios, it provides the ability to manage thread tasks!
Scenario overview
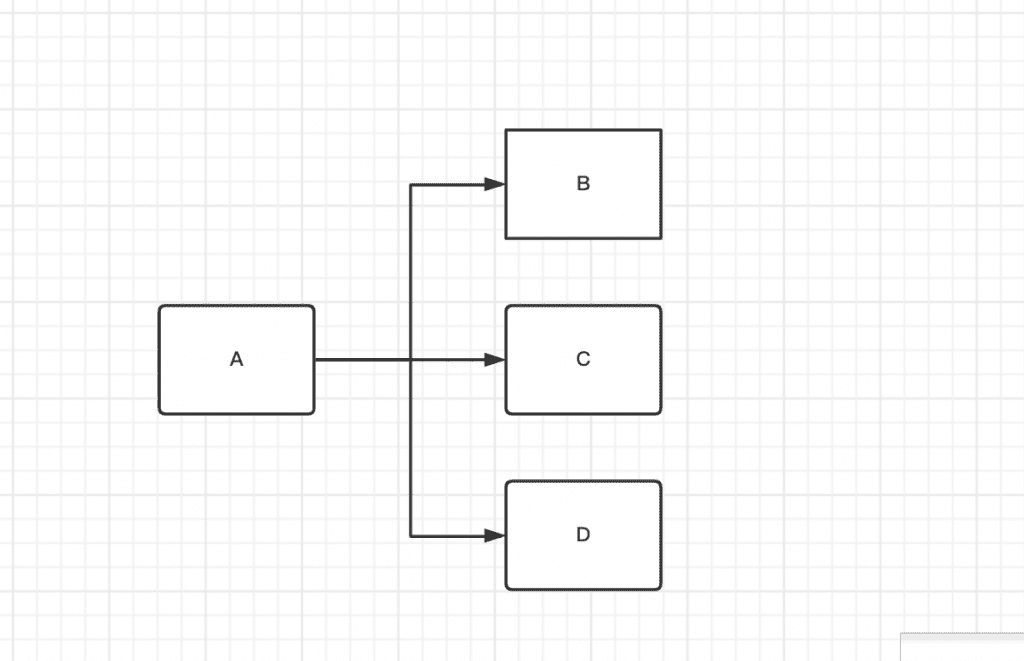
scene one
scene one
illustrate After task A is completed, continue to execute B, C, D
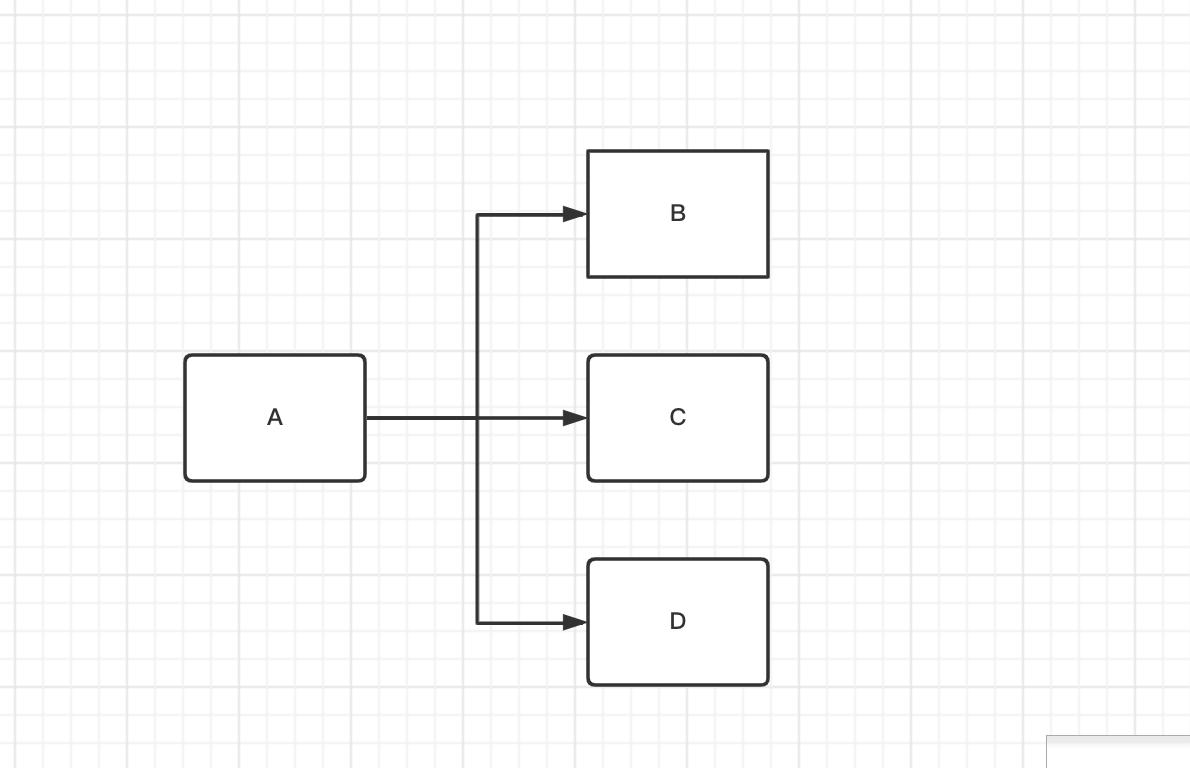
scene two
scene two
illustrate After task A is executed, execute B, then execute C, D
scene three
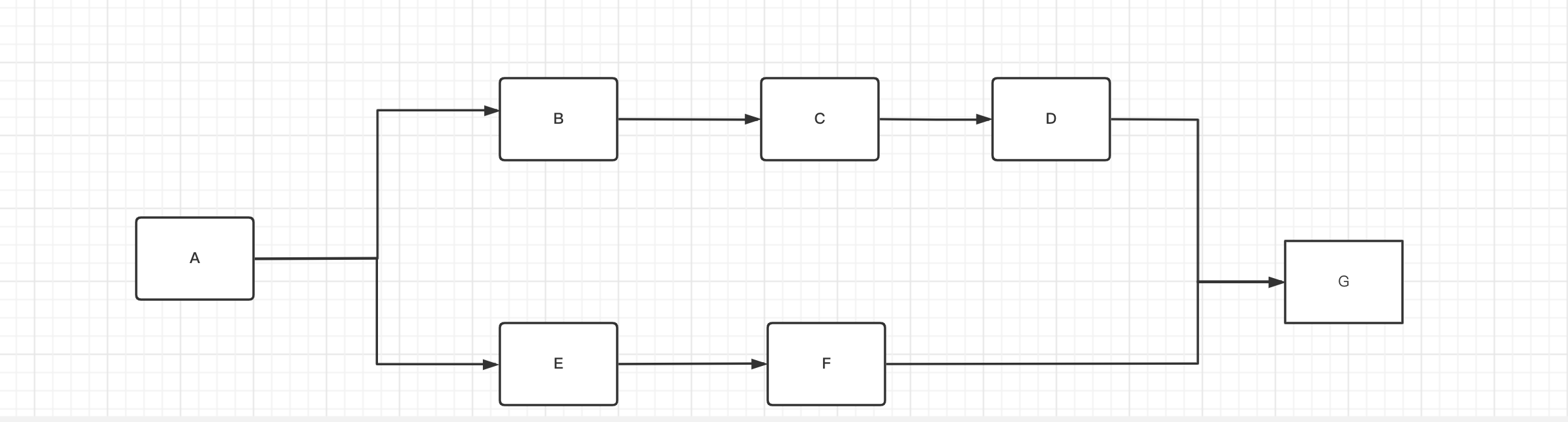
scene two
illustrate After task A is executed, execute B, E, and then go to C, D, and G according to the process of sequence B. The process of E goes to F, G
There are more scenarios. If you want to understand the concept of task scheduling in detail, please read the documentation carefully, or navigate to the official website through the resource index to get the full picture!
why write this project
In the process of developing a complex middle-end business, it is inevitable that various middle-end business data will be called, and complex middle-end data dependencies will appear. In this case. The complexity of the code will increase. As shown below: 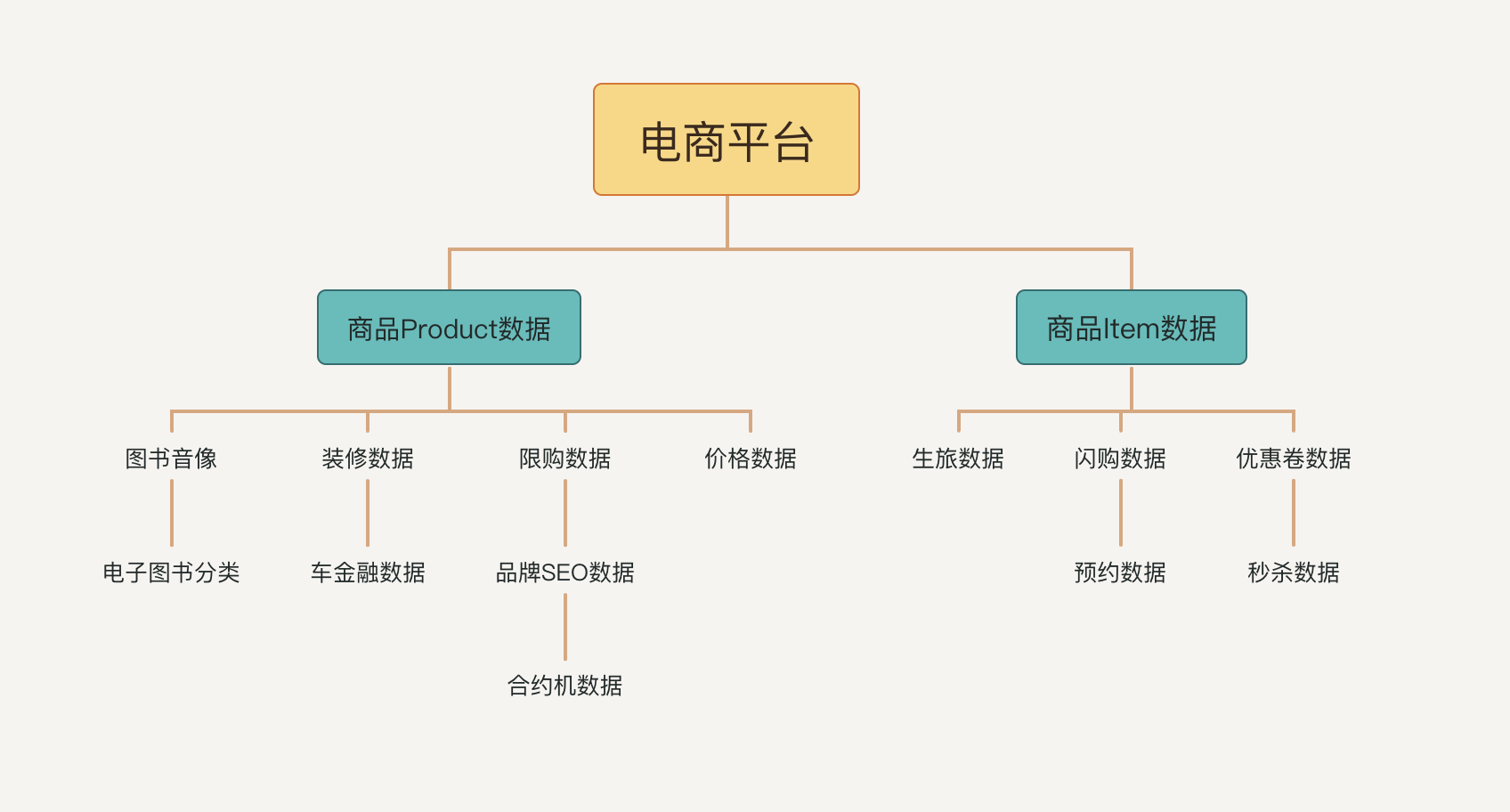
In the e-commerce platform business, the data of each middle station may depend on the product data, and need to depend on the Item data in the special attribute. (Some friends will ask, why doesn’t Product data and Item data come from the same middle office? Middle office business development is diverse, and different business middle office design methods are different, don’t we connect? So we have to target at It is what a qualified developer should do to provide technical support for such complex and changeable middle-office business data) and Item data is an HTTP service, but Product is an RPC service. If you follow the way Future is developed.We might develop like this
// 并行处理任务 Product 、 Item 的任务
@Resource
List<ParaExector> paraExectors;
// 依赖于Product 和 Item的 任务
@Resource
List<SerExector> serExectors;
public void testFuture(HttpServletRequest httpServletRequest) {
DataContext dataContext = new DataContext();
dataContext.setHttpServletRequest(httpServletRequest);
List<Future> list = new ArrayList<>();
for (AsyncTask asyncTask : paraExectors) {
Future<?> submit = gobrsThreadPoolExecutor.submit(() -> {
asyncTask.task(dataContext, null);
});
list.add(submit);
}
for (Future future : list) {
try {
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
List<Future> ser = new ArrayList<>();
for (AsyncTask asyncTask : serExectors) {
Future<?> submit = gobrsThreadPoolExecutor.submit(() -> {
asyncTask.task(dataContext, null);
});
ser.add(submit);
}
for (Future future : ser) {
try {
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
existing problems
In the above example, Product data is obtained through RPC, and Item is obtained through HTTP service. As we all know, RPC performance is higher than HTTP performance. However, through the Future method, get will block and wait for the Item data to return before proceeding. In this case, book audio and video, decoration data, purchase restriction data, etc. must wait for Item data to be returned, but these middle stations do not rely on the data returned by Item, so the waiting time will affect the overall QPS of the system.
origin
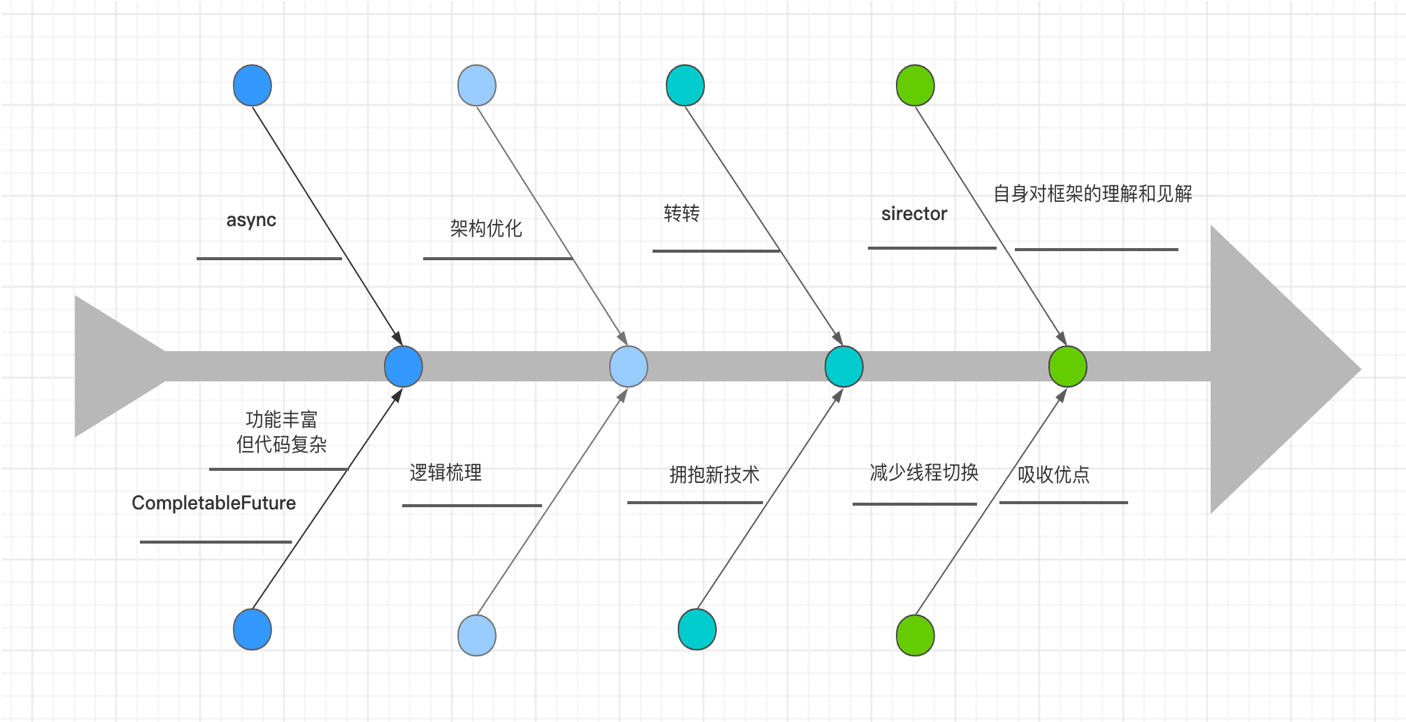
origin
-
The author summarizes the experience and use experience of reading the source code of open source middleware in detail and secondary development.
-
Some user experiences include business needs
Gobrs-Async Core Capabilities
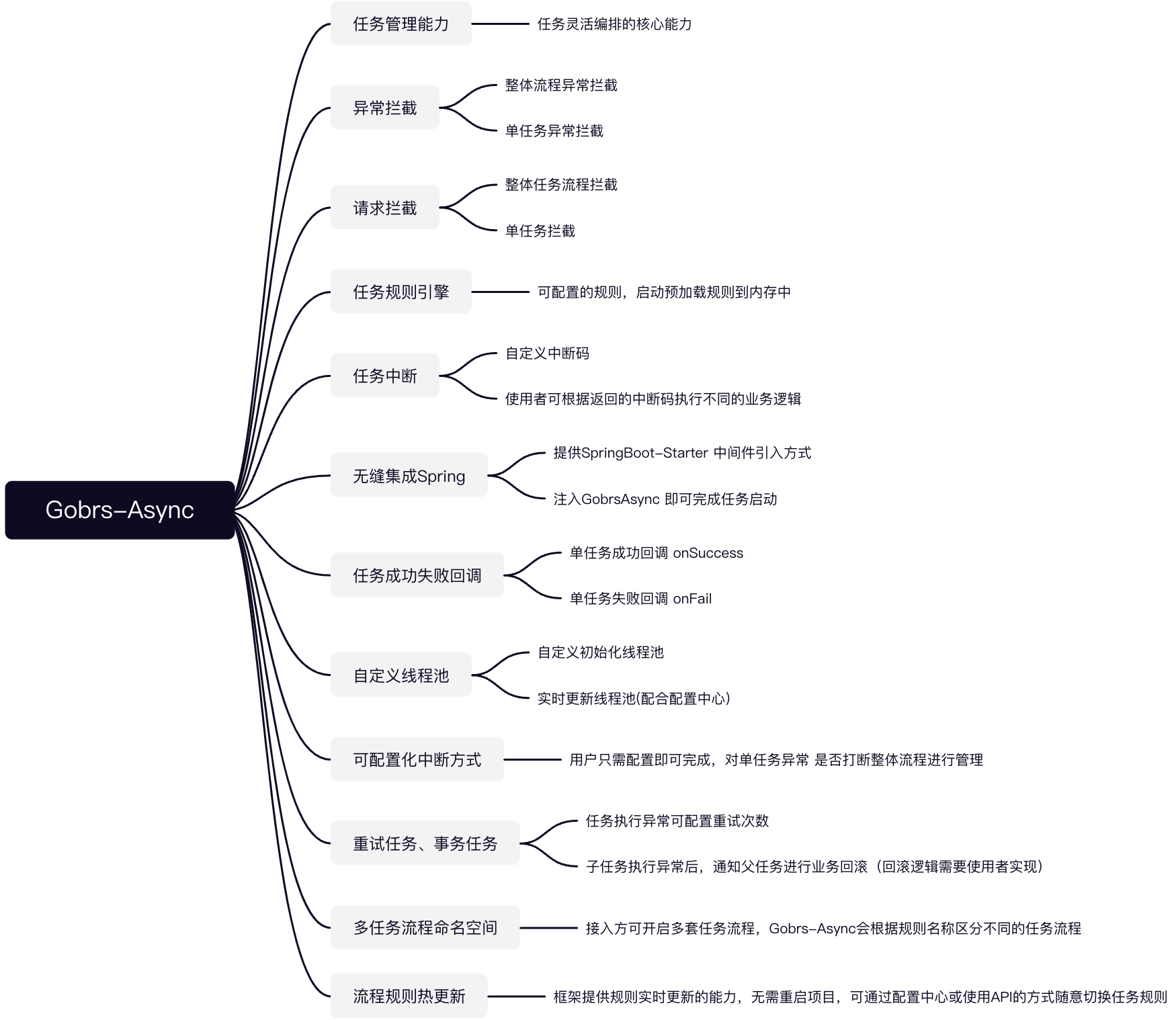
core competence
Industry comparison
I found a lot of multi-task asynchronous orchestration frameworks on the open source platform, and found that they are not very ideal. The only asynchronous orchestration framework that is easier to use at this stage is asyncTool. However, when using it, I found that the API is not very useful.and requires frequent creation WorkerWrapper Objects are a little uncomfortable to use.For more complex business scenarios, you need to write more during development. WorkerWrapper code, and the framework cannot intercept global exceptions.only by task result method to catch exceptions for a single task. A global asynchronous task cannot be stopped after an exception occurs in any task. At the same time, exception interception cannot be performed when a global exception occurs. If you need to implement the function of sending an alarm email when the global task flow needs to be stopped. asyncTool seems powerless.
asyncTool itself is already very powerful, and both myself and the author of asyncTool are working on JD.com for research and development. The scenarios involved are much the same. There will be many business scenarios and complex middle-end interface calling relationships. So for the current business scenario. More technical areas need to be explored. The technology itself should serve the business and implement the business scenario.
I want to give the project a simple and easy-to-remember name, similar to Eureka, Nacos, Redis; after much consideration, I decided to name it:Gobrs-Async
| Function | asyncTool | Gobrs-Async | sirector |
|---|---|---|---|
| multitasking | Yes | Yes | Yes |
| Single task exception callback | Yes | Yes | no |
| global abort | no | Yes | no |
| Configurable task flow | no | Yes | no |
| Custom exception interceptor | no | Yes | no |
| memory optimization | no | Yes | no |
| optional task execution | no | Yes | no |
what problem does it solve
When requesting to call the data of major middle stations, it is inevitable that multiple middle station data will depend on each other. In actual development, the following scenarios will be encountered.
Parallel common scenario 1 The client requests the server interface, which needs to call the interfaces of other N microservices
For example, to request my shopping cart, you need to call the user’s rpc, the rpc of the product details, the inventory rpc, the coupons, and many other services. At the same time, these services are also interdependent. For example, you must first obtain the product id before going to the inventory rpc service to request inventory information. After the final acquisition is completed, or the timeout expires, the results are aggregated and returned to the client.
2 Execute N tasks in parallel, and then decide whether to continue to execute the next task according to the execution results of these 1-N tasks
For example, if a user can log in through email, mobile phone number, and username, and there is only one login interface, then when the user initiates a login request, we need to simultaneously check the database according to the mailbox, mobile phone number, and username. As long as one succeeds, it counts. If successful, you can proceed to the next step. Instead of trying to see if the email is successful, then try the phone number…
Another example is that an interface limits the amount of parameters passed in each batch, and the information of 10 products is queried at most each time. If I have 45 products to be queried, I can divide them into 5 piles and query them in parallel. The follow-up is to count the queries of these 5 piles. result.It depends on whether you force all the checks to be successful, or return to the client no matter how many checks are successful.
Another example is an interface, there are 5 pre-tasks that need to be processed. 3 of them must be executed before the subsequent ones can be executed, and the other 2 are non-mandatory. As long as these 3 executions are completed, the next step can be performed. At that time, the other 2 will have value if they are successful, and if they have not been executed. , which is the default value.
3 Multi-batch tasks that require thread isolation.
For example, if there are multiple groups of tasks, each group of tasks is not related to each other, each group needs an independent thread pool, and each group is a combination of an independent set of execution units. A bit similar to hystrix’s thread pool isolation strategy.
4 Single-machine workflow task scheduling.
5 Other requirements for sequential arrangement.
what features does it have
Gobrs-Async has taken into account the development preferences of many users and the usage scenarios of exception handling during development. And it has been applied to the e-commerce production environment, and experienced this severe high concurrency test on JD.com. At the same time, the framework’s minimal and flexible configuration, global customization can interrupt the whole process exception, memory optimization, flexible access methods, and SpringBoot Start access methods. More consideration is given to the user’s development habits. Only need to inject Spring Bean of GobrsTask to achieve full process access.
Gobrs-Async project directory and its streamlining
When Gobrs-Async was designed, it fully considered the usage habits of developers and did not rely on any middleware. The concurrency framework is well encapsulated.Mainly used CountDownLatch ,ReentrantLock ,volatile And a series of concurrent technology development and design.
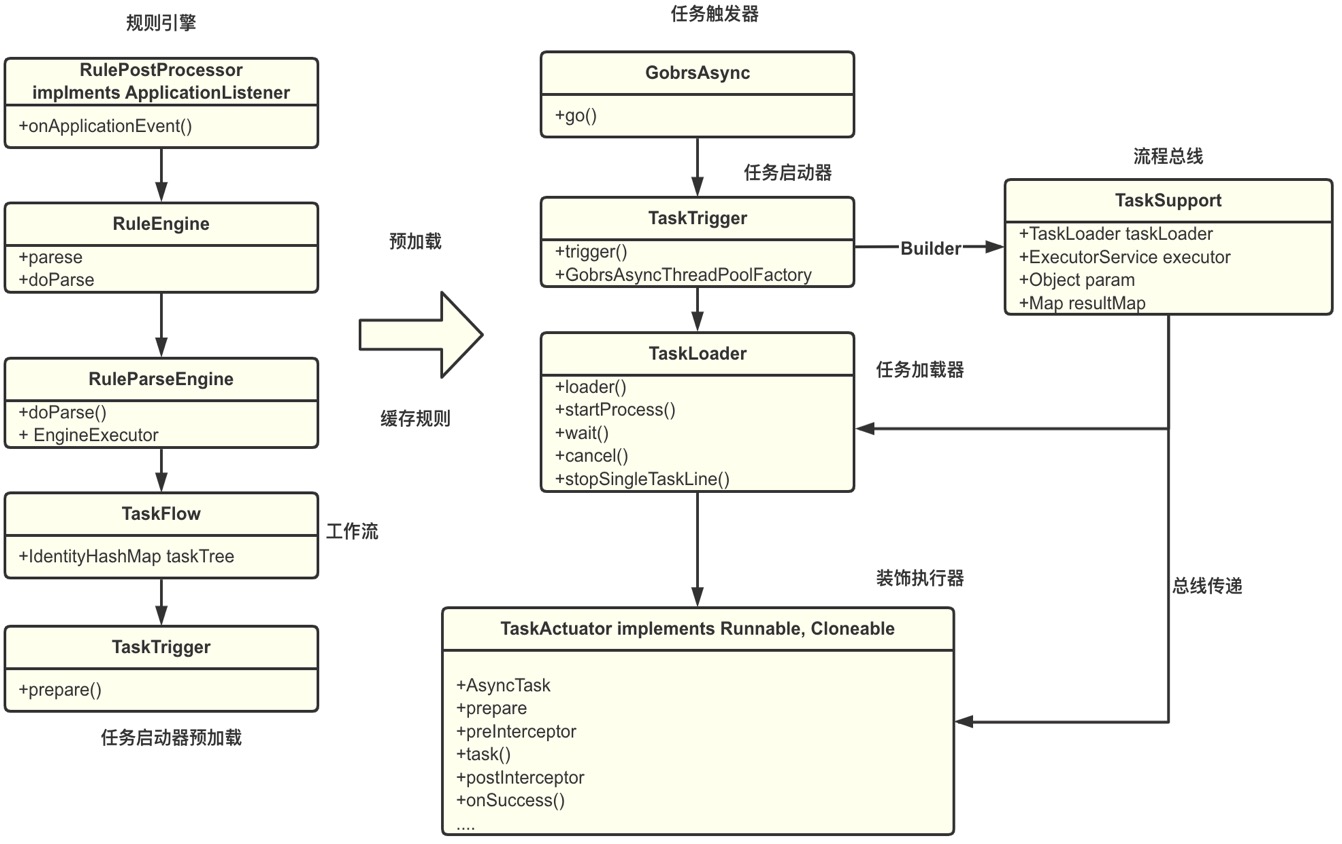
Overall structure
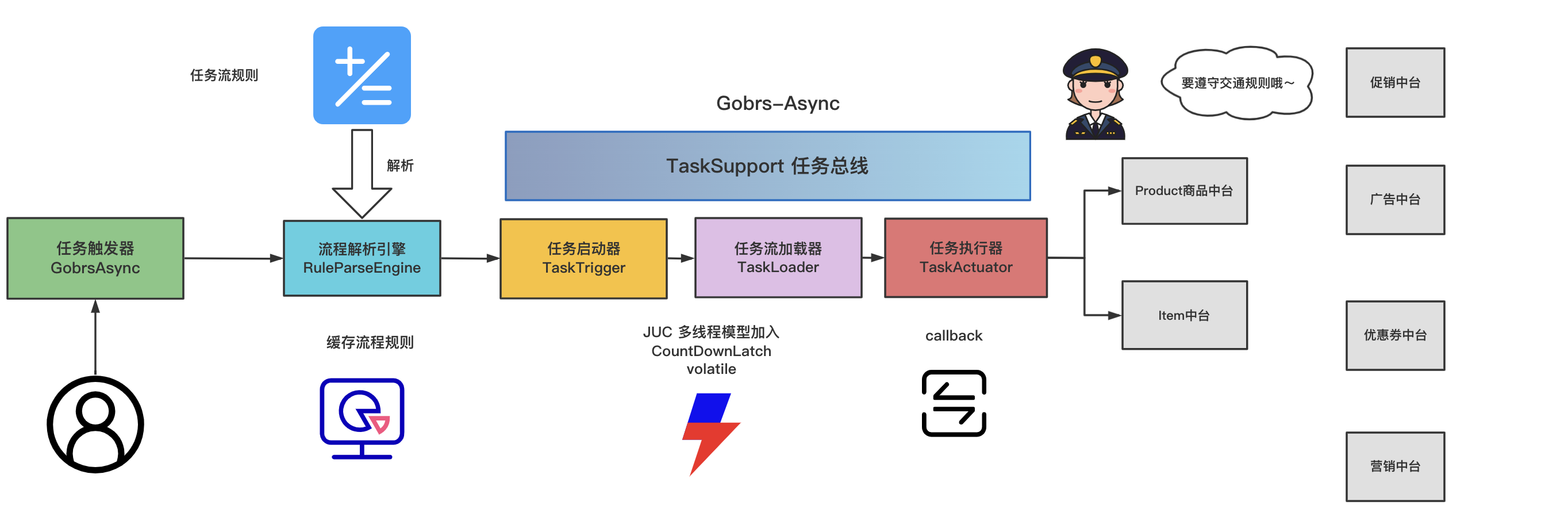
1.0
task trigger
The initiator of the task flow, responsible for starting the task execution flow
Rules parsing engine
It is responsible for parsing the rules configured by the user, and at the same time combining with Spring, the configured Spring Bean parsed into TaskBean, which is then loaded into a task decorator through the parsing engine.And then assembled into a task tree
task launcher
Responsible for the task tree parsed by using the parsing engine.combine JUC Concurrent framework scheduling implements unified management of tasks. The core methods are:
task loader
Responsible for loading the task process and start calling the task executor to execute the core process
-
The load core task process method, which blocks and waits for the entire task process here
-
getBeginProcess gets the subtask start process
-
completed task completed
-
errorInterrupted Task failure interrupts the task flow
-
error task failed
task executor
The final task execution, each task corresponds to aTaskActuator The necessary condition judgments such as task interception, exception, execution, and thread reuse are all handled here
-
prepare task preprocessing
-
preInterceptor unified task preprocessing
-
task core task method, business execution content
-
postInterceptor unified post-processing
-
onSuccess task execution success callback
-
onFail task execution failure callback
task bus
The task process transfer bus, including request parameters, task loader, and response results, the object is exposed to the user to get the data information matching the business, such as: returning results, actively interrupting the task process and other functions require the task bus (TaskSupport)support
Core class diagram
#GobrsAsync #Homepage #Documentation #Downloads #High #Performance #Asynchronous #Orchestration #Framework #News Fast Delivery