foreword
Some time ago I stepped on a pit: inmysql8one ofinnodbengine表in, added唯一索引but finally found数据still重复.
What really happened?
This article talks about the unique index and some interesting knowledge points through a stepping experience.

1. Restore the problem scene
Some time ago, in order to prevent duplicate data from product groups, I added a special防重表.
If you are interested in the anti-heavy watch, you can read my other article “How to prevent weight under high concurrency?which has a detailed introduction.
The problem lies in the anti-weight table of the commodity group.
The specific table structure is as follows:
CREATE TABLE `product_group_unique` (
`id` bigint NOT NULL,
`category_id` bigint NOT NULL,
`unit_id` bigint NOT NULL,
`model_hash` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`in_date` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
In order to ensure the data唯一性I built a unique index for the anti-duplication table for that commodity group:
alter table product_group_unique add unique index
ux_category_unit_model(category_id,unit_id,model_hash);
A commodity group can be uniquely determined according to the hash value of the classification number, unit number, and commodity group attributes.
Created an anti-weight table for the product group唯一索引After that, I checked the data the next day and found that there were duplicate data in the table:  The second and third data in the table are repeated.
The second and third data in the table are repeated.
Why is this?
2. Unique index field contains null
If you look closely at the data in the table, you will find one of the special places: the hash value of the item group attribute (model_hash field) may benullthat is, the product group allows no attribute to be configured.
A duplicate data with a model_hash field equal to 100 is inserted into the product_group_unique table:  Results of the:
Results of the: 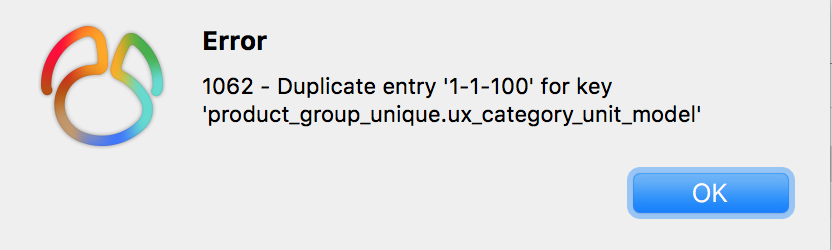 As can be seen from the above figure, the uniqueness constraint of mysql takes effect, and the duplicate data is intercepted.
As can be seen from the above figure, the uniqueness constraint of mysql takes effect, and the duplicate data is intercepted.
Next, we insert two pieces of data whose model_hash is null. The third piece of data is the same as the category_id, unit_id, and model_hash fields in the second piece of data. As can be seen from the figure, the execution was successful.
In other words, if there is a null value in the field of the unique index, the unique constraint will not take effect.
The final inserted data is as follows:
- When the model_hash field is not empty, no duplicate data will be generated.
- When the model_hash field is empty, duplicate data is generated.
We need to pay special attention: the fields that create a unique index cannot be allowed to be null, otherwise the unique constraint of mysql may be invalid.
3. Tombstone table plus unique index
We all know that the unique index is very simple and easy to use, but sometimes, it is not easy to add in a table.
If you don’t believe me, let’s look down.
Under normal circumstances, to delete a record in the table, if you usedeletestatement operation.
E.g:
delete from product where id=123;
This delete operation is物理删除, that is, after the record is deleted, the subsequent sql statement cannot be found. (However, it can be retrieved through other technical means, that is another story)
There is another逻辑删除mainly throughupdatestatement operates.
E.g:
update product set delete_status=1,edit_time=now(3)
where id=123;
Tombstone requires an additional deletion status field to be added to the table to record whether the data is deleted. In all business query places, it is necessary to filter out deleted data.
After deleting data in this way, the data is still in the table, but the data in the deleted state is logically filtered.
In fact, there is no way to add a unique index to this logically deleted table.
why?
Assuming that the previously given in the commodity tablenameandmodelWith a unique index, if the user deletes a record, delete_status is set to 1. Later, the user found that it was wrong and added the exact same product again.
Due to the existence of the unique index, the user will fail to add a product for the second time, even if the product has been deleted, it cannot be added again.
This problem is obviously a bit serious.
Some might say: putname,modelanddelete_statusThree fields are made at the same time唯一索引Wouldn’t it work?
A: This can indeed solve the problem that the user cannot add a product after logically deleting a product and then adding the same product again. But if the product added for the second time is deleted again. The user added the same product for the third time, didn’t the problem also occur?
It can be seen that if there is a tombstone function in the table, it is inconvenient to create a unique index.
But what if you really want to add a unique index to a table containing tombstones?
3.1 Delete status +1
As we know earlier, if there is a logical delete function in the table, it is inconvenient to create a unique index.
The root cause is that after the record is deleted, delete_status will be set to 1, and the default is 0. When the same record is deleted for the second time, delete_status is set to 1, but due to the creation of a unique index (the three fields of name, model and delete_status are simultaneously made into a unique index), a record with delete_status of 1 already exists in the database, so The operation will fail this time.
Why don’t we think differently: don’t worry about delete_status being 1, which means deletion, when delete_status is 1, 2, 3, etc., as long as it is greater than 1, it means deletion.
In this case, each delete gets the maximum delete status of that same record, and then increments it by 1.
This data manipulation process becomes:
- Add record a, delete_status=0.
- Delete record a, delete_status=1.
- Add record a, delete_status=0.
- Delete record a, delete_status=2.
- Add record a, delete_status=0.
- Delete record a, delete_status=3.
Since record a, delete_status is different each time it is deleted, so uniqueness can be guaranteed.
The advantage of this scheme is that it is very simple and straightforward without adjusting the fields.
The disadvantage is: you may need to modify the SQL logic, especially some query SQL statements, and some use delete_status=1 to judge the deletion status, you need to change it to delete_status>=1.
3.2 Add timestamp field
The most fundamental place that leads to the logical deletion of the table, it is not easy to add a unique index is the logical deletion.
Why don’t we add a field to deal with the tombstone function?
Answer: can increase时间戳field.
Make the four fields of name, model, delete_status and timeStamp a unique index at the same time
When adding data, the timeStamp field writes a default value1.
Then once there is a tombstone operation, a timestamp is automatically written to this field.
In this way, even if the same record is logically deleted multiple times, the timestamps generated each time are different, and the uniqueness of the data can be guaranteed.
Timestamps are generally accurate to秒.
Unless in that extreme concurrency scenario, two different logical delete operations for the same record produce the same timestamp.
At this time, the timestamp can be accurate to毫秒.
The advantage of this scheme is that the uniqueness of data can be realized by adding new fields without changing the existing code logic.
The disadvantage is: in extreme cases, duplicate data may still be generated.
3.3 Add id field
In fact, adding the timestamp field can basically solve the problem. But in extreme cases, duplicate data may still be generated.
Is there a way to solve this problem?
Answer: increase主键Field: delete_id.
The idea of this solution is the same as adding the timestamp field, that is, when adding data, set the default value of 1 to delete_id, and then assign delete_id to the primary key id of the current record when tombstone is deleted.
Make the four fields of name, model, delete_status and delete_id a unique index at the same time.
This may be the optimal solution, without modifying the existing deletion logic and ensuring the uniqueness of the data.
4. How to add unique index to repeated historical data?
As mentioned earlier, if there is a logical delete function in the table, it is not easy to add a unique index, but through the three schemes introduced in the article, a unique index can be added smoothly.
But a question from the soul: If a certain table already exists历史重复数据how to add index?
The easiest way is to add a防重表and then initialize the data into it.
You can write an sql like this:
insert into product_unqiue(id,name,category_id,unit_id,model)
select max(id), select name,category_id,unit_id,model from product
group by name,category_id,unit_id,model;
It is possible to do this, but today’s topic is to add a unique index directly to the original table, without the need for an anti-duplication table.
So, how to add this unique index?
In fact, we can learn from the previous section, addingidField ideas.
Add a delete_id field.
However, before creating a unique index for the product table, data processing must be done first.
Get the maximum id of the same record:
select max(id), select name,category_id,unit_id,model from product
group by name,category_id,unit_id,model;
Then set the delete_id field to 1.
Then set the delete_id field of other identical records to the current primary key.
In this way, historical duplicate data can be distinguished.
When all delete_id fields are set with values, unique indexes can be added to the four fields of name, model, delete_status and delete_id.
Perfect.
5. Add unique indexes to large fields
Next, let’s talk about an interesting topic: how to add a unique index to a large field.
Sometimes, we need to add a unique index to several fields at the same time, such as name, model, delete_status and delete_id.
However, if the model field is large, this will lead to the unique index, which may take up more storage space.
We all know unique indexes, and we will also go for indexes.
If large data is stored in each node of the index, the retrieval efficiency will be very low.
Therefore, it is necessary to limit the length of the unique index.
Currently, the maximum allowed length of an index in the mysql innodb storage engine is 3072 bytes, of which the maximum length of the unqiue key is 1000 bytes.
If the field is too large, exceeding 1000 bytes, it is obviously impossible to add a unique index.
At this point, is there a solution?
5.1 Add hash field
We can add a hash field, take the hash value of the large field, and generate a shorter new value. The value can be generated by some hash algorithm, fixed length 16-bit or 32-bit, etc.
We only need to add a unique index to the name, hash, delete_status and delete_id fields.
This avoids the problem of the unique index being too long.
But it also brings up a new problem:
The general hash algorithm will produce a hash conflict, that is, two different values, the same value generated by the hash algorithm.
Of course, if there are other fields that can be distinguished, such as name, and the business allows such duplicate data without writing to the database, this solution is also feasible.
5.2 Without a unique index
If it is really difficult to add a unique index, do not add a unique index, and use other technical means to ensure uniqueness.
If the new data entry is relatively small, such as only job, or data import, it can be executed sequentially in a single thread, so as to ensure that the data in the table is not repeated.
If there are many new data entries, the mq message will eventually be sent and processed in a single thread in the mq consumer.
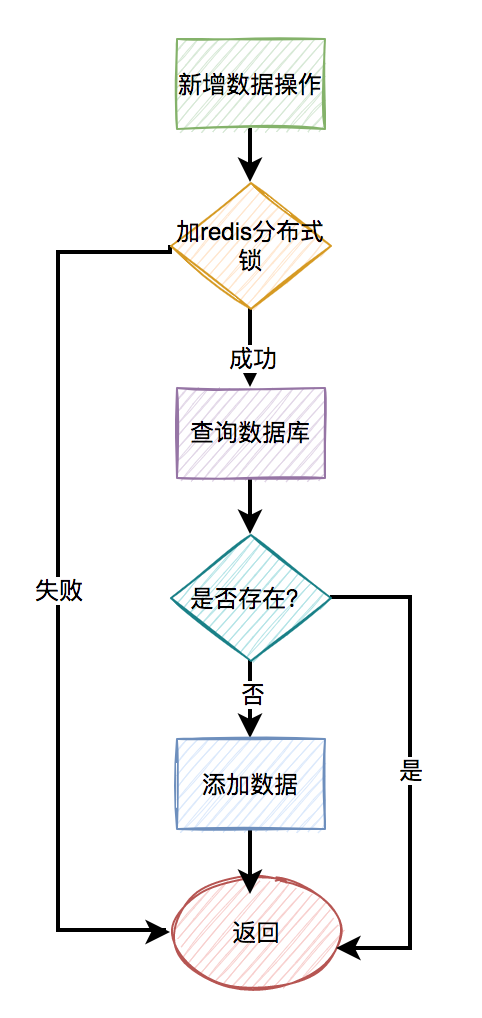
5.3 Redis distributed lock
Because the field is too large, it is not easy to add a unique index in mysql, why not use it?redis分布式锁Woolen cloth?
But if you add it directly to the name, model, delete_status and delete_id fields, addredis分布式锁obviously meaningless, and the efficiency will not be high.
We can combine the 5.1 section, use the name, model, delete_status and delete_id fields to generate a hash value, and then lock the new value.
It does not matter even if you encounter a hash conflict, in the case of concurrency, it is a small probability event after all.
6. Batch insert data
Some guys may think that since there is a redis distributed lock, it is not necessary to use a unique index.
That’s the scenario you haven’t encountered, inserting data in batches.
If after the query operation, it is found that there is a collection: list data, which needs to be inserted into the database in batches.
If you use redis distributed lock, you need to do this:
for(Product product: list) {
try {
String hash = hash(product);
rLock.lock(hash);
//查询数据
//插入数据
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}
}
Need to lock each piece of data in a loop.
This performance will definitely not be good.
Of course, some friends have objections, saying that the use of redispipelineIs it possible to do batch operations?
That is, lock 500 or 1000 pieces of data at one time, and release these locks at one time after use?
It’s a bit unreliable to think about, how big this lock is.
It is very easy to cause lock timeout. For example, if the business code has not been executed, the lock expiration time has come.
For this kind of batch operation, if you use the unique index of mysql at this time, you can directly insert in batches, and a single SQL statement can be done.
The database will automatically judge, and if there is duplicate data, an error will be reported. Inserting data is only allowed if there is no duplicate data.
One last word (please pay attention, don’t prostitute me for nothing)
If this article is helpful or enlightening to you, please scan the QR code and pay attention. Your support is the biggest motivation for me to keep on writing. Ask for one-click three links: like, forward, and watch. Follow the official account:[Su San said technology]reply in the official account: interview, code artifact, development manual, time management have great fan benefits, and reply: join the group, you can communicate and learn with the seniors of many BAT manufacturers .
#obvious #unique #index #added #duplicate #data #San #personal #space #technology #News Fast Delivery
It is obvious that a unique index is added, why is there still duplicate data? – Su San said the personal space of technology- News Fast Delivery