Guide: For a long time, Apache Doris has been widely used in Xiaomi Group. With the rapid development of Xiaomi’s Internet business, users have put forward higher requirements for the query performance of Apache Doris, and it is imminent to launch the vectorized version of Doris inside Xiaomi. With the full support of SelectDB and the Apache Doris community, we have performed a series of tuning operations on the Doris 1.1.2 vectorized version in the Xiaomi A/B experimental scenario, which has significantly improved query performance and stability.
Author|Wei Zuo, Zhao Liwei
background
In September 2019, in order to meet the needs of near real-time and multi-dimensional analysis and query in Xiaomi’s Internet growth analysis business, Xiaomi Group introduced Apache Doris for the first time.In the past three years, Apache Doris has been widely used within Xiaomi, supporting group data dashboards, advertising placement, advertising BI, new retail, user behavior analysis, A/B experimental platform, Tianxing Digital Technology, Xiaomi There are dozens of internal Xiaomi businesses such as Youpin, user portraits, and Xiaomi car manufacturing, and a set of data ecology with Apache Doris as the core has been formed within Xiaomi. . As one of the earliest users of Apache Doris, Xiaomi Group has been deeply involved in community building and the stability of Apache Doris.
In order to ensure the stability of online services, Xiaomi internally iterates based on version 0.13 of the Apache Doris community to provide stable report analysis and BI Kanban services for Xiaomi’s business. After a long period of business polishing, the internal Doris version 0.13 is already very stable. However, with the development of Xiaomi’s Internet business, users have put forward higher requirements for the query performance of Doris, and Doris version 0.13 is gradually difficult to meet business needs in some scenarios. At the same time, the Apache Doris community is developing rapidly. Version 1.1 released by the community has fully supported vectorization in the computing layer and storage layer, and the query performance has been significantly improved compared with the non-vectorized version. Based on this, Xiaomi’s internal Apache It is imperative to upgrade the vectorized version of the Doris cluster.
scene introduction
Xiaomi’s A/B experimental platform has an urgent need to improve Doris query performance, so we choose to launch the vectorized version of Apache Doris on Xiaomi’s A/B experimental platform, that is, version 1.1.2.
Xiaomi’s A/B experimental platform is an operation tool product that passes A/B testing and uses methods such as experimental grouping, traffic splitting, and scientific evaluation to assist scientific business decisions and ultimately achieve business growth. In actual business, in order to verify the effect of a new strategy, it is usually necessary to prepare two schemes, the original strategy A and the new strategy B. Then take a small part of the overall users, and divide these users into two groups completely randomly, so that there is no statistical difference between the two groups of users. Show the original strategy A and the new strategy B to different user groups. After a period of time, analyze the data with statistical methods to obtain the results of the changes in the indicators after the two strategies take effect, and use this to judge whether the new strategy B meets expectations.
Figure 1 – Introduction to Xiaomi’s A/B experiment
Xiaomi’s A/B experiment platform has several typical query applications: user deduplication, indicator summation, experimental covariance calculation, etc. The query types will involve more Count (distinct), Bitmap calculation, Like statement, etc.
Verify before going live
Based on the Doris 1.1.2 version, we built a test cluster that is exactly the same as the Xiaomi online Doris 0.13 version in terms of machine configuration and machine scale, for verification before the vectorized version goes online. Validation testing is divided into two areas:Single SQL serial query test and batch SQL concurrent query test. In these two tests, we executed the same query SQL on the Doris 1.1.2 test cluster and the Doris 0.13 cluster on Xiaomi’s line, respectively, for performance comparison under the condition that the data of the two clusters are exactly the same.Our goal is that the Doris 1.1.2 version has a double query performance improvement based on the Xiaomi online Doris 0.13 version.
The configurations of the two clusters are exactly the same, and the specific configuration information is as follows:
Cluster size: 3 FE + 89 BE
BE node CPU: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz 16 cores 32 threads × 2
BE node memory: 256GB
BE node disk: 7.3TB × 12 HDD
-
Single SQL serial query test
In this test scenario, we selected 7 typical query cases in the Xiaomi A/B experimental scenario. For each query case, we limited the scanned data time range to 1 day, 7 days, and 20 days for query testing. , where the daily partition data magnitude is about 3.1 billion (the data volume is about 2 TB), and the test results are shown in the figure:
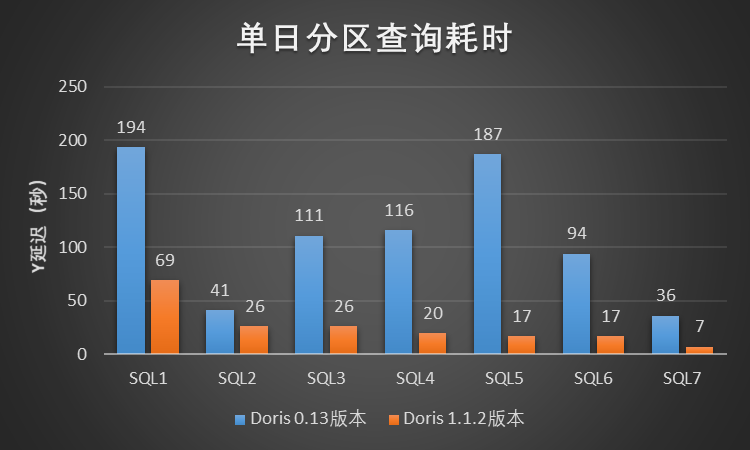
Figure 2 – Time-consuming partition query in a single day
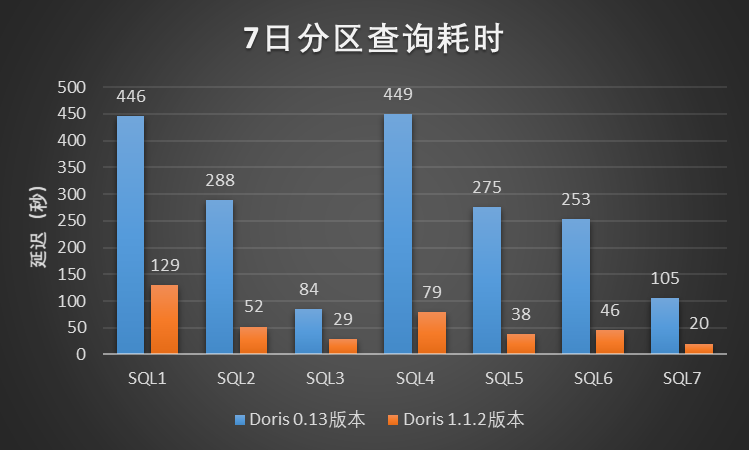
Figure 3-7 Time-consuming partition query
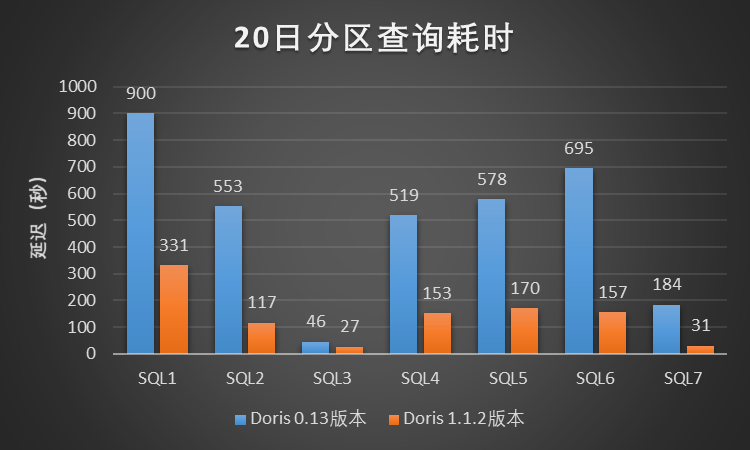
Figure 4-20 Day partition query time-consuming
According to the above single SQL serial query test results in the Xiaomi A/B experimental scenario, Doris 1.1.2 version has at least 3~5 times performance improvement compared to Xiaomi online Doris 0.13 version, the effect is remarkable, and the improvement effect is much higher than expected.
-
Batch SQL concurrent query test
In the concurrency test, we submitted the query SQL of the Xiaomi A/B experimental scenario to the Doris 1.1.2 test cluster and the Xiaomi online Doris 0.13 cluster respectively according to normal business concurrency, and compared and observed the status and query delay of the two clusters. The test results show that under the same machine scale, machine configuration and query scenarios, the query delay of Doris 1.1.2 version has doubled compared with the online Doris 0.13 version, and the query performance has dropped significantly. In addition, Doris 1.1. 2 There are also serious problems in version stability, and a large number of query errors will be reported during the query process. The results of the Doris 1.1.2 version in the Xiaomi A/B experimental scene concurrent query test are quite different from our expectations. During the concurrent query test, we encountered several serious problems:
When the query is sent to the cluster of Doris version 1.1.2, the CPU usage can only hit about 50% at most, but when the same batch of queries is sent to the online cluster of Doris version 0.13, the CPU usage can reach close to 100%. Therefore, it is speculated that the Doris 1.1.2 version will not be able to utilize the CPU of the machine in the Xiaomi A/B experimental scenario, resulting in a significant decrease in query performance.

Figure 5-CPU usage comparison between Doris 1.1.2 and Doris 0.13
When users submit queries concurrently, the following error will appear, subsequent query tasks cannot be executed, and the cluster is completely in an unavailable state, which can only be recovered by restarting the BE node.
RpcException, msg: timeout when waiting for send fragments RPC. Wait(sec): 5, host: 10.142.86.26
When the user submits the query, the following error will frequently appear:
detailMessage = failed to initialize storage reader. tablet=440712.1030396814.29476aaa20a4795e-b4dbf9ac52ee56be, res=-214, backend=10.118.49.24
In the Xiaomi A/B experimental scene, there are many queries that use the Like statement for string fuzzy matching. During the concurrent test, the performance of this type of query is generally low.
During the concurrent query test, the overall execution of SQL is slow. By capturing the CPU flame graph during the query, it is found that memory copying takes more time when reading string type data.
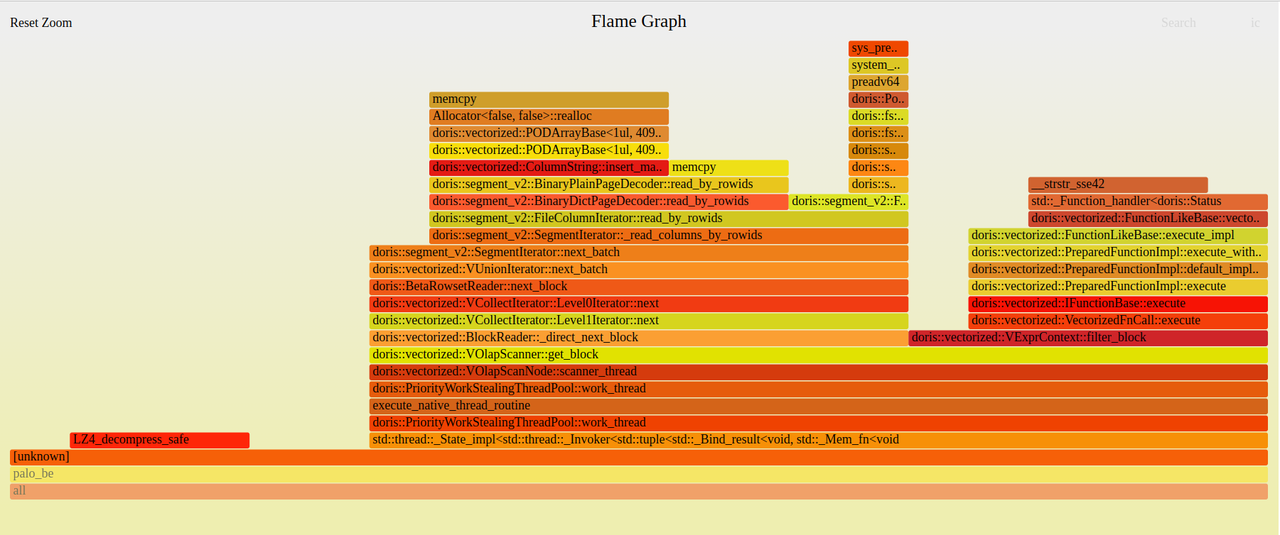
Figure 6 – CPU flame graph
tuning practice
In order to solve the performance and stability problems exposed by the Doris 1.1.2 version in the concurrent testing process of the Xiaomi A/B experimental scene, and promote the Doris vectorized version to be launched on the Xiaomi A/B experimental platform as soon as possible, we cooperated with SelectDB and the Apache Doris community We have done a series of tuning work on Doris version 1.1.2 together.
-
Increase CPU usage
Aiming at the problem that the CPU usage rate does not increase during concurrent queries, we intercepted the function call stack of the BE process during the query process. Through analysis, we found that there are many memory allocation and release operations waiting for locks, which may cause CPU usage. Can’t go up.
#0 sys_futex (v3=0, a2=0x0, t=0x7f786c9e7a00, v=<optimized out>, o=128, a=0x560451827c48 <tcmalloc::Static::pageheap_lock_>) at /root/doris/doris/be/src/gutil/linux_syscall_support.h:2419
#1 SpinLockDelay (loop=1822369984, value=2, w=0x560451827c48 <tcmalloc::Static::pageheap_lock_>) at /root/doris/doris/be/src/gutil/spinlock_linux-inl.h:80
#2 base::internal::SpinLockDelay (w=w@entry=0x560451827c48 <tcmalloc::Static::pageheap_lock_>, value=2, loop=loop@entry=20) at /root/doris/doris/be/src/gutil/spinlock_linux-inl.h:68
#3 0x000056044cfd825d in SpinLock::SlowLock (this=0x560451827c48 <tcmalloc::Static::pageheap_lock_>) at src/base/spinlock.cc:118
#4 0x000056044f013a25 in Lock (this=<optimized out>) at src/base/spinlock.h:69
#5 SpinLockHolder (l=<optimized out>, this=0x7f786c9e7a90) at src/base/spinlock.h:124
#6 (anonymous namespace)::do_malloc_pages(tcmalloc::ThreadCache*, unsigned long) () at src/tcmalloc.cc:1360
...
#0 sys_futex (v3=0, a2=0x0, t=0x7f7494858b20, v=<optimized out>, o=128, a=0x560451827c48 <tcmalloc::Static::pageheap_lock_>) at /root/doris/doris/be/src/gutil/linux_syscall_support.h:2419
#1 SpinLockDelay (loop=-1803179840, value=2, w=0x560451827c48 <tcmalloc::Static::pageheap_lock_>) at /root/doris/doris/be/src/gutil/spinlock_linux-inl.h:80
#2 base::internal::SpinLockDelay (w=w@entry=0x560451827c48 <tcmalloc::Static::pageheap_lock_>, value=2, loop=loop@entry=2) at /root/doris/doris/be/src/gutil/spinlock_linux-inl.h:68
#3 0x000056044cfd825d in SpinLock::SlowLock (this=0x560451827c48 <tcmalloc::Static::pageheap_lock_>) at src/base/spinlock.cc:118
#4 0x000056044f01480d in Lock (this=<optimized out>) at src/base/spinlock.h:69
#5 SpinLockHolder (l=<optimized out>, this=0x7f7494858bb0) at src/base/spinlock.h:124
#6 (anonymous namespace)::do_free_pages(tcmalloc::Span*, void*) [clone .constprop.0] () at src/tcmalloc.cc:1435
...
Doris uses TCMalloc for memory management. According to the size of the allocated and freed memory, TCMalloc divides the memory allocation strategy into two categories: small memory management and large memory management.
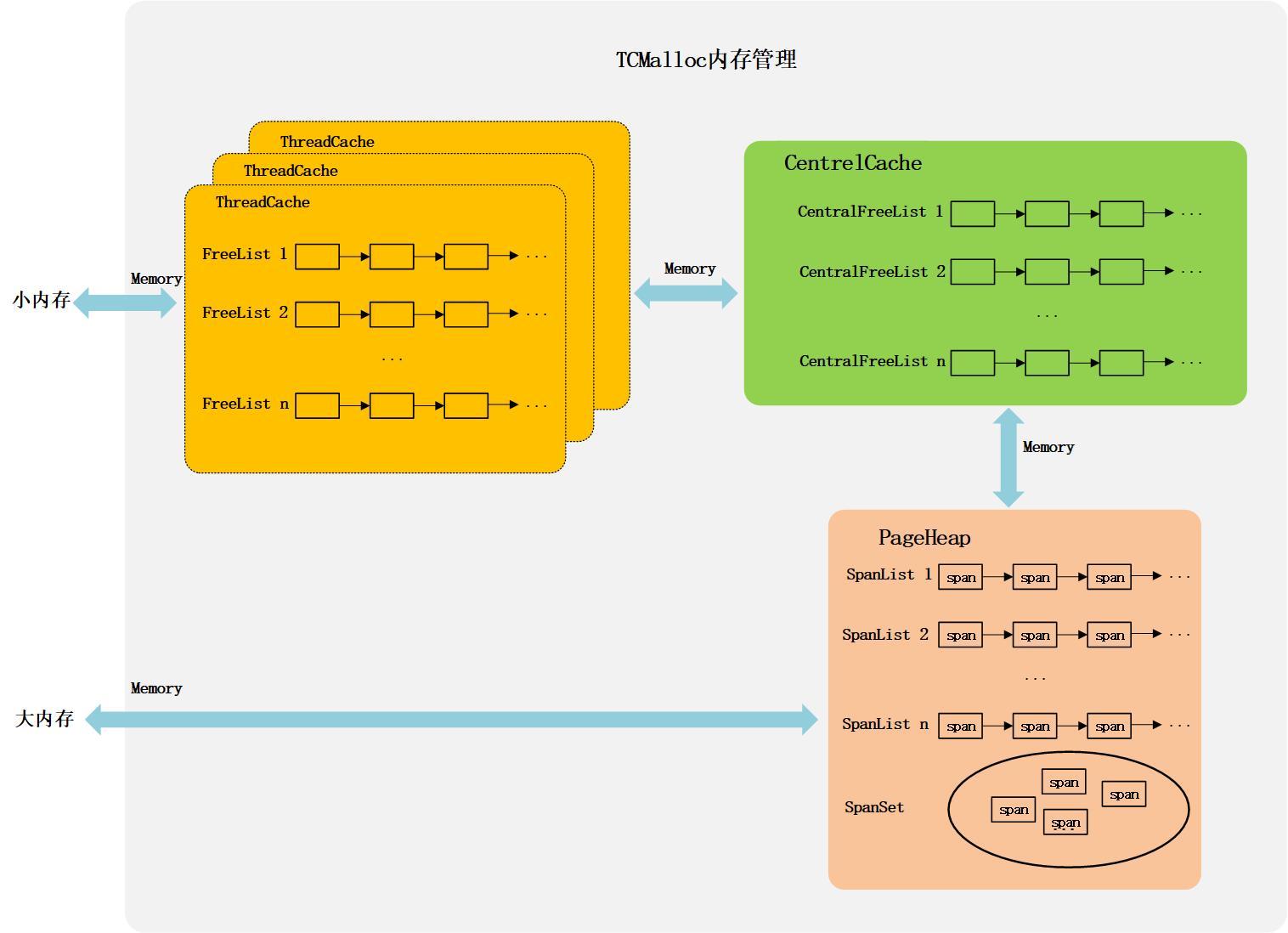
Figure 7-TCMalloc memory management mechanism
(1) Small memory management
TCMalloc uses ThreadCache, CentralCache and PageHeap three-tier cache to manage the allocation and release of small memory.
For each thread, TCMalloc maintains a ThreadCache separately for it, and each ThreadCache contains multiple separate FreeLists, and each FreeList caches N fixed-size memory units available for allocation. When small memory is allocated, it will be directly allocated from ThreadCache. Correspondingly, the recovery of small memory is to put the free memory back into the corresponding FreeList in ThreadCache. Since each thread has its own independent ThreadCache, there is no need to lock to allocate or reclaim memory from ThreadCache, which can improve memory management efficiency.
When memory is allocated, if the corresponding FreeList in ThreadCache is empty, it needs to obtain memory from CertralCache to supplement its own FreeList. CentralCache maintains multiple CentralFreeList linked lists to cache free memory of different sizes for the ThreadCache of each thread to access. Since CentralCache is shared by all threads, ThreadCache needs to be locked when fetching or putting back memory from CentralCache. In order to reduce the overhead of lock operations, ThreadCache generally applies for or puts back multiple free memory units from CentralCache at one time.
When the corresponding CentralFreeList in CentralCache is empty, CentralCache will apply for a block of memory from PageHeap, split it into a series of small memory units, and add them to the corresponding CentralFreeList. PageHeap is used to handle operations related to applying for or releasing memory from the operating system, and provides a layer of caching. The cache part in PageHeap will take Page as the unit, and combine different numbers of Pages into Spans of different sizes, which are stored in different SpanLists, and too large Spans will be stored in a SpanSet. The memory that CentralCache obtains from PageHeap may come from PageHeap’s cache, or from the new memory that PageHeap applies to the system.
(2) Large memory management
The allocation and release of large memory is realized directly through PageHeap. The allocated memory may come from the cache of PageHeap, or it may come from the new memory requested by PageHeap from the system. PageHeap needs to be locked when applying for or releasing memory from the system.
in TCMalloc aggressive_memory_decommitThe parameter is used to configure whether to actively release memory to the operating system.when set totrueWhen , PageHeap will actively release free memory to the operating system to save system memory; when this configuration is set to falsePageHeap will cache more free memory, which can improve memory allocation efficiency, but it will take up more system memory; in Doris, this parameter defaults to true.
By analyzing the call stack during the query process, it is found that there are more threads stuck in the lock-waiting stage when PageHeap applies for or releases memory from the system. Therefore, we try toaggressive_memory_decommitThe parameter is set tofalse, let PageHeap cache more free memory. Sure enough, after the adjustment is complete, the CPU usage can hit almost 100%. In the Doris 1.1.2 version, data is stored in columns in memory, so there will be greater memory management overhead compared to the row-based storage in Doris 0.13.
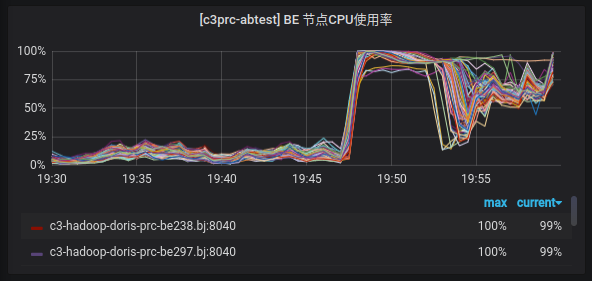
Figure 8 – CPU usage of Doris 1.1.2 test cluster after tuning
Community-related PRs:
https://github.com/apache/doris/pull/12427
-
Alleviate the problem of FE sending Fragment timeout
In version 1.1.2 of Doris, if a query task has more than one Fragment, the query plan will be executed in two phases (Two Phase Execution)Strategy. In the first stage, FE will deliver all Fragments to the BE node, and perform corresponding preparations for the Fragments on the BE to ensure that the Fragments are ready to process data; when the Fragments complete the preparations, the thread will enter a dormant state. In the second stage, FE will issue the Fragment execution command to BE again through RPC. After receiving the Fragment execution command, BE will wake up the sleeping thread and formally execute the query plan.
RpcException, msg: timeout when waiting for send fragments RPC. Wait(sec): 5, host: 10.142.86.26
When the user executes the query, the above error will continue to be reported, and any query cannot be executed. By intercepting the call stack of the process, the analysis found that a large number of threads are in the dormant state, and they are all blocked in the state where the Fragment completes the preparation work and sleeps waiting to be awakened. The investigation found that there is a bug in the two-stage execution mechanism of the query plan. If the execution plan is canceled by FE, the threads on BE that have completed Fragment preparation and are sleeping and waiting will not be awakened, resulting in the exhaustion of the Fragment thread pool on BE. After the fragments of all subsequent query tasks are delivered to the BE node, they will wait until the RPC times out because there are no thread resources.
In order to solve this problem, we introduced related repair patches from the community, and added a timeout wake-up mechanism for dormant threads. If the thread is woken up by timeout, the Fragment will be canceled, thereby releasing thread resources, which greatly eases the execution plan issued by FE. RPC timeout problem.
This problem has not been completely solved, and it will occasionally appear when the query concurrency is large. In addition, we also introduced other patches related to the Doris community to alleviate this problem, such as: reducing the Thrift Size of the execution plan, and replacing a single RPC Stub with a pooled RPC Stub.
Community-related PRs are as follows:
https://github.com/apache/doris/pull/12392
https://github.com/apache/doris/pull/12495
https://github.com/apache/doris/pull/12459
-
Fix the bug reported by Tablet metadata
In Doris, BE will periodically check whether all tablets on the current node are missing versions, and report the status and meta information of all tablets to FE, and FE will compare the three copies of each tablet to confirm the abnormal copy. And issue the Clone task to restore the missing version of the abnormal copy through the data file of the normal copy of Clone.
detailMessage = failed to initialize storage reader. tablet=440712.1030396814.29476aaa20a4795e-b4dbf9ac52ee56be, res=-214, backend=10.118.49.24
In this error message, the error coderes=-214(OLAP_ERR_VERSION_NOT_EXIST) indicates that an exception occurs when the Rowset Reader is initialized on the BE during the execution of the query plan, and the corresponding data version does not exist. Under normal circumstances, if there is a missing version in a certain copy of the tablet, FE will not let the query fall on the copy when generating the execution plan. However, when the query plan is executed on the BE, but the version does not exist, then It means that FE has not detected that there is a missing version in this copy.
After checking the code, it is found that there is a bug in BE’s tablet reporting mechanism. When a copy has a missing version, BE does not report this situation to FE normally, resulting in these abnormal copies with missing version not being detected by FE. Therefore, The copy repair task will not be issued, which will eventually cause the query process to occurres=-214of error.
Community-related PRs are as follows:
https://github.com/apache/doris/pull/12415
-
Optimize Like statement performance
When using the Like statement in Doris 1.1.2 version for string fuzzy matching query, the bottom layer of Doris actually uses the standard librarystd::search()函数Perform line-by-line matching on the data read from the storage layer, filter out data lines that do not meet the requirements, and complete the fuzzy matching of the Like statement.Through research and comparative testing, it is found that the GLIBC librarystd::strstr()函数for string matchingstd::search()函数There is a performance improvement of more than 1 times.In the end we usestd::strstr()函数As the underlying string matching algorithm of Doris, the performance of Doris underlying string matching can be doubled.
-
Optimize memory copy
In Xiaomi’s scene, there are many query fields of string type. Doris 1.1.2 version uses ColumnString object to store a column of string data in memory, and the bottom layer uses PODArray structure to actually store strings. When executing a query, string data needs to be read row by row from the storage layer. During this process, the Resize operation needs to be performed on PODArray multiple times to apply for a larger storage space for the column data. Executing the Resize operation will cause the read character String data is copied in memory, and the memory copy in the query process is very time-consuming and has a great impact on query performance.
In order to reduce the cost of memory copy during the string query process, we need to minimize the number of Resize operations performed on PODArray. In view of the fact that the string lengths of different rows in the same column in the Xiaomi A/B experimental scenario are relatively uniform, we try to apply for enough memory for the strings to be read in advance to reduce the number of resizes, thereby reducing the memory copy overhead. During data scanning, the number of data rows that each Batch needs to read is determined (assumed to be n). n) line, we estimate the PODArray size required for all n lines of string data according to the PODArray size of the first m lines, and apply for memory in advance to avoid multiple executions of memory application and memory copy when reading line by line later.
The memory estimation formula is:
所需PODArray总大小 = (当前PODArray总大小 / m)* n
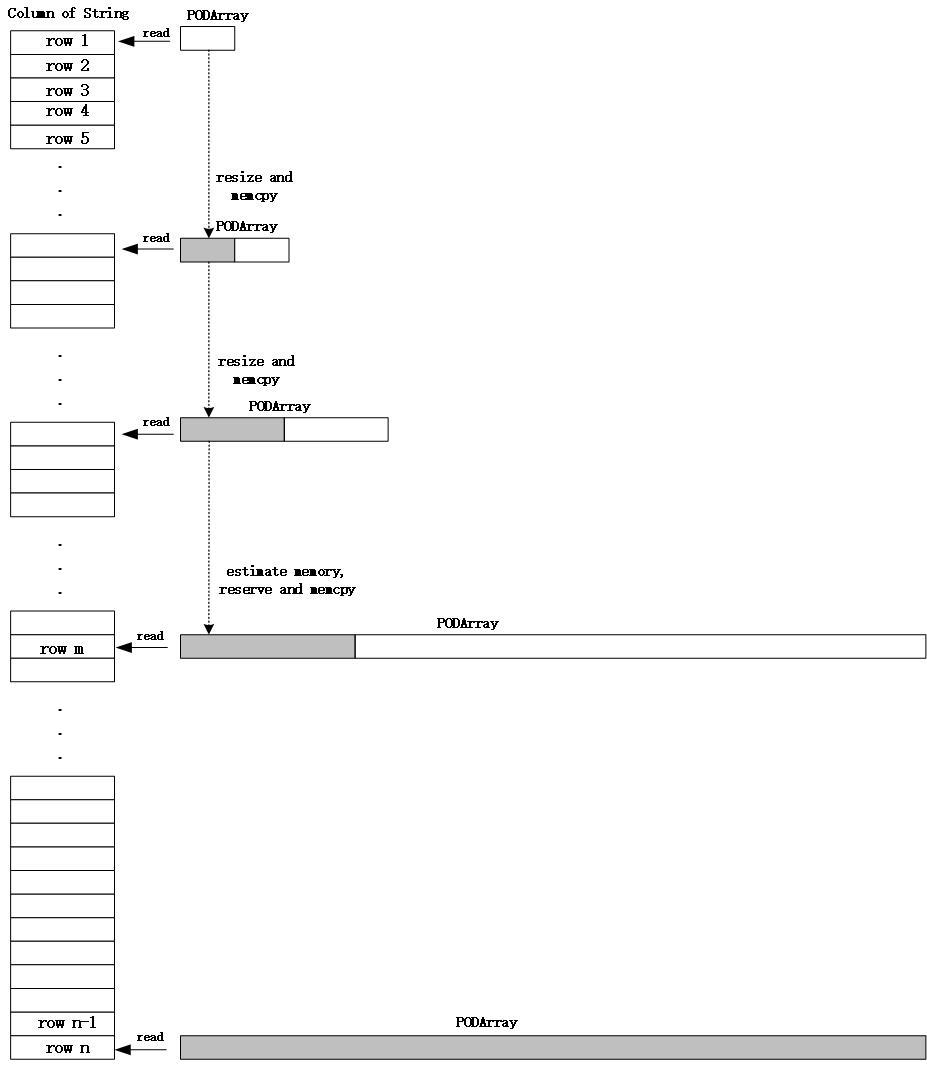
Figure 9 – Optimizing memory copy overhead
Of course, this method only estimates the required memory, and applies for memory in advance according to the estimated size, which reduces a large number of Resize operations when reading strings line by line, and reduces the number of memory applications and memory copies. It does not completely eliminate memory copying during string reading. This optimization scheme is only effective when the length of strings in a column is relatively uniform, and the estimated memory will be relatively close to the actual memory. If the string lengths in a column vary greatly, the effect of this method may not be obvious, and may even cause memory waste.
Tuning test results
Based on Xiaomi’s A/B experimental scenario, we conducted a series of optimizations on Doris 1.1.2, and conducted concurrent query tests on the optimized Doris 1.1.2 and Xiaomi’s online Doris 0.13. The test situation is as follows:
test 1
We selected a batch of typical user deduplication, index summation, and covariance calculation query cases (the total number of SQL is 3245) in the A/B experimental scenario to conduct concurrent query tests on the two versions, and test the single-day partition data of the table It is about 3.1 billion (the amount of data is about 2 TB), and the data range of the query will cover the partitions of the latest week. The test results are shown in the figure. Compared with Doris0.13, the overall average delay of Doris 1.1.2 version is reduced by about 48%, and the P95 delay is reduced by about 49%. In this test, the query performance of Doris 1.1.2 version is nearly doubled compared with Doris 0.13 version.
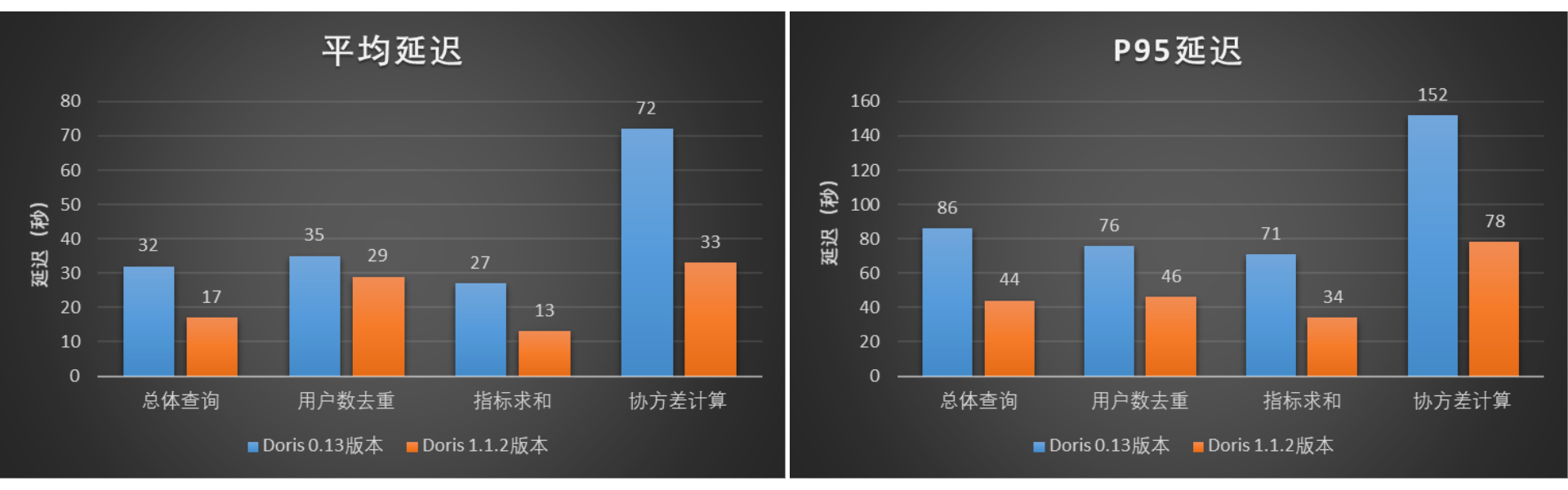
Figure 10 – Query Average Latency and P95 Latency
test 2
We selected 7 A/B experiment reports in the A/B experiment scenario to test the two versions. Each A/B experiment report corresponds to two modules on the Xiaomi A/B experiment platform page, and each module corresponds to hundreds of Or thousands of query SQL. Each experimental report submits query tasks to the cluster where the two versions reside at the same concurrency. The test results are shown in the figure. Compared with Doris 0.13, Doris 1.1.2 reduces the overall average delay by about 52%. In this test, the query performance of Doris 1.1.2 version is more than 1 times higher than that of Doris 0.13 version.
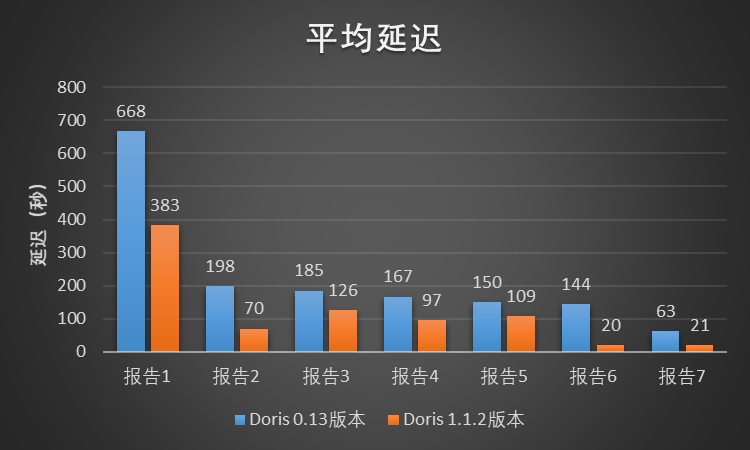
Figure 11 – Query Average Latency
test 3
In order to verify the performance of the tuned Doris 1.1.2 version outside the Xiaomi A/B experimental scenario, we selected the Xiaomi user behavior analysis scenario to conduct concurrent query performance tests of Doris 1.1.2 and Doris 0.13. We selected the real behavior analysis query Cases on Xiaomi Online for 4 days on October 24, 25, 26 and 27, 2022 for comparison and query. The test results are shown in the figure. Compared with Doris 1.1.2, Doris For version 0.13, the overall average latency has been reduced by about 77%, and the P95 latency has been reduced by about 83%. In this test, the query performance of Doris 1.1.2 version is 4~6 times higher than that of Doris 0.13 version.
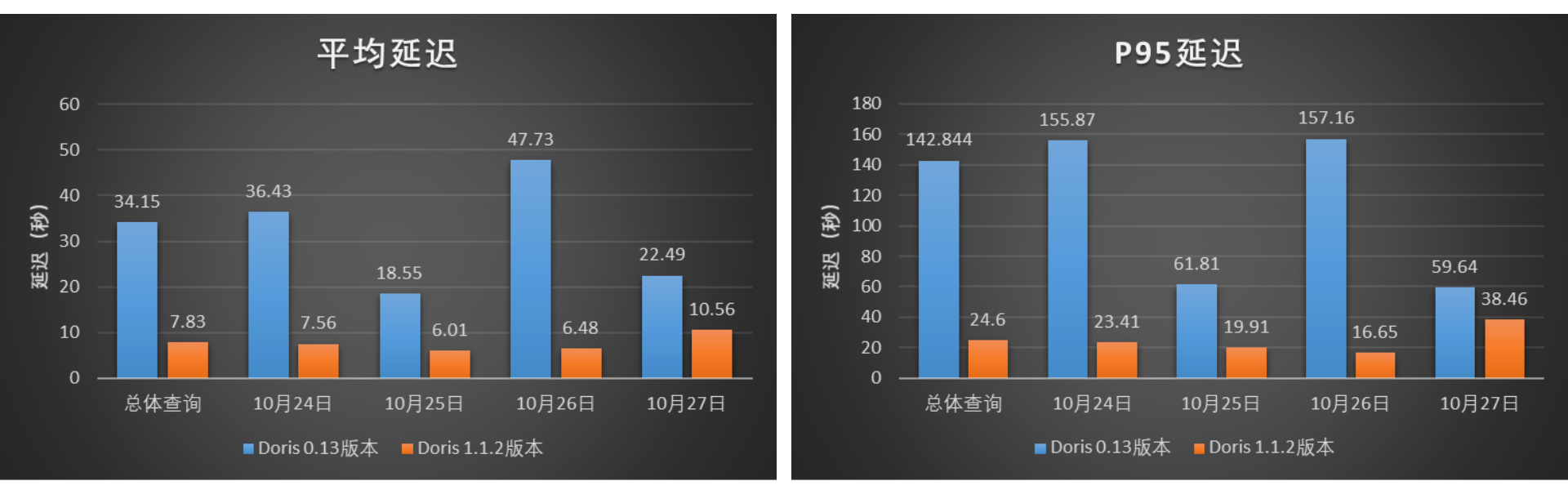
Figure 12 – Query Average Latency and P95 Latency
conclusion
After more than a month of performance tuning and testing, Apache Doris version 1.1.2 has met the launch requirements of the Xiaomi A/B experimental platform in terms of query performance and stability, and the query performance even exceeds ours in some scenarios. It is expected that this sharing can give friends in need some experience and reference for reference.
Finally, I would like to thank the SelectDB company and the Apache Doris community for their support, and thank Mr. Yi Guolei for his full participation and company in the process of tuning and testing our version. Apache Doris has been widely used within the Xiaomi Group, and the business continues to grow. In the future, we will gradually promote other Apache Doris businesses within Xiaomi to launch vectorized versions.
#query #performance #significantly #improved #optimization #practice #vectorized #version #Apache #Doris #Xiaomi #experimental #scenarioBest #PracticeSelectDBs #Personal #Space #News Fast Delivery