Author: vivo Internet Server Team – Xiong yangxin
Packaging a general solution into a mature toolkit is a problem that every technical construction worker must think about and solve. This article starts with the existing toolkits that are popular in the industry, analyzes the implementation ideas, and precipitates the general methods. Provide some references for practical ideas for beginners in technical construction. In particular, the “decentralized” collaboration model and the “key link + development interface” development model advocated in the article have certain practical significance. Of course, there is inevitably a certain degree of subjective bias in the writing of this article, and readers can read it as appropriate.
I. Introduction
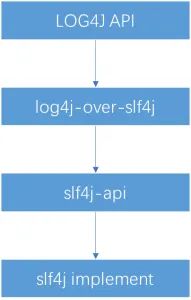
Students who are familiar with JAVA server development should have used the log module, and have used the two packages “log4j-over-slf4j” and “slf4j-log4j” with a high probability. So what is the difference between these two packages? Why do they refer to each other? This article will explain the difference between these concepts.
first of allSLF4J.
2. Start with SLF4J
SLF4JThe full name is “Simple Logging Facade for Java (SLF4J)”, the purpose of its birth is to provide a unified interface adaptation standard for different log solutions, so that business code does not need to care about the third-party modules used Which log schemes are used.
For example, the log modules used by Apache Dubbo and RabbitMQ are different. In a sense, SLF4J is just a facade, similar to ODBC back then (a unified interface standard developed for different database vendors, which will be covered below). And the package name corresponding to this facade is “slf4j-api-xxx.xxx.xxx.jar”. so,When you apply the “slf4j-api-xxx.jar” package, it actually only introduces a log interface standard, but does not introduce the log implementation.
2.1. Implementation in the industry
The core classes of the SLF4J standard in the application layer are two: org.slf4j.Logger and org.slf4j.LoggerFactory. Among them, since version 1.6.0, if there is no specific implementation, slf4j-api will provide a Logger implementation (org.slf4j.helpers.NOPLogger) that does nothing by default.
In the current market (this manuscript was drafted on 2022-03-01), the existing solutions for implementing SLF4J are as follows:
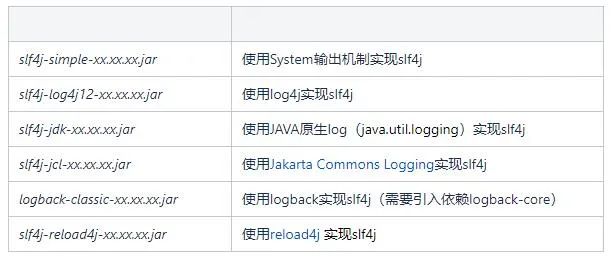
The overall hierarchy is as follows:
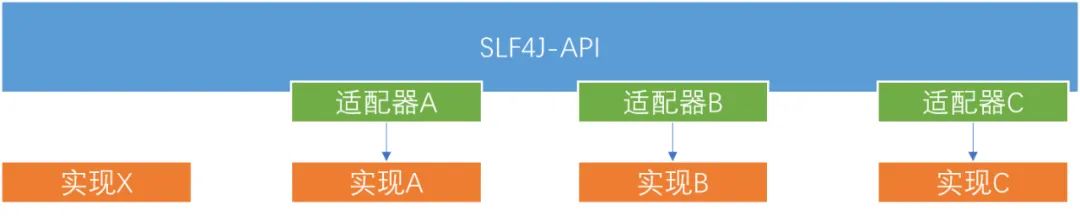
In summary:The jar package starting with SLF4J- generally refers to the slf4j solution implemented by a third-party framework.
2.2 Working Mechanism
So how does the entire SLF4J working mechanism work? In other words, how does the system know which implementation to use?
For the native implementation that does not require an adapter, just import the corresponding package directly.
For the entrusted implementation that requires an adapter, it is necessary to tell SLF4J which implementation class to use through another channel: the SPI mechanism.
As an example, let’s look at the package structure of slf4j-log4j:
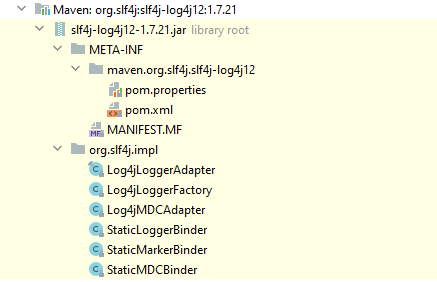
Let’s look at the pom file first, which contains two dependencies:
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId></dependency>
slf4j-log4j introduces both slf4j-api and log4j. Then the role of slf4j-log4j itself is self-evident: use the function of LOG4J to realize the interface standard of SLF4J.
The overall interface/class relationship path is as follows:
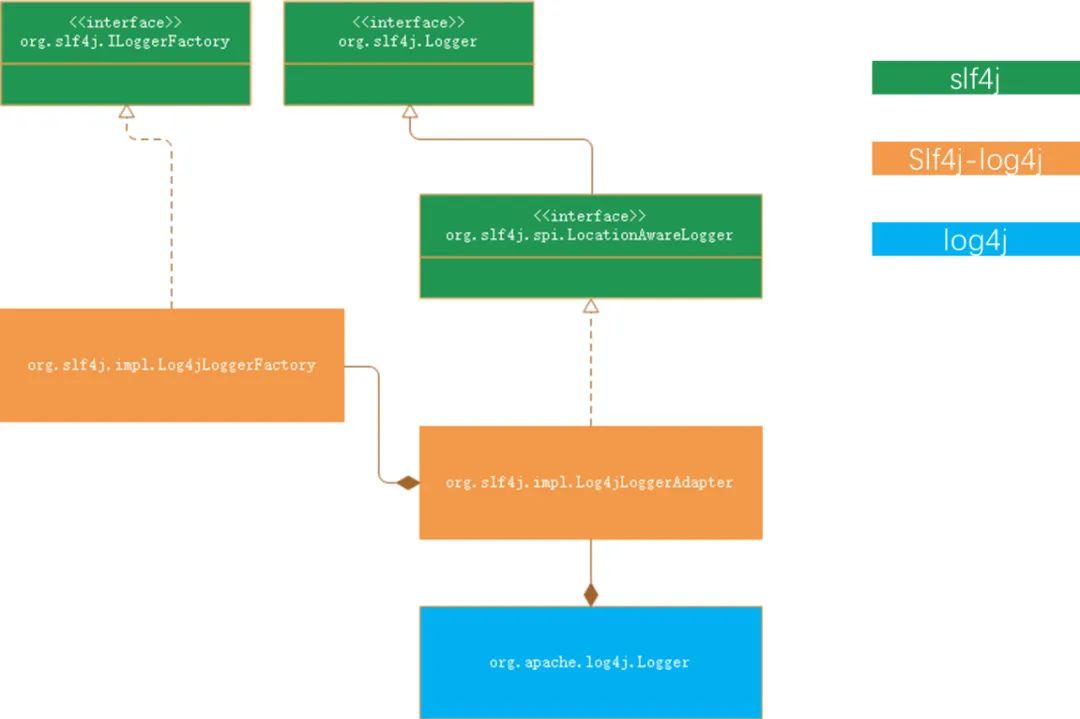
But this still doesn’t solve the problem raised at the beginning of this chapter (how does the program know which Logger to use).
You can start from the source code: (slf4j/slf4j-log4j12 at master qos-ch/slf4j GitHub), we saw the following key files:

That is to say: slf4j-log4j uses java’s SPI mechanism to tell the JVM which implementation class to call at runtime. Since the SPI mechanism does not belong to the scope of this article, readers can go to the official website to obtain information.
Readers can go to GitHub – qos-ch/slf4j: Simple Logging Facade for Java to see how other implementations of adapters work.
Then the answer to the question at the beginning of this chapter is:
SLF4J formulates a set of log printing process, and then abstracts the core class out of the interface for external implementation;
The adapter uses third-party log components to implement these core class interfaces, and uses the SPI mechanism to make JAVA runtime aware of the specific implementation classes of the core interfaces.
The above two points constitute the knowledge point that this article will describe next: the delegation model.
3. Delegation mode
From the above, we start fromSLF4JThe case of the case leads to the concept of “delegation mode”. Next, we will focus on the delegation mode.
Next, we explain the delegation model from three questions in sequence according to the cognitive process:
Then in the next chapter, we will use typical cases in the industry to analyze the use of the delegation model.
3.1 Why use the delegation model?
We return to SLF4J. Why does it use the delegation mode? Because there are various implementations of the log printing function. For application developers, it is best to need a standard printing process. Other third-party components may be different in some places, but the core process is best not to change. For the standard maker, he cannot control all the details of each third-party component, so he can only expose limited customization capabilities.
And when we zoom in to the software field, or in the field of Internet development, the collaboration mode of different developers mainly depends on the jar package application: a third party develops a toolkit and puts it in the central warehouse (maven, gradle), and the user learns from other information Channels (csdn, stackoverflow, etc.) locate this jar package according to the problem, and then reference it in the code project. Theoretically, if the third-party jar package is very stable (such as c3p0), then the maintainer of the jar package will seldom or even almost never establish contact with users. If some middleware developers feel that they do not meet the needs of their company/department, they will make another custom packaging based on the jar package.
Looking at the entire process above, it is not difficult to find two points:
Toolkit developers and users have not established a stable collaboration channel
Toolkit developers have little control over the development of their finished product
So what if someone wants to establish a set of standards? For example, the log standard, such as the database connection standard, then only a few large company alliances, or well-known development team alliances can formulate a standard and implement the core link part. As for why all links are not implemented, the reason is also very simple: collaboration in the software field itself is weakly centralized, otherwise if you do not bring others to play, others will not adopt your standard (refer to COBOL promoted by IBM back then).
To sum up: the delegation model is a better software structure model based on the collaborative characteristics of the current software field.
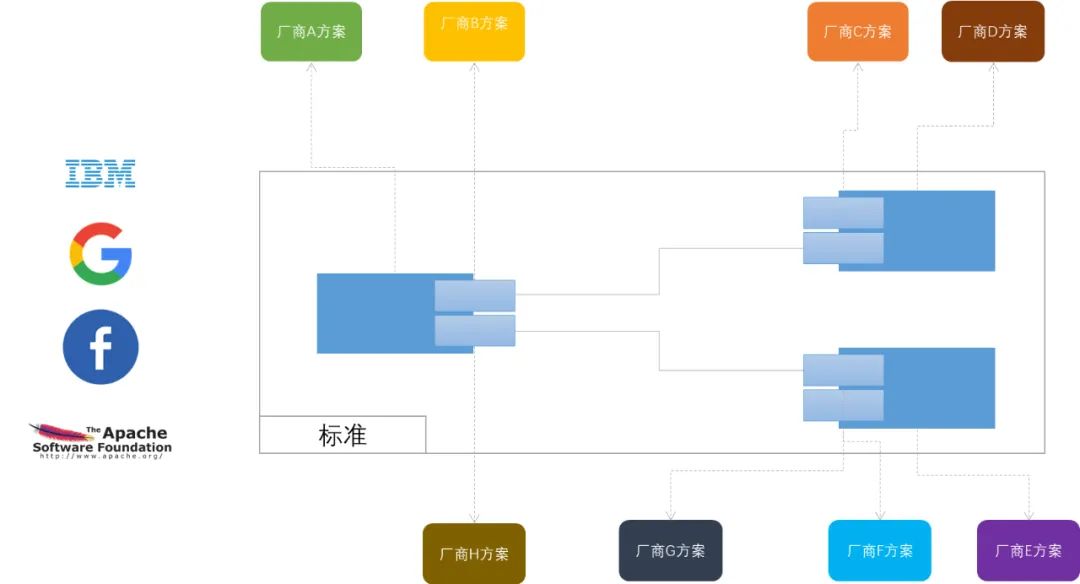
So when to use the delegation model?
Here is a counter-example in the hardware field: the fast charging standard. In 2018 or even earlier, consumers will need a fast charging function. However, fast charging needs to customize a lot of hardware to achieve, so at this time, the first condition is met, but at that time, there was no team or company that could control the entire ecology of Android mobile phone hardware, and it was impossible to jointly launch a centralized team to be responsible, which led to various mobile phones. The fast charging function of the manufacturer is in full bloom: the fast charging cable of company A cannot fast charge the mobile phone of company B.
3.2 What is the delegation mode?
Based on the above discussion, the core composition of the delegation model is obvious:Core links, open interfaces.
The core link refers to:In order to achieve a certain purpose, a specific group of components, in accordance with a specific order and a specific collaborative standard, jointly execute the logic of calculation.
An open interface refers to:Given specific inputs and outputs, the implementation details are left to the external functional interface.
To give a more realistic example: traditional cars.
Almost every traditional car is integrated and coordinated according to three major parts: engine, transmission, and chassis. The engine does the work, and the power is transferred to the chassis through the transmission (it’s not standard to say so, and even in the eyes of workers in the auto industry, this description is almost a fallacy, but it is roughly the same). Also based on this, the engine interface, gearbox interface, and chassis interface have all been fixed, and the rest is realized by each manufacturer: Mitsubishi’s engine, Nissan’s engine, Aisin’s gearbox, and ZF’s gearbox , Rumford’s chassis, TRW’s chassis and so on. Even the joints of the tires were worked out: Continental tires, Bridgestone tires, Goodyear tires.
Different car manufacturers choose components from different companies to integrate a certain car model. Of course, there are also companies that achieve a certain standard by themselves: for example, Volkswagen produces the EA888 engine itself, and PSA is proud of the chassis produced and tuned by itself.
If you feel that you are not familiar enough, you can give an example of tomcat.
Software developers who have experienced the 2000s should know how difficult it was to develop a web application at that time: how to monitor sockets, how to encode and decode, how to deal with concurrency, how to manage processes, and so on. But one thing is common: every web developer wants a framework to manage the protocol layer and kernel layer of the entire http service. Then appeared JBoss, WebSphere, Tomcat (laughed last).
These products all specify the core link: listen to the socket → read the data packet → encapsulate it into an http message → dispatch it to the processing pool → the thread in the processing pool invokes the processing logic to process → encode the returned message → marshal it into a tcp packet → call kernel function → send out data.
Based on this core link, formulate standards: what is the input of the business processing logic, what is the output, and how to make the web framework recognize the business processing module.
Tomcat’s solution is web.xml. Developers only need to follow the web.xml standard to implement servlets. That is to say, in the entire http server link, Tomcat delegates several specific process processing components (listener, filter, interceptor, servlet) to business developers for implementation.
3.3 How to use the delegation mode
Before using the delegation mode, make a self-judgment based on the above pattern matching conditions:
If the first condition is not met, then there is no need to consider using the delegation mode; if the first condition is met but the second condition is not met, then the interface should be reserved first, and the interface implementation class should be developed by itself and injected into the main process by means of dependency injection. middle. This approach can be seen in many third-party dependency packages, such as spring’s BeanFactory, BeanAware, etc., as well as some hooks and filters reserved by various companies when developing SSO.
After deciding to use the delegation mode, the first thing to do is to “determine the core link”. This step is the most difficult, because users often have certain expectations, but asking them to describe them in detail is often not accurate enough, and sometimes even Afterwards, the primary and secondary are reversed. The author’s suggestion is: directly let them state the original needs/pain points, then try to give a solution by themselves, then compare their solutions, communicate, and gradually unify the two solutions. The process of unification is also a process of continuous testing and determination.
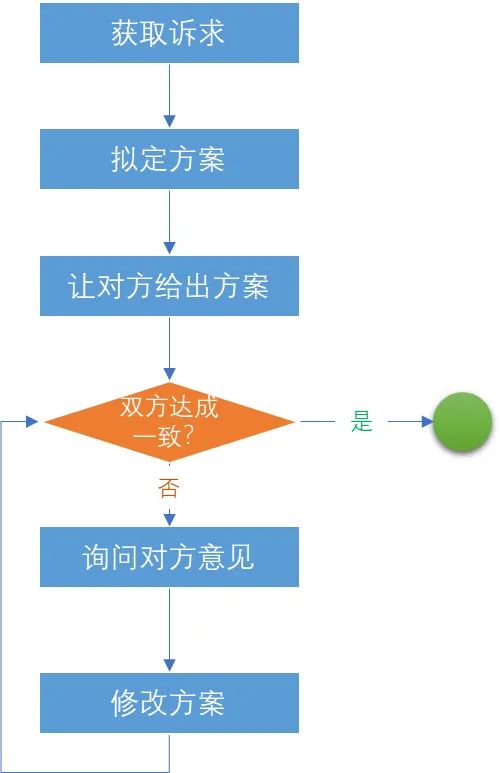
The above process is the author’s own experience, only as a reference.
After determining the core process, some functions in the process that need to be customized are abstracted into interfaces and exposed. In the definition of the interface, try to reduce the calling dependence on other classes in the whole process.
So the overall process is divided into three steps:Confirm the use of the pattern; extract the core process; abstract the open interface.
As for whether to use the SPI mechanism or use XML configuration identification like TOMCAT, it depends on the specific situation and will not be involved here.
4. Industry Cases
4.1 JDBC
The birth of JDBC is largely based on the idea of ODBC, and a special database connection specification JDBC (JAVA Database Connectivity) is designed for JAVA. The expected goal of JDBC is to allow Java developers to have a unified interface when writing database applications without relying on specific database APIs, so as to achieve “one-time development, applicable to all databases”. Although in actual development, the goal is often not achieved due to the use of database-specific syntax, data types, or functions, the JDBC standard greatly simplifies the development work.
Overall, the access structure of JDBC is roughly as follows:
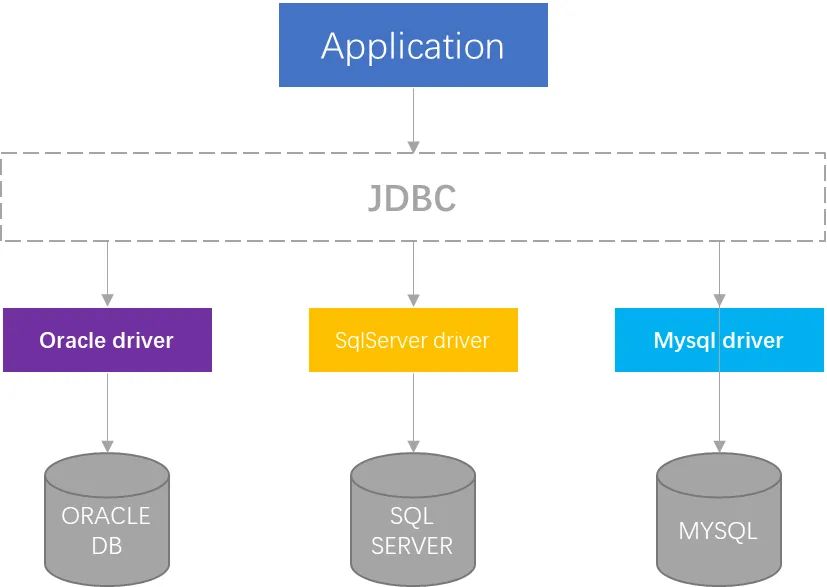
But in fact, at the beginning of the birth of JDBC, there were not many manufacturers on the market responding to SUN (SUN was not acquired by Oracle at that time), so SUN used the bridging mode introduced in this article, as shown in the following figure:
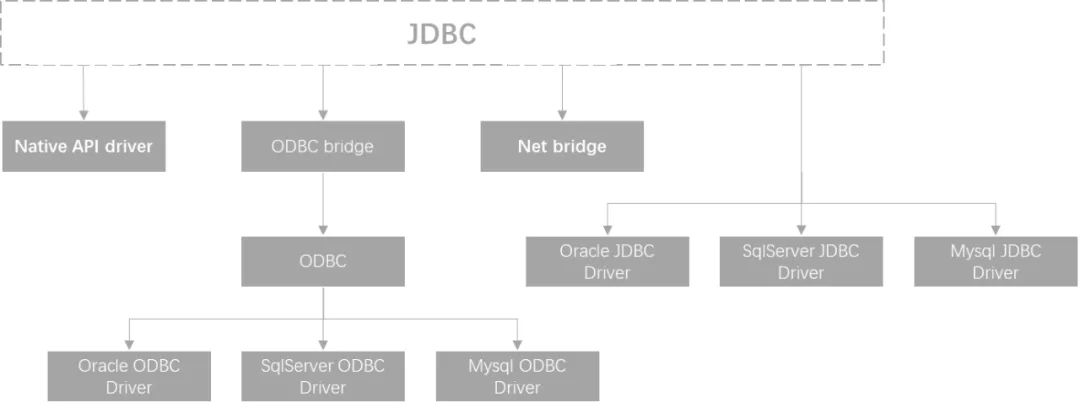
That is to say, formally, the structural form of preliminary delegation has appeared.
The following will only analyze the JDBC level of a single commission.
According to the above, every delegation structure must have two elements: the core path and the open interface. We start to analyze JDBC from these two dimensions.
The core path of JDBC is divided into six steps, including the two steps required by the delegation mechanism (introducing the package, declaring the delegation successor), a total of eight steps, as follows:
Import JDBC implementation package
Register JDBC Driver
Establish a connection with the database
Initiate transaction (if necessary), create statement
Execute the statement and read the return, stuff it into ResultSet
Processing ResultSet
Close ResultSet, close Statement
Close Connection
Throughout the whole process, the core participants are: Driver, Connection, Statement, ResultSet. Transaction is actually a session layer wrapped based on the three methods of Connection (setAutoCommit, commit, rollback), which theoretically does not belong to the standard layer.
Taking mysql-connector-java as an example, the specific implementation of the JDBC interface is as follows:
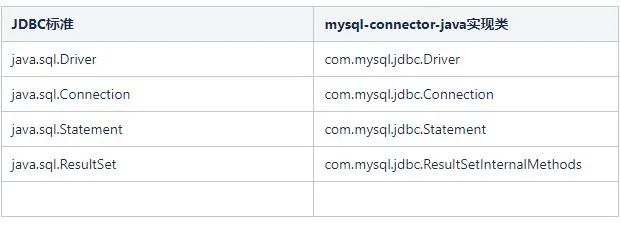
Through the overriding mechanism that comes with Java, as long as com.mysql.jdbc.Driver is used, the implementation classes of other components will be directly implemented by the application. Details are not discussed. So how does mysql-connector-java tell the JVM that com.mysql.jdbc.Driver should be used?
two modes
plaintext mode——Use Class.forName(“com.mysql.jdbc.Driver”) in clear text in the business code
SPA mechanism
In fact, the core of the above two methods is to initialize com.mysql.jdbc.Driver and execute the following class initialization logic.
try {DriverManager.registerDriver(new Driver());} catch (SQLException var1) {throw new RuntimeException("Can't register driver!");}
That is to say, JDBC maintains the information of the entrusted successor through DriveManager.If readers are interested in viewing the source code of DriverManager, they will find another way to realize JDBC class discovery.However, considering the length of the text, the author will not express it here.
4.2 Apache Dubbo
The core path of Dubbo is roughly as follows (without considering the service management set):
consumer call → parameter serialization → internet pleasebegging → Receive request → parameter deserialization → provider calculates and returns → result serialization → network return → The consumer side receives → result deserialization
(The italics represent the dubbo responsibilities of the consumer side, and the underline represents the dubbo responsibilities of the provider side)
There are many customizable interfaces in Dubbo, and a large number of “SPI-like” mechanisms are adopted as a whole, which provides a custom injection mechanism for many links in the entire RPC process. Compared with the traditional Java SPI, Dubbo SPI has made a lot of extensions and customizations in terms of encapsulation and implementation class discovery.
The overall implementation mechanism and working mechanism of Dubbo SPI are beyond the scope of this article, but for the convenience of writing, some necessary explanations are made here. The overall Dubbo SPI mechanism can be divided into three parts:
@SPI annotation– Declare the current interface class as an extensible interface.
@Adaptive annotation——declare that the current interface class (or the current method of the current interface class) can dynamically call the implementation method of the concrete implementation class according to specific conditions (value in the annotation).
@Activate annotation——declare that the current class/method implements an extensible interface (or the implementation of a specific method of the extensible interface), and indicate the conditions for activation, as well as the sorting information in all activated implementation classes.
We use Dubbo-Auth
(dubbo/dubbo-plugin/dubbo-auth at 3.0 · apache/dubbo · GitHub) as an example, analyze from the two dimensions of core path and open interface.
The implementation logic of Dubbo-Auth is based on the principle of Dubbo-filter, that is to say: Dubbo-Auth itself is the delegated implementer of a link in the overall process of Dubbo.
The core entry of Dubbo-Auth (that is, the starting point of the core path) is ProviderAuthFilter,
It is the specific implementation of org.apache.dubbo.auth.filter, that is to say:
org.apache.dubbo.auth.filter is a development interface exposed in the core link of dubbo (@SPI is marked on the class definition).
ProviderAuthFilter implements the development interface Filter exposed in the dubbo core link (ProviderAuthFilter implementation class definition is marked with @Activate).
The core path of ProviderAuthFilter is relatively simple: get the Authenticator object, and use the Authenticator object for auth verification.
The specific code is as follows:
(group = CommonConstants.PROVIDER, order = -10000)public class ProviderAuthFilter implements Filter {public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {URL url = invoker.getUrl();boolean shouldAuth = url.getParameter(Constants.SERVICE_AUTH, false);if (shouldAuth) {Authenticator authenticator = ExtensionLoader.getExtensionLoader(Authenticator.class).getExtension(url.getParameter(Constants.AUTHENTICATOR, Constants.DEFAULT_AUTHENTICATOR));try {authenticator.authenticate(invocation, url);} catch (Exception e) {return AsyncRpcResult.newDefaultAsyncResult(e, invocation);}}return invoker.invoke(invocation);}}
Note that in the above code
url.getParameter(Constants.AUTHENTICATOR, Constants.DEFAULT_AUTHENTICATOR)
It is a selection condition in the Adaptive mechanism of dubbo spi. Readers can study it in depth, and this article skips it here.
Since the core path includes the Authenticator, the Authenticator is naturally likely to be a development interface exposed to the outside world. That is to say, the declaration class of Authenticator must be annotated with @SPI.
("accessKey")public interface Authenticator {void sign(Invocation invocation, URL url);void authenticate(Invocation invocation, URL url) throws RpcAuthenticationException;}
The above code proves the author’s conjecture.
In Dubbo-Auth, a default Authenticator is provided: AccessKeyAuthenticator. In this implementation class, the core path is reified:
Get accessKeyPai;
Use accessKeyPair to calculate the signature;
Check whether the signature in the request is the same as the calculated signature.
In this core path, due to the introduction of the concept of accessKeyPair, a link is introduced: how to obtain accessKeyPair. For this, dubbo-auth defines an open interface: AccessKeyStorage.
public interface AccessKeyStorage {AccessKeyPair getAccessKey(URL url, Invocation invocation);}
4.3 LOG4J
In the last case, we return to the log component, and the reason why we introduce LOG4J is that it uses an unconventional “reverse delegation” mechanism.
LOG4J draws on the ideas of SLF4J (or is LOG4J the first? SLF4J borrows from LOG4J?), and also adopts the idea of interface standard + adapter + third-party solution to realize delegation.
So obviously, there is a problem here: SLF4J confirms its core path, and then exposes the interface to be implemented. When SLF4J-LOG4J tries to implement the interface to be implemented by SLF4J, it uses the delegation mechanism to outsource the relevant path details. out, thus forming a ring.
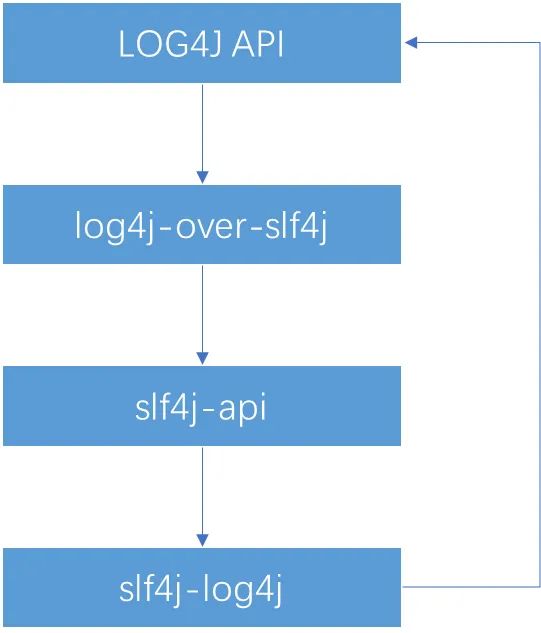
So, if I introduce “log4j-over-slf4j” and “slf4j-log4j” at the same time, it will cause stackoverflow.
This problem is very typical, and you may see many cases when you google it, such as Analysis of stack overflow exception of log4j-over-slf4j and slf4j-log4j12 coexistence – actorsfit, etc. The official also gave a warning (SLF4J Error Codes).
Since the focus of this article is on the delegation model, this issue will not be discussed in detail. The point of this case is to illustrate one thing:The disadvantage of the delegation mode is that the implementation logic of the open interface is uncontrollable.If there are major hidden dangers in the third-party implementation, it will cause problems in the overall core process.
V. Summary
In summary,
delegatedscenes to be usedyes:
delegatedcore point: core path, open interface.
delegatedhidden mechanism:Registration/discovery of implementations.
References:
SLF4J Manual
Using log4j2 with slf4j: java.lang.StackOverflowError – Stack Overflow
Creating Extensible Applications (The Java™ Tutorials > The Extension Mechanism > Creating and Using Extensions) (oracle.com)
slf4j/slf4j-log4j12 at master · qos-ch/slf4j · GitHub
Delegation pattern – Wikipedia
What is a JDBC driver? – IBM Documentation
Lesson: JDBC Basics (The Java™ Tutorials > JDBC Database Access) (oracle.com)
GitHub – apache/dubbo: Apache Dubbo is a high-performance, java based, open source RPC framework.
END
you may also like
#Delegation #ModeFrom #SLF4J #vivo #Internet #Technology #News Fast Delivery