
Rough sorting is an important module of the search and promotion system in the industry. In the exploration and practice of optimizing the effect of rough sorting, the Meituan search ranking team optimized rough sorting from two aspects of fine sorting linkage and effect performance joint optimization based on actual business scenarios, which improved the effect of rough sorting. This article introduces the iterative route of Meituan search for rough sorting, the rough sorting optimization work based on knowledge distillation and automatic neural network selection, and hopes to bring some inspiration or help to students engaged in related work.

1 Introduction
As we all know, in large-scale industrial applications such as search, recommendation, and advertising, in order to balance performance and effect, the ranking system generally adopts a cascaded architecture.[1,2], as shown in Figure 1 below. Taking the Meituan search and sorting system as an example, the entire sorting is divided into coarse sorting, fine sorting, rearranging and shuffling. Sent to the fine layer.
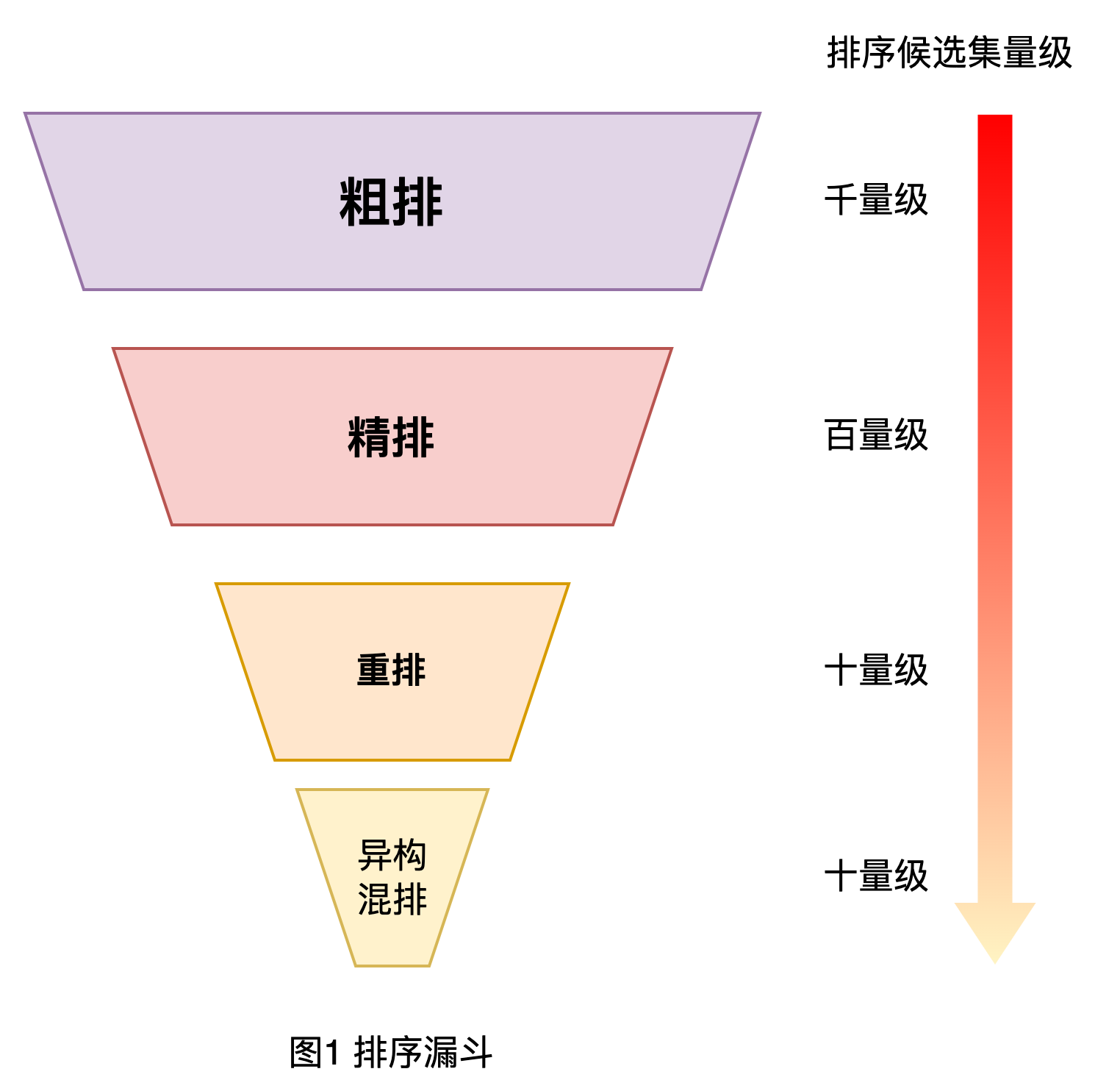
Looking at the coarse ranking module from the perspective of Meituan’s search and ranking full link, the current coarse ranking layer optimization has the following challenges:
- sample selection bias: Under the cascade sorting system, the rough sorting is far from the final result display link, resulting in a large difference between the offline training sample space of the rough sorting model and the sample space to be predicted, and there is a serious sample selection bias.
- Coarse row and fine row linkage: Coarse sorting is between recall and fine sorting. Coarse sorting requires more information to obtain and utilize subsequent links to improve the effect.
- performance constraints: The candidate set of online coarse ranking prediction is much higher than that of the fine ranking model. However, the actual entire search system has strict performance requirements, resulting in the coarse ranking need to focus on the prediction performance.
This article will focus on the above challenges to share the relevant exploration and practice of the optimization of the rough ranking layer of Meituan search. Among them, we will solve the problem of sample selection bias in the linkage problem of fine ranking. This article is mainly divided into three parts: the first part will briefly introduce the evolution route of the rough ranking layer of Meituan search and sorting; the second part will introduce the relevant exploration and practice of rough ranking optimization. The combination of row and rough row to optimize the effect of rough row, the second work is to consider the performance of rough row and the effect of trade-off rough row optimization, all related work has been launched in full, and the effect is remarkable; the last part is the summary and outlook, I hope these The content is helpful and inspiring for everyone.
2. Rough rehearsal of the evolution route
The evolution of the rough sorting technology of Meituan Search is divided into the following stages:
- 2016: Linear weighting based on information such as relevance, quality, conversion rate, etc. This method is simple but the feature expression ability is weak, the weight is manually determined, and there is a lot of room for improvement in the sorting effect.
- 2017: Using a simple LR model based on machine learning for Pointwise Predictive Ranking.
- 2018: Adopt the double-tower model based on vector inner product, input query words, user and context features and merchant features respectively on both sides, after deep network calculation, output user & query word vector and merchant vector respectively, and then pass the inner product Calculate the estimated scores for sorting. This method can save the business vector calculation in advance, so the online prediction is fast, but the crossover ability of the information on both sides is limited.
- 2019: In order to solve the problem that the twin-tower model cannot model cross-features well, the output of the twin-tower model is used as a feature to fuse with other cross-features through the GBDT tree model.
- 2020 to present: Due to the improvement of computing power, began to explore the NN end-to-end coarse sorting model and continue to iterate the NN model.
At this stage, the two-tower model is commonly used in the rough row model in the industry, such as Tencent[3]and iQiyi[4]; Interactive NN models such as Alibaba[1,2]. The following mainly introduces the relevant optimization work of Meituan Search in the process of upgrading from coarse ranking to NN model, mainly including two parts: coarse ranking effect optimization and effect & performance joint optimization.
3. Rough row optimization practice
With a lot of effect optimization work[5,6]After the implementation of the fine-ranked NN model in Meituan Search, we also began to explore the optimization of the coarse-ranked NN model. Considering that rough sorting has strict performance constraints, it is not applicable to directly reuse the work of fine sorting optimization to rough sorting. The following will introduce the optimization of the fine-arrangement linkage effect of migrating the sorting ability of the fine-arrangement to the coarse-arrangement, and the effect and performance trade-off optimization of the automatic search based on the neural network structure.
3.1 Optimization of fine-arrangement linkage effect
The rough sorting model is limited by the scoring performance constraints, which will lead to a simpler model structure than the fine sorting model, and the number of features is much less than that of the fine sorting, so the sorting effect is worse than that of the fine sorting.In order to make up for the loss of effect caused by the simple structure and fewer features of the coarse row model, we try the knowledge distillation method.[7]To link the fine row to optimize the rough row.
Knowledge distillation is a common method in the industry to simplify the model structure and minimize the effect loss. It adopts a Teacher-Student paradigm: the model with complex structure and strong learning ability is used as the Teacher model, and the model with simpler structure is used as the Student model. To assist the training of the Student model, so as to transfer the “knowledge” of the Teacher model to the Student model to improve the effect of the Student model. Figure 2 shows the schematic diagram of the refined row distillation and the rough row. The following will introduce the practical experience of these distillation schemes in the rough ranking of Meituan search.
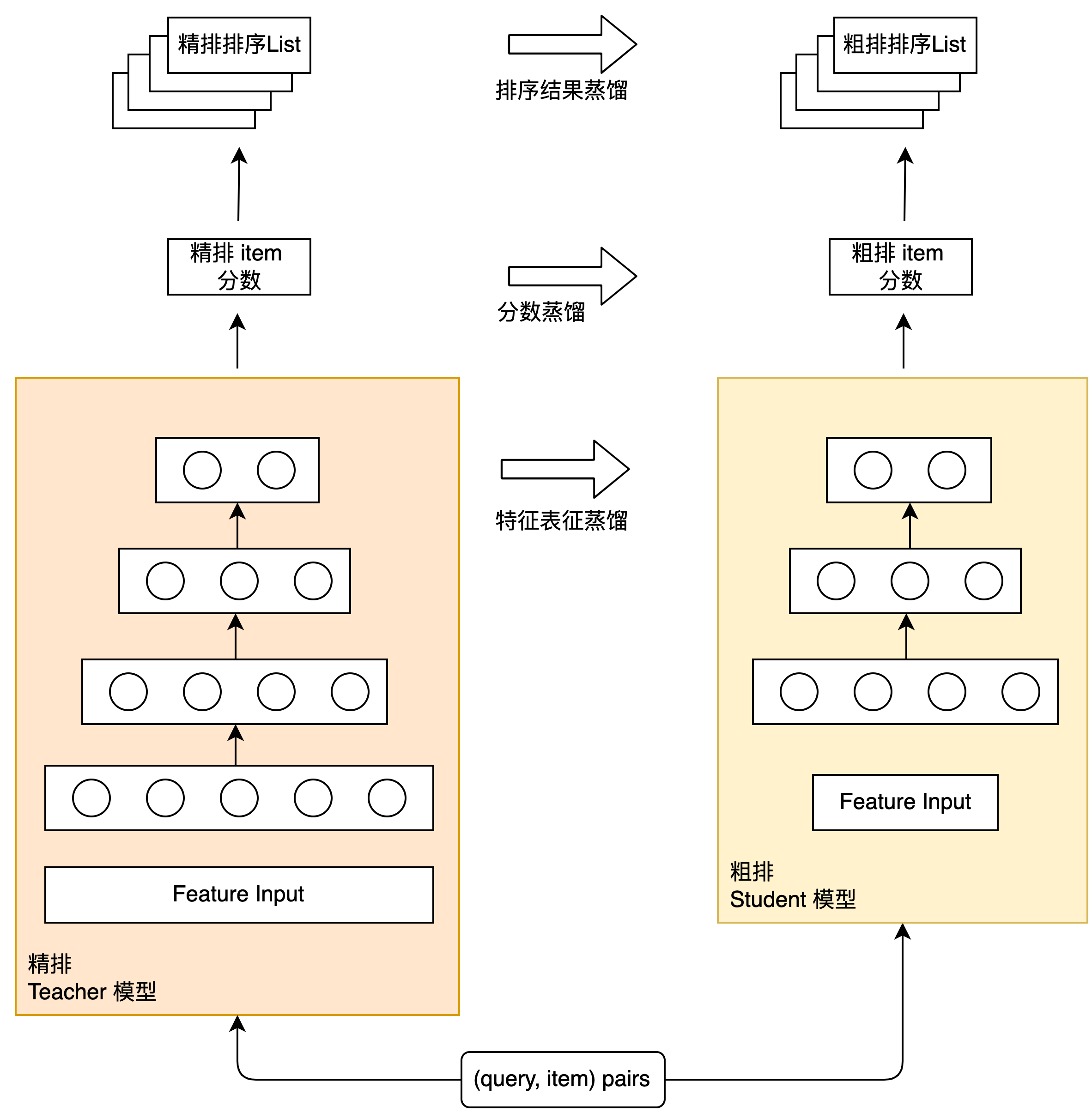
3.1.1 Refinement result list distillation
Rough sorting is the pre-module for fine sorting. Its goal is to initially screen out candidate sets with better quality for fine sorting. From the selection of training samples, except for items with regular user behaviors (click, order, payment) As positive samples, in addition to exposing items that do not behave as negative samples, you can also introduce some positive and negative samples constructed from the sorting results of the fine sorting model, which can not only alleviate the sample selection bias of the rough sorting model to a certain extent, but also reduce the fine sorting The sorting ability of the row is migrated to the coarse row. The following will introduce the practical experience of using the fine sorting results to distill the rough sorting model in the Meituan search scenario.
Strategy 1: On the basis of the positive and negative samples fed back by the user, a small number of unexposed samples with the back of the fine sorting and sorting are randomly selected as supplements for the coarse sorting and negative samples, as shown in Figure 3. For this change, offline Recall@150 (see appendix for indicator explanation) +5PP, online CTR +0.1%.

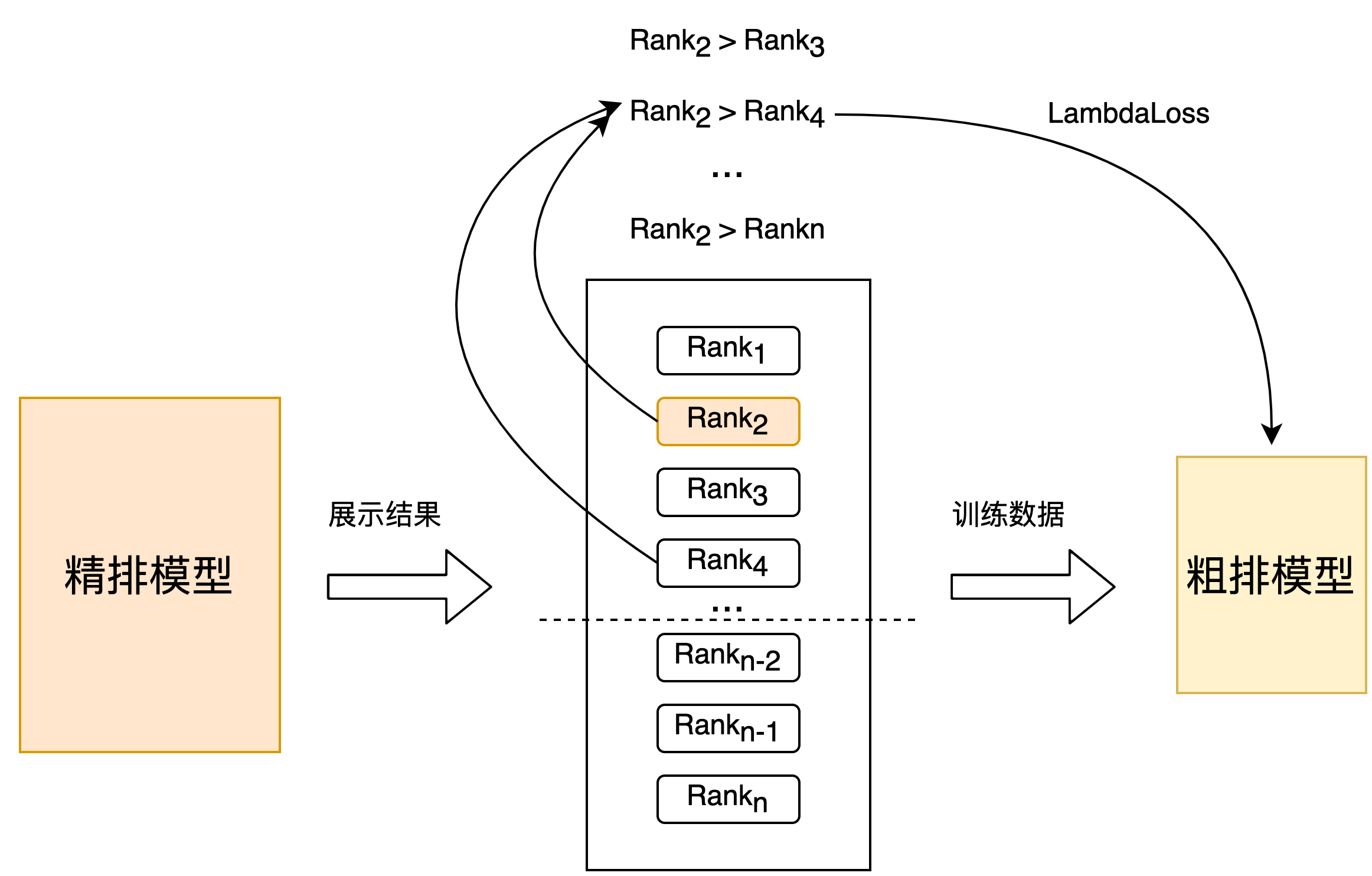
Strategy 2: Random sampling is performed directly in the fine-sorted set to obtain training samples, and the fine-sorted position is used as a label to construct a pair for training, as shown in Figure 4 below. Compared with strategy 1 Recall@150 +2PP offline effect, online CTR +0.06%.
Strategy 3: Based on the sample set selection of strategy 2, the label is constructed by binning the precise sorting position, and then the pair is constructed according to the binning label for training. Compared with strategy 2 Recall@150 +3PP offline effect, online CTR +0.1%.
3.1.2 Refinement Prediction Fractional Distillation
The previous use of sorting results distillation is a relatively rough way of using refined sorting information. We further add prediction score distillation on this basis.[8]it is hoped that the scores output by the coarse ranking model and the score distribution output by the fine ranking model are as aligned as possible, as shown in Figure 5 below:
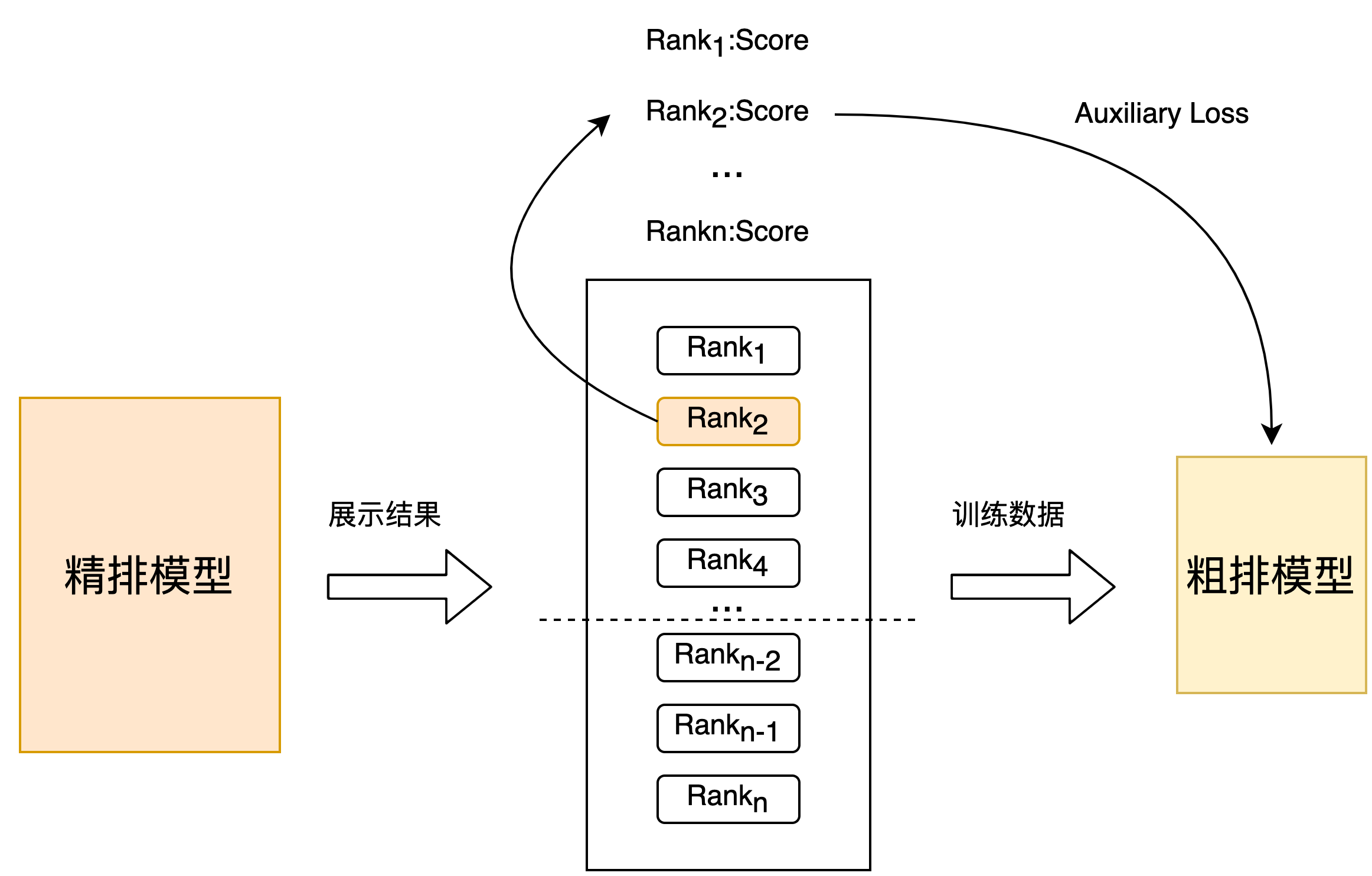
In the specific implementation, we use a two-stage distillation paradigm to distill the coarse sorting model based on the pre-trained fine sorting model. The distillation Loss uses the minimum square error of the output of the coarse sorting model and the output of the fine sorting model, and adds a parameter Lambda to control the effect of distillation Loss on the final Loss, as shown in formula (1). Using the method of fractional distillation, offline effect Recall@150 +5PP, online effect CTR +0.05%.
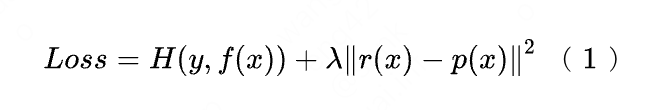
3.1.3 Feature Representation Distillation
The industry’s realization of fine-arrangement-guided coarse-arrangement representation modeling through knowledge distillation has been verified as an effective way to improve the model effect[7]however, the traditional method of distillation has the following defects: First, the sorting relationship between coarse sorting and fine sorting cannot be distilled. As mentioned above, the sorting results are distilled in our scenario, both offline and online. Effectively improve; the second is the traditional knowledge distillation scheme that uses KL divergence as a representation measure, treats each dimension of representation independently, and cannot effectively distill highly related and structured information[9]and in the Meituan search scenario, the data is highly structured, so the traditional knowledge distillation strategy for representation distillation may not be able to capture this structured knowledge well.

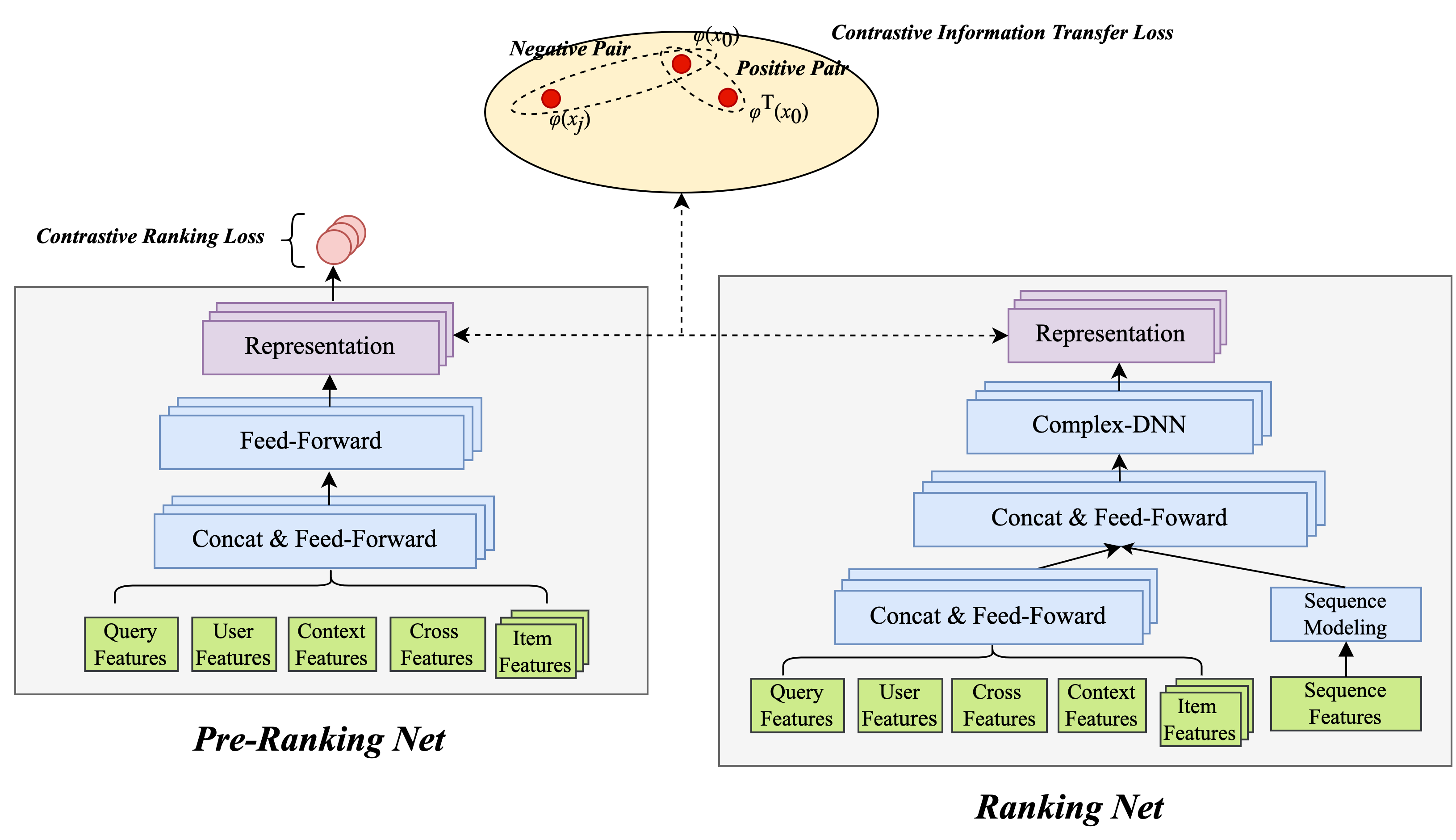
On the basis of the above formula (1), supplementary comparative learning to represent distillation Loss, offline effect Recall@150 +14PP, online CTR +0.15%.Details of related work can be found in our paper[10](in progress).
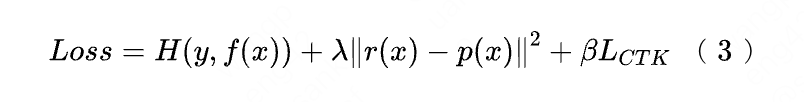
3.2 Joint optimization of effect performance
As mentioned above, the candidate set of coarse ranking for online prediction is relatively large. Considering the constraints of the whole link performance of the system, the coarse ranking needs to consider the prediction efficiency. The work mentioned above is optimized based on the paradigm of simple DNN + distillation, but there are the following two problems:
- Currently limited by online performance, only simple features are used, and richer cross-features are not introduced, resulting in further improvement of the model effect.
- Distillation with a fixed coarse-row model structure loses the distillation effect, resulting in a suboptimal solution[11].
According to our practical experience, it is not enough to directly introduce cross features in the coarse row layer to meet the online delay requirements. Therefore, in order to solve the above problems, we have explored and practiced a coarse-ranking modeling scheme based on neural network architecture search, which simultaneously optimizes the effect and performance of the coarse-ranking model, and selects the best feature combination and model that meets the coarse-ranking delay requirements. The structure, the overall architecture diagram is shown in Figure 7 below:

Below we briefly introduce the two key technical points of neural network architecture search (NAS) and introduction efficiency modeling:

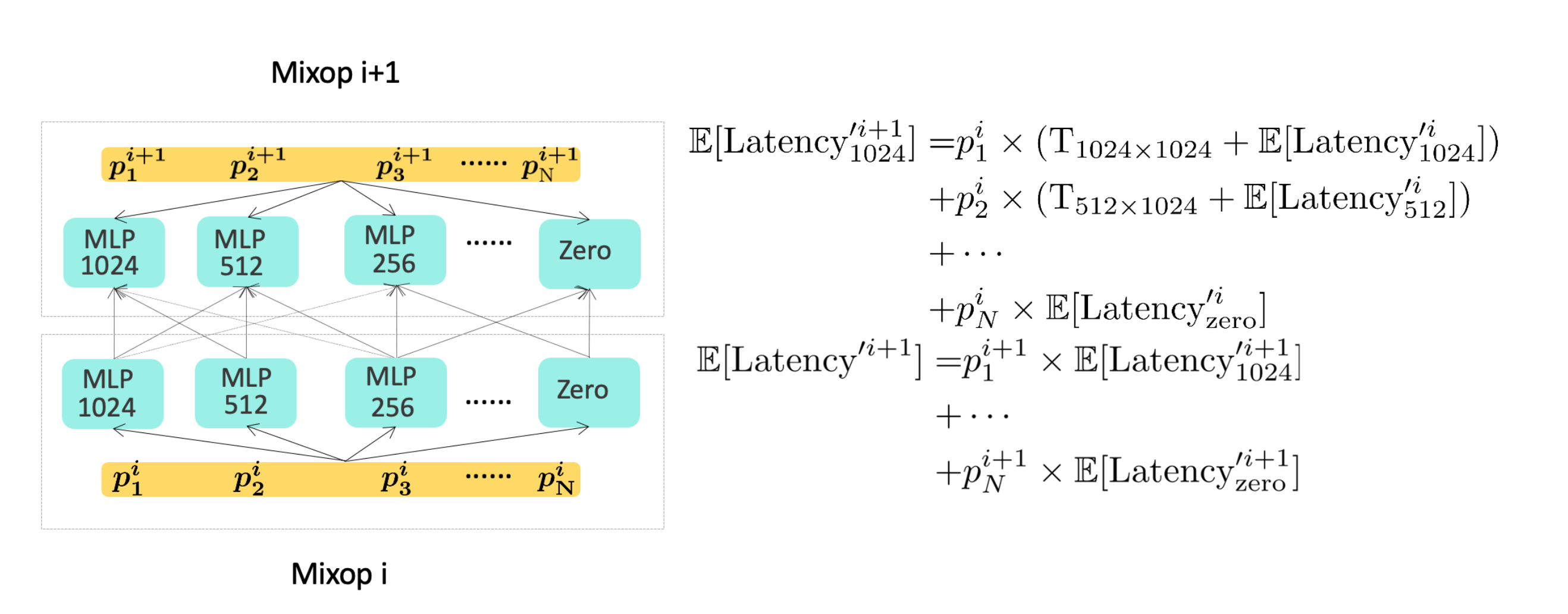


Through the modeling of neural network architecture search to jointly optimize the effect and prediction performance of the rough ranking model, offline Recall@150 +11PP, and the online index CTR +0.12% without increasing the final online delay; for details, please refer to[13]accepted by KDD 2022.
4. Summary
Beginning in 2020, we have implemented a large number of engineering performance optimizations to implement the MLP model of the rough sorting layer. In 2021, we will continue to iterate the rough sorting model based on the MLP model to improve the rough sorting effect. First of all, we draw on the distillation scheme commonly used in the industry to link fine sorting to optimize rough sorting, and conduct a large number of experiments from three levels of fine sorting result distillation, fine sorting predicted fractional distillation, and feature representation distillation, without increasing the online delay. Next, improve the effect of rough row model.
Secondly, considering that the traditional distillation method cannot handle the feature structure information in the sorting scene well, we have developed a set of fine-arrangement information transfer and coarse-arrangement scheme based on contrastive learning.
Finally, we further consider that the rough ranking optimization is essentially a trade-off of effect and performance, adopt the idea of multi-objective modeling to optimize the effect and performance at the same time, and implement the automatic search technology of neural network architecture to solve the problem, so that the model can automatically select efficiency and performance. The best-performing feature set and model structure. In the future, we will continue to iterate the coarse layer technology from the following aspects:
- Coarse row multi-objective modeling: The current rough sorting is essentially a single-objective model, and we are currently trying to apply the multi-objective modeling of the fine sorting layer to the rough sorting.
- System-wide dynamic computing power distribution with coarse row linkage: Coarse ranking can control the computing power of recall and the computing power of fine ranking. For different scenarios, the computing power required by the model is different. Therefore, dynamic computing power allocation can reduce the computing power of the system without reducing the online effect. consumption, we have already achieved certain online effects in this regard.
5. Appendix
The traditional offline ranking indicators are mostly based on NDCG, MAP, and AUC indicators. For coarse ranking, its essence is more inclined to recall tasks targeting set selection. Therefore, traditional ranking indicators are not conducive to measuring the iteration of the coarse ranking model. The effect is good or bad.we learn from[6]The Recall indicator in the middle is used as a measure of the offline effect of rough sorting, that is, taking the fine sorting result as the ground truth, to measure the alignment degree of the rough sorting and fine sorting results TopK. The specific definition of the Recall indicator is as follows:

The physical meaning of this formula is to measure the coincidence of the top K in the rough sorting and the K in the fine sorting, which is more in line with the essence of the coarse sorting set selection.
6. About the author
Xiao Jiang, Suo Gui, Li Xiang, Cao Yue, Pei Hao, Xiao Yao, Da Yao, Chen Sheng, Yun Sen, Li Qian, etc. are all from the Meituan Platform/Search Recommendation Algorithm Department.
7. References
- [1] Wang Z, Zhao L, Jiang B, et al. Cold: Towards the next generation of pre-ranking system[J]. arXiv preprint arXiv:2007.16122, 2020.
- [2] Ma X, Wang P, Zhao H, et al. Towards a Better Tradeoff between Effectiveness and Efficiency in Pre-Ranking: A Learnable Feature Selection based Approach[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021: 2036-2040.
- [3] https://mp.weixin.qq.com/s/Jfuc6x-Qt0rya5dbCR2uCA
- [4] https://mp.weixin.qq.com/s/RwWuZBSaoVXVmZpnyg7FHg
- [5] https://tech.meituan.com/2020/04/16/transformer-in-meituan.html.
- [6] https://tech.meituan.com/2021/07/08/multi-business-modeling.html.
- [7] Tang, Jiaxi, and Ke Wang. “Ranking distillation: Learning compact ranking models with high performance for recommender system.” Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
- [8] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015).
- [9] Chen L, Wang D, Gan Z, et al. Wasserstein contrastive representation distillation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 16296-16305.
- [10] https://arxiv.org/abs/2207.03073
- [11] Liu Y, Jia X, Tan M, et al. Search to distill: Pearls are everywhere but not the eyes[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 7539-7548.
- [12] Cai H, Zhu L, Han S. Proxylessnas: Direct neural architecture search on target task and hardware[J]. arXiv preprint arXiv:1812.00332, 2018.
- [13] https://arxiv.org/abs/2205.09394
Job Offers
The Search Recommendation Algorithm Department/Basic Algorithm Group is the core team responsible for the research and development of Meituan. Its mission is to build a world-class search engine, relying on Deep Learning (deep learning), NLP (natural language processing), Knowledge Graph (knowledge graph) and other technologies , process the massive user, merchant, and commodity data of Meituan, continuously deepen the understanding of users, scenarios, queries and services, efficiently support various forms of life service searches, and solve the multi-service mix, relevance, and personalization of search results. and other issues, to give users the ultimate search experience. The Search and Recommendation Algorithm Department has been recruiting search and recommendation algorithm experts for a long time. Interested students can send their resumes to: tech@meituan.com (mail subject: Meituan Platform/Search and Recommendation Algorithm Department).
Read more collections of technical articles from the Meituan technical team
Frontend | Algorithm | Backend | Data | Security | O&M | iOS | Android | Testing
| Reply to keywords such as[2021 stock][2020 stock][2019stock][2018 stock]and[2017 stock]in the menu bar of the official account, and you can view the collection of technical articles by the Meituan technical team over the years.

| This article is produced by Meituan technical team, and the copyright belongs to Meituan. Welcome to reprint or use the content of this article for non-commercial purposes such as sharing and communication, please indicate “The content is reproduced from the Meituan technical team”. This article may not be reproduced or used commercially without permission. For any commercial activities, please send an email to tech@meituan.com to apply for authorization.
#Exploration #Practice #Meituan #Search #Rough #Ranking #Optimization #Personal #Space #Meituan #Technical #Team #News Fast Delivery